.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 7 min
Patrik Söderström

Effectieve audits zijn essentieel voor naleving van de regelgeving, risicobeheer en het verbeteren van de operationele efficiëntie. Traditionele auditprocessen kunnen echter tijdrovend zijn en bieden vaak slechts beperkte inzichten. Gelukkig biedt kunstmatige intelligentie (AI)een revolutionaire oplossing. Door machine learning (ML)toe te passen , kun je auditprocessen optimaliseren, verborgen risico's en patronen blootleggen en de manier waarop audits worden uitgevoerd transformeren. In dit artikel wordt onderzocht hoe AI kan helpen om de audits van je organisatie efficiënter en veiliger te maken.
Auditgegevens hebben vaak een onbenut potentieel. Ze bevatten cruciale informatie over de activiteiten en risico's van een organisatie, maar vanwege de omvang en complexiteit is het analyseren van deze gegevens van oudsher een uitdaging. AI maakt het mogelijk om deze gegevens op een dieper niveau te analyseren, waardoor inzichten worden onthuld die anders verborgen zouden blijven. Hierdoor kunnen audits verschuiven van een noodzakelijke taak naar een strategische kans voor groei en betere besluitvorming.
AI opent nieuwe mogelijkheden voor audits door geavanceerde gegevensanalyse te combineren met automatisering. Hier zijn enkele manieren waarop AI waarde toevoegt aan het auditproces:
Door repetitieve, tijdrovende taken te automatiseren, stelt AI auditors in staat zich te richten op strategische activiteiten. Dit bespaart tijd, verhoogt de productiviteit en verlaagt de auditkosten.
AI- en ML-technieken kunnen enorme hoeveelheden gegevens analyseren met een precisie die voor mensen moeilijk te evenaren is. Dit leidt tot nauwkeurigere en betrouwbaardere auditresultaten.
AI kan snel afwijkingen in gegevens identificeren met behulp van technieken zoals outlier detection, waardoor fraude of risico's in een vroeg stadium worden ontdekt, zodat je ze kunt aanpakken voordat ze escaleren.
AI controleert voortdurend de naleving van regelgeving, draagt bij aan robuust risicomanagement en verlaagt de kans op boetes of juridische problemen.
AI biedt met technieken als clustering en Natural Language Processing (NLP) diepere inzichten in complexe bedrijfsprocessen. Dit helpt bij het identificeren van inefficiënties, risico's en verbeterpunten, wat leidt tot een slimmere en effectievere bedrijfsvoering.
AI-technologieën transformeren de manier waarop audits worden uitgevoerd. Hieronder staan enkele belangrijke AI- en ML-technieken die helpen om audits effectiever te maken:
Clusteringsalgoritmen, zoals K-means, Hierarchical Clustering en DBSCAN, groeperen gegevens in clusters op basis van overeenkomsten. K-means bijvoorbeeld groepeert gegevenspunten op basis van hun nabijheid tot een centraal punt (centroïde), waarbij de dichtstbijzijnde punten een cluster vormen.
Bij audits helpt clusteren bij het segmenteren van financiële transacties, klantprofielen of operationele gegevens, waardoor het eenvoudiger wordt om patronen te ontdekken die duiden op risico's of inefficiënties. Zo kun je verdachte groepen transacties detecteren die nader onderzoek vereisen.
Outlier detectie identificeert datapunten die significant afwijken van de rest van de dataset. Deze techniek is cruciaal voor het opsporen van frauduleuze activiteiten, fouten of ongebruikelijke transacties.
Outlier detectie gebruikt statistische methoden, ML modellen zoals Isolation Forest, en technieken zoals Z-score en IQR (Interquartile Range) om deze afwijkingen te detecteren. Door onregelmatige gegevenspunten te markeren, kunnen auditors zich richten op de elementen met het hoogste risico.
NLP stelt computers in staat om tekstgegevens zoals e-mails, contracten en rapporten te begrijpen, te analyseren en te genereren.
NLP-modellen, zoals BERT en GPT, gebruiken technieken zoals tokeniseren, stammen, lemmatiseren en sentimentanalyse om tekst te verwerken en te analyseren.
Dit is ideaal voor het identificeren van relevante informatie en risico's die verborgen zitten in grote hoeveelheden documentatie. NLP kan bijvoorbeeld duizenden e-mails scannen op verdachte zinnen of patronen die duiden op potentiële compliance risico's of frauduleuze activiteiten.
Laten we eens kijken naar een praktijkvoorbeeld. Een internationale financiële dienstverlener besloot zijn auditprocessen te moderniseren met behulp van AI. Traditionele audits waren tijdrovend en misten vaak risico's door de overweldigende hoeveelheid gegevens.
Door AI te integreren kon de organisatie snel risico's identificeren die voorheen onopgemerkt waren gebleven.
Het bedrijf gebruikte een interactieve scatter plot grafiek, aangedreven door clustering, om de risicoscores voor elke audit visueel weer te geven.
Deze visualisatie maakte het gemakkelijk om audits met een hoog risico te herkennen, met kleurverlopen van blauw (laag risico) tot rood (hoog risico).
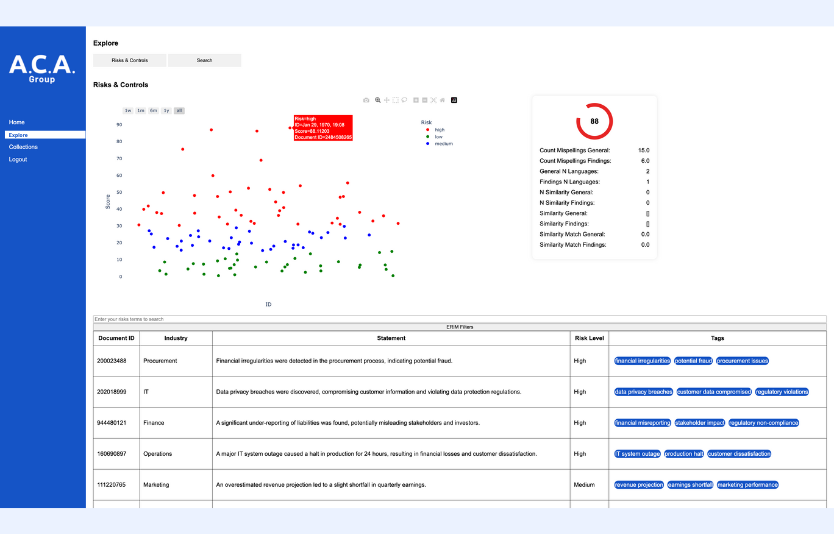
Elk document werd automatisch geanalyseerd en getagd op basis van gemeenschappelijke kenmerken en patronen. Deze door AI gegenereerde tags zorgen voor een gestructureerde en georganiseerde aanpak van documentbeheer, waardoor het bedrijf snel belangrijke informatie kan vinden in een zee van gegevens.
NLP werd gebruikt om tekstgegevens uit contracten en rapporten te analyseren en risicofactoren te extraheren. Hierdoor konden gebruikers snel potentiële risico's identificeren en waardevolle inzichten verkrijgen uit ongestructureerde gegevens.
Door AI-technologieën te integreren in je auditproces kun je niet alleen je audits moderniseren, maar ook je vermogen om risico's te beheren en compliance te garanderen aanzienlijk vergroten. Of het nu gaat om fraudedetectie, compliance monitoring of het verkrijgen van diepere bedrijfsinzichten, AI helpt je om snellere, nauwkeurigere beslissingen te nemen. Auditing is niet langer alleen een vereiste - het wordt een krachtig hulpmiddel voor groei en succes.


Nestelde jouw bedrijf zich al in de zetels van de eerste klasse of heb je je plekje op de AI-trein nog niet gevonden? Onze AI-expert Alexander Frimout legt uit welke processen bij uitstek geschikt zijn voor je eerste AI-businesscase. En vertelt waaro
Lees verder

We moeten het hebben over de "illusie van snelheid" in het tijdperk van AI. In een tijd waarin elke post op LinkedIn lijkt te tonen dat al je concurrenten de overstap maken van traditioneel coderen naar 100% agentische softwareontwikkeling met AI, li
Lees verder

Voor elke externe tool die je met je AI-systeem wilt verbinden, moet je een custom integratie bouwen. Dat brengt twee grote nadelen met zich mee. Eén: het kost veel tijd. Twee: deze manier van werken is niet schaalbaar. Gelukkig kan het Model Context
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
