.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 4 min
Jurgen Geys.png "Jurgen Geys")

De Global Accessibility Awareness Day vindt elk jaar plaats op de derde donderdag van mei met als doel toegankelijkheid in de kijker te zetten. Voor ACA Group zijn de toegankelijkheid, gebruiksvriendelijkheid en inclusie van technologie al lang een belangrijk aandachtspunt. In deze blog ontdek je enkele van onze projecten waarbij toegankelijkheid hoog op de prioriteitenlijst stond.
De bedoeling van de Global Accessibility Awareness Day (GAAD) is om zoveel mogelijk mensen te laten nadenken en praten over hoe technologie toegankelijk kan worden gemaakt voor mensen met een beperking. Op deze manier wil het initiatief bijdragen aan een meer inclusieve digitale wereld.
Digitale toegankelijkheid betekent dat digitale technologieën, zoals online tools, applicaties en elektronische documenten, zo zijn ontworpen dat ze voor iedereen toegankelijk zijn, ook voor mensen met een beperking. Hierdoor kunnen zij, net als iedereen, blijven deelnemen aan de digitale economie en samenleving.
Een van de belangrijkste aspecten van toegankelijkheid is dat mensen met een visuele, auditieve, cognitieve of fysieke beperking digitale content effectief kunnen waarnemen, begrijpen, ermee kunnen navigeren en ermee kunnen interageren.
"Ons duurzaamheidsbeleid is veel meer dan onze sponsoring van goede doelen," zegt Dorien Jorissen, Chief Digital Officer & Sustainability Manager bij ACA Group. "We streven ernaar om alle aspecten van duurzaamheid te analyseren en te integreren in onze activiteiten. Toegankelijkheid is ook een integraal onderdeel van ons duurzaamheidsbeleid."
De SDG's (Sustainable Development Goals) van de Verenigde Naties vormen de basis van het duurzaamheidskader van ACA Group. "Dit willen we niet alleen uitdragen in onze kantoren, in ons team en bij onze stakeholders, maar ook in onze digitale dienstverlening en onze projectmethodiek", zegt Dorien.
"In een snel evoluerende wereld, waarin technologie steeds meer verweven raakt met ons dagelijks leven, zijn we als toonaangevend IT-bedrijf verplicht om digitale toegankelijkheid hoog op de agenda te houden."
Hieronder een foto van ACA Group die de DataNews Award 2022 voor Most Environmentally Responsible ICT Company of the Year'👇🏻 wint.

Hieronder vind je drie projecten van ACA Group waarvoor toegankelijkheid een belangrijke ontwerpeis was.
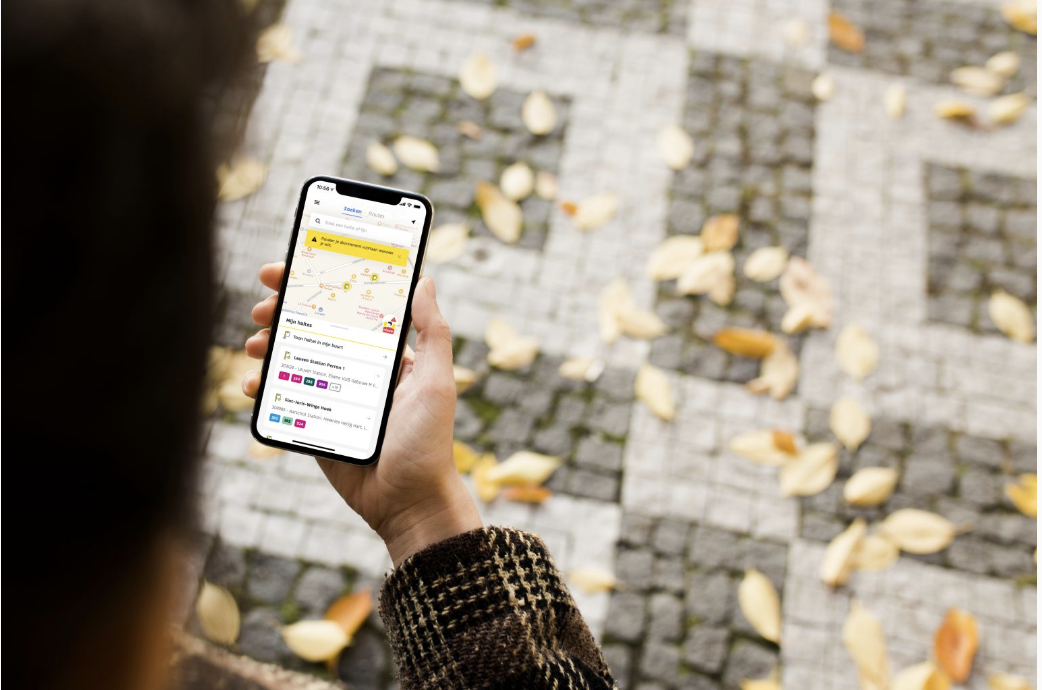
Toegankelijkheid is heel belangrijk voor De Lijn. Niet alleen in termen van gemakkelijke toegang tot hun voertuigen, maar ook in termen van hun digitale toepassingen, zoals de mobiele app.
De vervoersmaatschappij wil dat hun app toegankelijk en gebruiksvriendelijk is voor iedereen, ook voor mensen met een visuele beperking. Zij zijn vaak afhankelijk van het openbaar vervoer en moeten de app daarom gemakkelijk kunnen gebruiken.
"In het verleden konden mensen met een visuele beperking gebruikmaken van een aparte app die routes en realtime informatie beter kon voorlezen", zegt Joren Vos, Mobile Solution Engineer bij ACA Group. "Deze app was echter verouderd. Daarnaast was ook de algemene app van De Lijn aan een update toe."
Er was dus nood aan een update van zowel de gewone De Lijn app als de BLS app. Daarom werd besloten om de BLS-app en de algemene De Lijn-app te integreren in één gebruiksvriendelijke app voor iedereen.
"In het nieuwe ontwerp van de app hebben we ons gefocust op eenvoudige en gebruiksvriendelijke navigatie," legt Joren uit. "We vervingen de oude complexe navigatiestructuur door een gebruiksvriendelijke navigatiebalk onderaan het scherm. We realiseerden ook een duidelijke context bij het lezen vanaf het scherm, de ondersteuning van grotere tekstgroottes en een voice-over."
"We hebben ook de realtime informatie verbeterd en een filebarometer toegevoegd. Hiermee kan een reiziger zien hoe druk het is op een bepaalde bus of tram."
Dankzij de nieuwe menustructuur maakt de vernieuwde app van De Lijn het voor iedereen veel gemakkelijker om tickets te kopen, openbaar vervoerroutes uit te stippelen en haltes en bestemmingen op te zoeken. Dankzij nieuwe functionaliteiten zoals voice-over, waarschuwingen bij het uitstappen en de ondersteuning van grotere lettergroottes kunnen ook mensen met een visuele beperking de app gemakkelijk gebruiken.
Na een toegankelijkheidsonderzoek door Eleven Ways en het behalen van het vereiste label mag de app van De Lijn zich nu officieel 'toegankelijk' noemen.
In 2020 wilden we de ACA-website een redesign geven. Stijn Schutyser, tegenwoordig UI/UX designer bij ACA Website, was destijds als copywriter en SEO Specialist betrokken bij het project. Hij zegt: "We vinden het belangrijk om onze collega's bij elke fase van zo'n project te betrekken. Daarom hebben we tijdens de voorbereidingsfase intern een eerste voorstel gestuurd. Een van de ACA-collega's stelde voor om vanaf het begin extra aandacht te besteden aan toegankelijkheid voor mensen met een beperking. Aangezien inclusie een belangrijke focus is van ons duurzaamheidsbeleid, zijn we meteen aan de slag gegaan met dit fantastische idee."
"We besloten de website te ontwikkelen volgens de Web Content Accessibility Guidelines," legt Stijn uit. "Het was de eerste keer dat we een website volgens deze internationale standaard zouden ontwikkelen. Dat maakte het een hele uitdaging voor ons technische team: de richtlijnen bestuderen, nagaan hoe we ze het best konden implementeren, de codering, ..."
"Een van de belangrijkste doelen was om de website gebruiksvriendelijk te maken voor mensen die gebruik maken van een screenreader die de tekst op een website voorleest. We hebben er bijvoorbeeld voor gezorgd dat een schermlezer met één druk op de knop direct naar de hoofdinhoud van een pagina springt, zonder de overbodige inhoud in de menubalk voor te lezen, enzovoort."
"Na de ontwikkeling en lancering van de nieuwe website hebben we deze laten testen door Eleven Ways," vertelt Stijn. "Zij gaven ons een aantal werkpunten mee die we moesten aanpakken om aan de richtlijnen te voldoen. Na deze aanpassingen hebben we de site laten auditen door AnySurfer met als doel het AnySurfer-label niveau AA te ontvangen. Dat label bewijst dat je website is getest door AnySurfer en dat hij voldoet aan de WCAG-standaard om te spreken van een toegankelijke website."
Wist je trouwens dat de website van ACA een Lighthouse toegankelijkheidscore van 98 heeft, een bijna perfecte score.
Toegankelijkheid zal ook in de toekomst een belangrijke ontwerpparameter zijn voor onze website.
Toegankelijkheid is niet alleen belangrijk voor websites en apps. "Elk stukje content moet toegankelijk zijn voor iedereen, dus ook PDF-bestanden", zegt Ibn Renders, Lead Branding bij ACA Group. "Daarom zorgen we er bij ACA Group voor dat onze PDF-bestanden worden aangepast voor mensen met een visuele beperking die een schermlezer gebruiken."
Hieronder geeft Ibn drie tips om PDF-bestanden voor iedereen toegankelijk te maken:
Wil je meer weten over toegankelijkheid voor PDF-bestanden? Lees het blogartikel "3 eenvoudige tips om je PDF-bestanden voor iedereen toegankelijk te maken".
In een steeds digitalere wereld moeten we ervoor zorgen dat iedereen, ook mensen met een handicap, toegang blijft houden tot online en offline digitale oplossingen en content.
Als toonaangevend IT-bedrijf willen we samen met ACA Group onze verantwoordelijkheid nemen om toegankelijkheid te integreren in onze diensten, onze methodologie en onze oplossingen. We doen al veel inspanningen om dit te bereiken, maar het blijft een voortdurende inspanning om het nog beter te doen.

Liferay DXP is de afgelopen jaren uitgegroeid tot een veelgebruikt portaalplatform voor het bouwen en beheren van geavanceerde digitale ervaringen. Organisaties gebruiken het voor intranetten, klantportalen, self-service platforms en meer. Hoewel Lif
Lees verder

Op de hoogte blijven van de nieuwste trends en best practices is cruciaal in de snel evoluerende wereld van softwareontwikkeling. Innovatieve benaderingen zoals EventSourcing en CQRS kunnen ontwikkelaars in staat stellen flexibele, schaalbare en veil
Lees verder

Je kunt niet iets ontwerpen of ontwikkelen voor alle 7,9 miljard mensen op deze planeet. Dus als we aan een project beginnen, bepalen we een doelgroep om het te beperken. Van daaruit bouwen we onze functies en ontwerpen op een manier die geschikt lij
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!