.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 5 min
Stijn Huygh

De wereld van chatbots en Large Language Models (LLM's) heeft onlangs een spectaculaire evolutie doorgemaakt. Met ChatGPT, ontwikkeld door OpenAI, als een van de meest opmerkelijke voorbeelden, is de technologie erin geslaagd om meer dan 1.000.000 gebruikers te bereiken in slechts vijf dagen. Deze stijging onderstreept de groeiende interesse in conversational AI en de ongekende mogelijkheden die LLM's bieden.
Grote taalmodellen (LLM's) en chatbots zijn concepten die tegenwoordig onmisbaar zijn geworden in de wereld van kunstmatige intelligentie. Ze vertegenwoordigen de toekomst van mens-computerinteractie, waarbij LLM's krachtige AI-modellen zijn die natuurlijke taal begrijpen en genereren, terwijl chatbots programma's zijn die menselijke gesprekken kunnen simuleren en taken kunnen uitvoeren op basis van tekstuele invoer. ChatGPT, een van de opmerkelijke chatbots, heeft in korte tijd enorm aan populariteit gewonnen.
LangChain is een van de frameworks waarmee de kracht van LLM's kan worden benut voor het ontwikkelen en ondersteunen van toepassingen. Deze open-source bibliotheek, geïnitieerd door Harrison Chase, biedt een generieke manier om verschillende LLM's aan te spreken en uit te breiden met nieuwe gegevens en functionaliteiten. LangChain is momenteel beschikbaar in Python en TypeScript/JavaScript en is ontworpen om eenvoudig verbindingen te maken tussen verschillende LLM's en gegevensomgevingen.
Om LangChain volledig te begrijpen, moeten we enkele kernconcepten verkennen:

Het is ook mogelijk om een OutputParser toe te voegen om de uitvoer van het LLM-model te verwerken. Er is bijvoorbeeld een ListOutputParser beschikbaar om de uitvoer van het LLM-model om te zetten in een lijst in de huidige programmeertaal.
Om de LLM Chain toegang te geven tot specifieke gegevens, zoals interne gegevens of klantinformatie, gebruikt LangChain verschillende concepten:

Om de kracht van LangChain te illustreren, kunnen we een demotoepassing maken die de volgende stappen volgt:
Hieronder laten we zien hoe je deze stappen in code uitvoert:
Gelukkig vereist het ophalen van gegevens van een website met LangChain geen handmatig werk. Hieronder lees je hoe we dat doen:
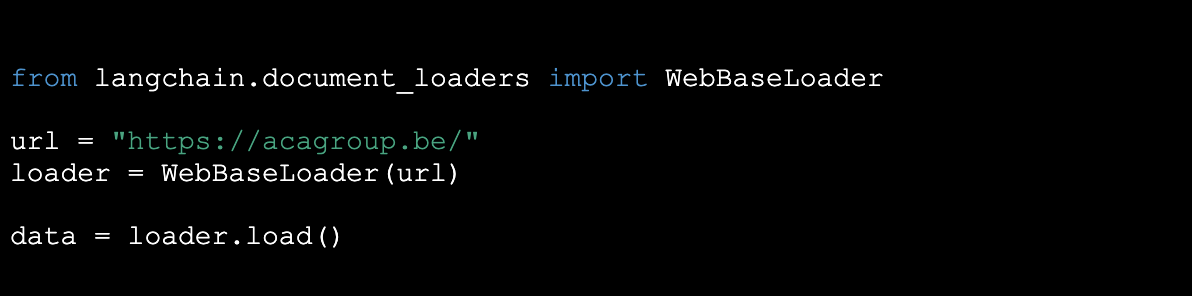
Het dataveld hierboven bevat nu een verzameling pagina's van de website. Deze pagina's bevatten veel informatie, soms te veel voor de LLM om mee te werken, omdat veel LLM's met een beperkt aantal tokens werken. Daarom moeten we de documenten opsplitsen:

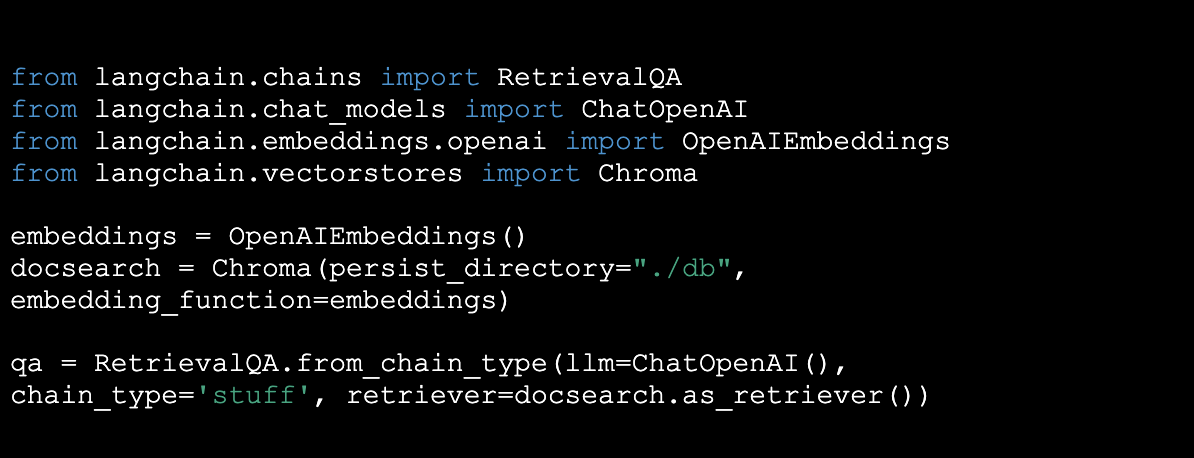
Nu de gegevens zijn opgesplitst in kleinere contextuele fragmenten, slaan we ze op in een vectordatabase om de LLM efficiënt toegang te geven tot deze gegevens. In dit voorbeeld gebruiken we Chroma:

Nu de gegevens zijn opgeslagen, kunnen we een "Chain" bouwen in LangChain. Een keten is simpelweg een reeks LLM-uitvoeringen om het gewenste resultaat te bereiken. Voor dit voorbeeld gebruiken we de bestaande RetrievalQA-keten die LangChain biedt. Deze keten haalt relevante contextfragmenten op uit de nieuw gebouwde database, verwerkt deze samen met de vraag in een LLM en levert het gewenste antwoord:
Nu we de LLM toegang hebben gegeven tot de gegevens, moeten we de gebruiker een manier bieden om de LLM te raadplegen. Om dit efficiënt te doen, gebruiken we Streamlit:

Naast de standaardketens biedt LangChain ook de mogelijkheid om Agents te maken voor geavanceerdere toepassingen. Agents hebben toegang tot verschillende tools die specifieke functionaliteiten uitvoeren. Deze tools kunnen variëren van een "Google Search" tool tot Wolfram Alpha, een tool voor het oplossen van complexe wiskundige problemen. Hierdoor kunnen Agents geavanceerdere redeneertoepassingen bieden, waarbij ze beslissen welk hulpmiddel ze moeten gebruiken om een vraag te beantwoorden.
Hoewel LangChain een krachtig raamwerk is voor het bouwen van LLM-gestuurde toepassingen, zijn er andere alternatieven beschikbaar. Een populair hulpmiddel is bijvoorbeeld LlamaIndex (voorheen GPT Index), dat zich richt op het verbinden van LLM's met externe gegevens. LangChain daarentegen biedt een completer framework voor het bouwen van applicaties met LLM's, inclusief tools en plugins.
LangChain is een spannend raamwerk dat de deuren opent naar een nieuwe wereld van conversationele AI en applicatieontwikkeling met grote taalmodellen. Met de mogelijkheid om LLM's te koppelen aan verschillende gegevensbronnen en de flexibiliteit om complexe toepassingen te bouwen, belooft LangChain een essentieel hulpmiddel te worden voor ontwikkelaars en bedrijven die willen profiteren van de kracht van LLM's. De toekomst van conversational AI ziet er rooskleurig uit en LangChain speelt een cruciale rol in deze evolutie.


Nestelde jouw bedrijf zich al in de zetels van de eerste klasse of heb je je plekje op de AI-trein nog niet gevonden? Onze AI-expert Alexander Frimout legt uit welke processen bij uitstek geschikt zijn voor je eerste AI-businesscase. En vertelt waaro
Lees verder

We moeten het hebben over de "illusie van snelheid" in het tijdperk van AI. In een tijd waarin elke post op LinkedIn lijkt te tonen dat al je concurrenten de overstap maken van traditioneel coderen naar 100% agentische softwareontwikkeling met AI, li
Lees verder

Voor elke externe tool die je met je AI-systeem wilt verbinden, moet je een custom integratie bouwen. Dat brengt twee grote nadelen met zich mee. Eén: het kost veel tijd. Twee: deze manier van werken is niet schaalbaar. Gelukkig kan het Model Context
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
