.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 13 min
Koen Olaerts

In de afgelopen jaren heeft de exponentiële groei van gegevens geleid tot een toenemende vraag naar effectievere manieren om deze te beheren. Het opbouwen van een datagestuurd bedrijf blijft een van de belangrijkste strategische doelen van veel zakelijke belanghebbenden. En hoewel het logisch lijkt voor bedrijven om het idee van datagestuurd zijn te omarmen, is het veel moeilijker om dat idee uit te voeren.
Data Mesh en Data Lakes zijn twee belangrijke concepten in de wereld van data-architecturen die samen kunnen zorgen voor een flexibele en schaalbare aanpak van datamanagement. Data Lakes hebben al bewezen een populaire oplossing te zijn, maar een nieuwere aanpak, Data Mesh, krijgt steeds meer aandacht. In deze blog duiken we in de twee concepten en onderzoeken we hoe ze elkaar kunnen aanvullen.

Een data lake is een grote en centrale opslagplaats die enorme hoeveelheden gegevens bevat, uit verschillende bronnen en in verschillende gegevensformaten. Het kan gestructureerde, semigestructureerde en ongestructureerde gegevens opslaan (bijv. afbeeldingen).
Zie het als een enorme plas water, waarin je allerlei soorten gegevens kunt opslaan, zoals klantgegevens, transactiegegevens, social media-feeds, afbeeldingen, video's en nog veel meer. Het is een kosteneffectieve en toegankelijke oplossing voor bedrijven die te maken hebben met grote gegevensvolumes en verschillende gegevensformaten.
Bovendien stellen data lakes teams in staat om met ruwe data te werken, zonder dat uitgebreide voorbewerking of normalisatie nodig is.
Data Mesh is een relatief nieuw concept dat gegevensbeheer decentraal benadert. Het behandelt data als een product en wordt beheerd door autonome teams die verantwoordelijk zijn voor een bepaald domein.
Data Mesh pleit ervoor dat gegevens eigendom zijn van en beheerd worden door de mensen die er het meeste verstand van hebben - de domeinexperts - en behandeld worden als een product. Dit betekent dat elk team verantwoordelijk is voor de kwaliteit, betrouwbaarheid en toegankelijkheid van de gegevens binnen zijn domein.
Dit zorgt voor een meer schaalbare en flexibele benadering van datamanagement, waarbij teams zelfstandig beslissingen kunnen nemen over hun data, zonder dat er interventie nodig is van een gecentraliseerd datateam.
In het kort is Data Mesh een architectuur waarbij data eigendom is van en beheerd wordt door individuele productteams, waardoor een gedecentraliseerde aanpak van datamanagement ontstaat. Een data lake is een technologie die een gecentraliseerde opslagoplossing biedt, waardoor teams grote hoeveelheden gegevens kunnen opslaan en beheren zonder zich zorgen te hoeven maken over de structuur of het formaat van de gegevens.
Decentralisatie in Data Mesh gaat over het nemen van verantwoordelijkheid voor het delen van gegevens als producten op een gedecentraliseerde manier. Het gaat niet om het opgeven van gecentraliseerde opslagoplossingen, zoals Data Lakes, maar om het gebruik ervan op een manier die voldoet aan de principes van Data Mesh.
Data Mesh draait om het definiëren en beheren van Data Producten als een bouwsteen om data eenvoudig toegankelijk en herbruikbaar te maken voor verschillende use cases. Elk "Data Product" moet zijn gegevens op meerdere manieren kunnen aanbieden via verschillende uitvoerpoorten.
Een uitvoerpoort is bedoeld om gegevens direct toegankelijk te maken voor een specifieke use case. Voorbeelden van use cases zijn analyse en rapportage, machine learning, real-time verwerking, enz. Daarom hebben meerdere soorten uitvoerpoorten overeenkomstige gegevenstechnologieën nodig die een specifieke toegangsmodus mogelijk maken.
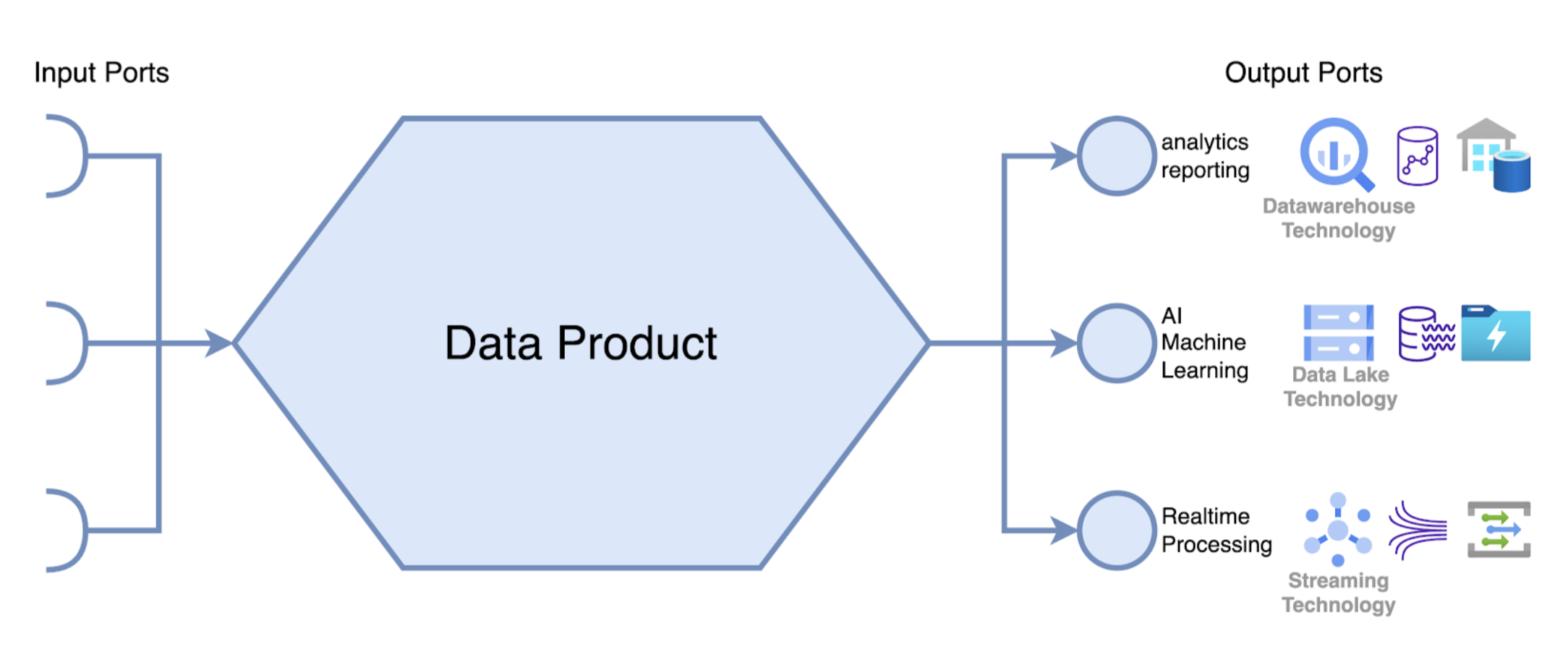
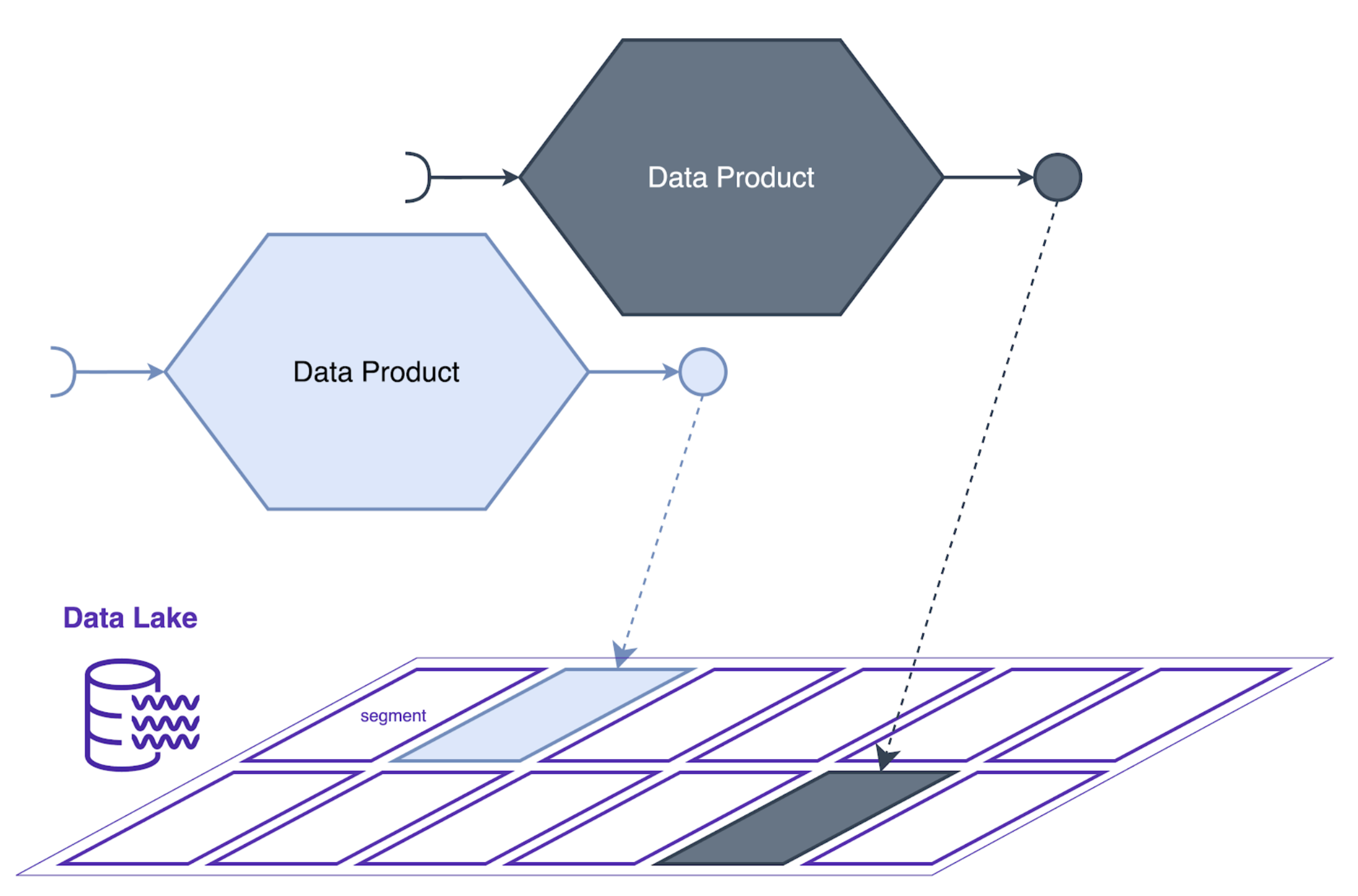
Een technologie die een Data Mesh-architectuur kan ondersteunen is een data lake. De gegevens in een uitvoerpoort voor een gegevensproduct kunnen worden opgeslagen in een data lake. Dit type uitvoerpoort krijgt dan alle voordelen die de data lake-technologie biedt.
In een Data Mesh-architectuur krijgt elk dataproduct zijn eigen segment in het data lake (bijvoorbeeld een S3 Bucket). Dit segment fungeert als uitvoerpoort voor het dataproduct, waar het team dat verantwoordelijk is voor het dataproduct zijn gegevens naar het meer kan schrijven. Door het data lake op deze manier te segmenteren, kunnen teams hun eigen data beheren en beveiligen zonder zich zorgen te maken over conflicten met andere teams. Op deze manier wordt gedecentraliseerd eigenaarschap mogelijk, zelfs als er gebruik wordt gemaakt van een meer gecentraliseerde opslagtechnologie.
Hoewel een data lake een belangrijke technologie is om een Data Mesh architectuur te ondersteunen, is het misschien niet de ideale oplossing voor elke use case. Het gebruik van een data lake als enige type dataopslagtechnologie kan de flexibiliteit van het Data Mesh-platform beperken, omdat het slechts één type opslag biedt. Als het bijvoorbeeld gaat om business intelligence en rapportage, kan een datawarehousetechnologie met tabelvormige opslag geschikter zijn. Een ander voorbeeld is wanneer tijdreeksdatabases of grafiekdatabases een betere optie zijn vanwege het type gegevens dat we direct herbruikbaar willen maken.
Om het Data Mesh-platform flexibeler te maken, moet het de mogelijkheid bieden om verschillende soorten gegevensopslagtechnologie in te pluggen. Elk daarvan is een ander type uitvoerpoort. Op deze manier kan elk gegevensproduct zijn eigen uitvoerpoorten hebben, met verschillende soorten gegevensopslagtechnologieën, gericht op specifieke gebruikspatronen van gegevens.
We hebben gemerkt dat cloudleveranciers vaak aanbevelen om een Data Mesh-oplossing te implementeren met behulp van een van hun bestaande data lake-services. Meestal bestaat hun aanpak uit het definiëren van beveiligingsgrenzen om segmenten binnen deze services te scheiden, die eigendom kunnen zijn van verschillende domeinen om verschillende dataproducten te maken.
De referentiearchitecturen die ze leveren bevatten echter maar één opslagtechnologie, namelijk hun eigen data lake-technologie. Bijgevolg is het resulterende Data Mesh-platform minder aanpasbaar en gebonden aan één enkele technologie. Wat ontbreekt is een expliciete 'Data Product' abstractie die verder gaat dan alleen het afdwingen van beveiligingsgrenzen en die de integratie van verschillende dataopslagtechnologieën en -oplossingen mogelijk maakt.
Datamanagement is een cruciaal onderdeel van elke organisatie. Er zijn verschillende technologieën en benaderingen beschikbaar, zoals data lakes, data warehouses, data vaults, tijdreeksdatabases, grafiekdatabases, enz. Ze hebben allemaal hun unieke sterke punten en beperkingen.
Uiteindelijk biedt een succesvolle Data Mesh-architectuur de flexibiliteit om gegevens te delen en te hergebruiken met de juiste technologie voor de juiste use case. Hoewel een data lake een krachtig hulpmiddel is voor het beheren van ruwe data, is het misschien niet de beste oplossing voor alle soorten datagebruik.
Door verschillende soorten dataopslagtechnologieën te overwegen, kunnen teams de oplossing kiezen die het beste aansluit bij hun specifieke behoeften en hun workflows voor datamanagement optimaliseren. Door dataproducten in een Data Mesh te gebruiken, kunnen teams een flexibele en schaalbare architectuur creëren die zich kan aanpassen aan veranderende behoeften op het gebied van datamanagement.


Maak het concreet voor alle belanghebbenden Data Mesh wordt vaak gezien als iets zeer abstract en theoretisch, waardoor belanghebbenden onzeker zijn over de precieze implicaties en mogelijke oplossingen ervan. Daarom willen we het bij ACA Group zo co
Lees verder

In het steeds veranderende landschap van datamanagement is het investeren in platforms en het navigeren tussen deze platforms een terugkerend thema in veel datastrategieën. Hoe kunnen we ervoor zorgen dat deze investeringen relevant blijven en in de
Lees verder

Je bent misschien wel bekend met de term 'data mesh'. Het is een van die modewoorden over data die al een tijdje de ronde doen. Hoewel data mesh het potentieel heeft om een organisatie in heel wat situaties veel waarde te bieden, moeten we ons niet b
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
