.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

6 MEI 2025
Leestijd 6 min
Tom De Wolf

Apache Kafka is een zeer flexibel streamingplatform. Het richt zich op schaalbare, realtime gegevenspijplijnen die persistent en zeer performant zijn. Maar hoe werkt het en waarvoor gebruik je het?
Lange tijd werden applicaties gebouwd met behulp van een database waarin 'dingen' werden opgeslagen. Die dingen kunnen een bestelling zijn, een persoon, een auto ... en de database slaat ze op met een bepaalde status.

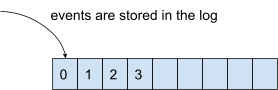
In tegenstelling tot deze aanpak, denkt Kafka niet in termen van 'dingen' maar in termen van 'gebeurtenissen'. Een gebeurtenis heeft ook een toestand, maar het is iets dat in een bepaalde tijd is gebeurd. Het is echter een beetje omslachtig om gebeurtenissen in een database op te slaan. Daarom gebruikt Kafka een log: een geordende opeenvolging van gebeurtenissen die ook duurzaam is.
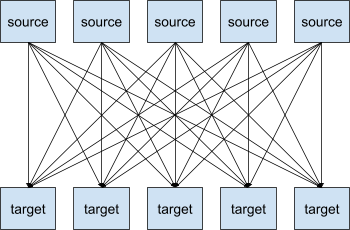
Als je een systeem hebt met verschillende bronsystemen en doelsystemen, dan wil je die met elkaar integreren. Deze integraties kunnen vervelend zijn omdat ze hun eigen protocollen, verschillende gegevensformaten, verschillende gegevensstructuren, enz. hebben.
Dus binnen een systeem met 5 bron- en 5 doelsystemen zul je waarschijnlijk 25 integraties moeten schrijven. Dat kan heel snel heel ingewikkeld worden.
En dit is waar Kafka om de hoek komt kijken. Met Kafka ziet het bovenstaande integratieschema er als volgt uit:
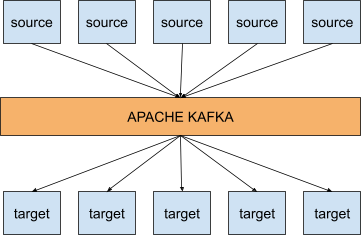
Wat betekent dat? Het betekent dat Kafka je helpt om je gegevensstromen te ontkoppelen. Bronsystemen hoeven alleen hun gebeurtenissen naar Kafka te publiceren en doelsystemen consumeren de gebeurtenissen uit Kafka. Bovenop de ontkoppeling is Apache Kafka ook zeer schaalbaar, heeft het een veerkrachtige architectuur, is het fouttolerant, is het gedistribueerd en is het zeer performant.
Een topic is een bepaalde gegevensstroom en wordt geïdentificeerd door een naam. Topics bestaan uit partities. Elk bericht in een partitie wordt geordend en krijgt een incrementele ID die een offset wordt genoemd. Een offset heeft alleen betekenis binnen een specifieke partitie.
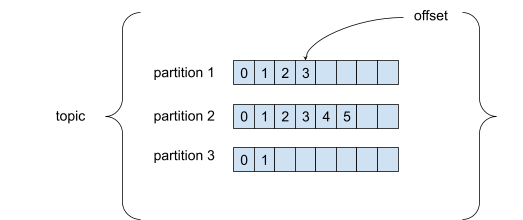
Binnen een partitie is de volgorde van de berichten gegarandeerd. Maar wanneer je een bericht naar een topic stuurt, wordt het willekeurig toegewezen aan een partitie. Dus als je de volgorde van bepaalde berichten wilt behouden, moet je de berichten een sleutel geven. Een bericht met een sleutel wordt altijd toegewezen aan dezelfde partitie.
Berichten zijn ook onveranderlijk. Als je ze wilt wijzigen, moet je een extra 'update-bericht' sturen.
Een Kafka-cluster bestaat uit verschillende brokers. Elke broker krijgt een ID toegewezen en elke broker bevat bepaalde partities. Als je verbinding maakt met een broker in het cluster, ben je automatisch verbonden met het hele cluster.
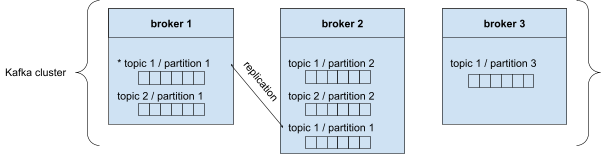
Zoals je in de bovenstaande afbeelding kunt zien, wordt onderwerp 1/partitie 1 gerepliceerd in broker 2. Slechts één broker kan leider zijn voor een onderwerp/partitie. In dit voorbeeld is broker 1 de leider en broker 2 zal automatisch de gerepliceerde topic/partities synchroniseren. Dit noemen we een 'in sync replica' (ISR).
Een producer stuurt de berichten naar het Kafka cluster om ze naar een specifiek onderwerp te schrijven. Daarom moet de producer de topicnaam en één broker kennen. We hebben al vastgesteld dat je automatisch verbinding maakt met het hele cluster als je verbinding maakt met een broker. Kafka zorgt voor de routering naar de juiste broker.
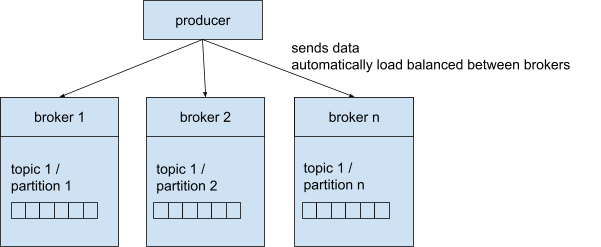
Een producer kan geconfigureerd worden om een bevestiging (ACK) te krijgen van het schrijven van data:
ACK=0: producer wacht niet op bevestiging
ACK=1: de producent wacht op de bevestiging van de leidende broker
ACK=ALL: de producent wacht op de bevestiging van de leidende broker en de replicabroker.
Het is duidelijk dat een hogere ACK veel veiliger is en garandeert dat er geen gegevens verloren gaan. Aan de andere kant is het minder performant.
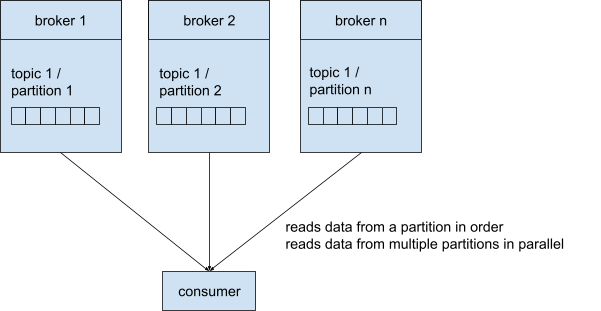
Een consumer leest data van een topic. Daarom moet de consument de naam van het onderwerp en één broker kennen. Net als bij de producenten geldt dat wanneer je verbinding maakt met één broker, je verbonden bent met het hele cluster. Ook hier zorgt Kafka voor de routering naar de juiste broker.
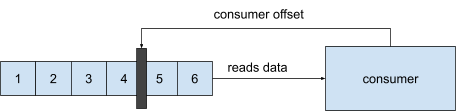
Consumenten lezen de berichten van een partitie in volgorde, rekening houdend met de offset. Als consumenten van meerdere partities lezen, lezen ze deze parallel.
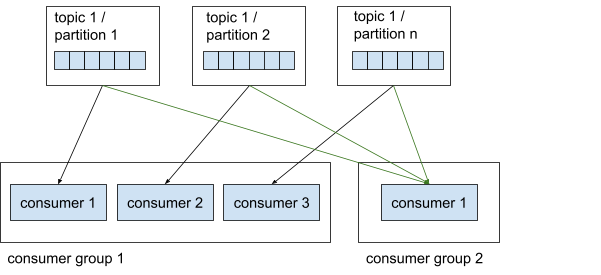
Consumenten zijn georganiseerd in groepen, oftewel consumentengroepen. Deze groepen zijn nuttig om parallellisme te verbeteren. Binnen een consumentengroep leest elke consument van een exclusieve partitie. Dit betekent dat in consumentengroep 1 zowel consument 1 als consument 2 niet van dezelfde partitie kunnen lezen. Een consumentengroep kan ook niet meer consumenten dan partities hebben, omdat sommige consumenten geen partitie hebben om van te lezen.
Als een consumer een bericht van de partitie leest, legt hij elke keer de offset vast. In het geval dat een consumer dood gaat of netwerkproblemen heeft, weet de consumer waar hij verder moet als hij weer online is.
Er zijn enkele verschillen tussen Kafka en een message queue. Enkele belangrijke verschillen zijn dat nadat een consument van een berichtwachtrij een bericht heeft ontvangen, het uit de wachtrij wordt verwijderd, terwijl Kafka de berichten/gebeurtenissen niet verwijdert.
Hierdoor kun je meerdere consumenten op een onderwerp hebben die dezelfde berichten kunnen lezen, maar er verschillende logica op uitvoeren. Omdat de berichten persistent zijn, kun je ze ook opnieuw afspelen. Wanneer je meerdere consumenten op een berichtwachtrij hebt, passen ze over het algemeen dezelfde logica toe op de berichten en zijn ze alleen nuttig om de belasting af te handelen.
Er zijn veel gebruikssituaties voor Kafka. Laten we enkele voorbeelden bekijken.
Wanneer je iets bestelt op een webshop, krijg je waarschijnlijk een melding van de koeriersdienst met een trackinglink. In sommige gevallen kun je de chauffeur zelfs in real-time volgen op een kaart. Dit is waar Kafka om de hoek komt kijken: de bestelbus van de koerier heeft een ingebouwde GPS die zijn coördinaten regelmatig naar een Kafka-cluster stuurt. De website die je bekijkt, luistert naar die gebeurtenissen en toont je in realtime de exacte positie van de koerier op een kaart.
Kafka kan worden gebruikt voor het volgen en vastleggen van website-activiteit. Gebeurtenissen zoals paginaweergaves, zoekopdrachten van gebruikers, enz. worden vastgelegd in Kafka topics. Deze gegevens worden vervolgens gebruikt voor een reeks use cases zoals real-time monitoring, real-time verwerking of zelfs het laden van deze gegevens in een data lake voor verdere offline verwerking en rapportage.
Servers kunnen worden bewaakt en ingesteld om alarmen te activeren in geval van systeemfouten. Informatie van servers kan worden gecombineerd met de syslogs van de server en naar een Kafka-cluster worden gestuurd. Via Kafka kunnen deze onderwerpen worden samengevoegd en ingesteld om alarmen te triggeren op basis van gebruiksdrempels, met volledige informatie voor het eenvoudiger oplossen van systeemproblemen voordat ze catastrofaal worden.
In deze blogpost hebben we in grote lijnen uitgelegd hoe Apache Kafka werkt en waarvoor dit ongelooflijke platform kan worden gebruikt. We hopen dat je iets nieuws hebt geleerd! Als je nog vragen hebt, laat het ons dan weten. Bedankt voor het lezen!


Bij de ontwikkeling van software kunnen aannames ernstige gevolgen hebben en we moeten altijd op onze hoede zijn. In deze blogpost bespreken we hoe je omgaat met aannames bij het ontwikkelen van software. Stel je voor... je rijdt naar een bepaalde pl
Lees verder

ACA doet veel projecten. In het laatste kwartaal van 2017 deden we een vrij klein project voor een klant in de financiële sector. De deadline voor het project was eind november en onze klant werd eind september ongerust. We hadden er echter alle vert
Lees verder

OutSystems: een katalysator voor bedrijfsinnovatie In het snelle zakelijke landschap van vandaag de dag moeten organisaties innovatieve oplossingen omarmen om voorop te blijven lopen. Er zijn veel strategische technologische trends die cruciale bedri
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
