.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 7 min
Stijn Schutyser

Bij het bouwen van producten wordt steeds meer erkend dat succes niet alleen te maken heeft met het leveren van functies of het halen van deadlines. In plaats daarvan gaat het om het leveren van echte waarde aan klanten en het bereiken van zakelijke impact. Dit vereist een mentaliteitsverandering van outputgericht naar resultaatgericht denken. In dit artikel onderzoeken we waarom het belangrijker is om uitkomsten prioriteit te geven dan output om succesvolle producten te maken en hoe je deze benadering kunt toepassen in je eigen werk.
In de bedrijfswereld worden de termen resultaat en output vaak door elkaar gebruikt, wat voor enige verwarring zorgt. Het is echter belangrijk om het onderscheid tussen deze twee termen goed te begrijpen. Hoewel ze misschien eenvoudig lijken, laten we ze toch eens definiëren om ervoor te zorgen dat we allemaal op dezelfde golflengte zitten.
Laten we ons eens voorstellen dat je je de laatste tijd uitgeput voelt, dus begin je te trainen in de sportschool om je energieker te voelen. Sommige mensen zouden kunnen zeggen dat het resultaat van je fitnessroutine het aantal uren dat je hebt gesport en de hoeveelheid gewicht die je hebt getild is. Maar het echte resultaat van je routine is veel belangrijker dan dat. Het resultaat is dat je je sterker, zelfverzekerder en gezonder voelt. Het resultaat is de manier waarop je harde werk (de output) zich heeft vertaald in een betere levenskwaliteit en een positiever zelfbeeld. Het resultaat is de manier waarop je probleem werd opgelost door de output.
In een zakelijke context verwijst een resultaat naar de impact die je product heeft op de organisatie en haar klanten en belanghebbenden, terwijl een output verwijst naar de tastbare dingen die je (ontwikkel)team produceert, zoals documenten, software en tests. Focussen op resultaat boven output betekent succes definiëren op basis van het bereiken van een specifiek resultaat en vooruitgang meten op basis van hoe dicht je bij het bereiken van dat resultaat bent.
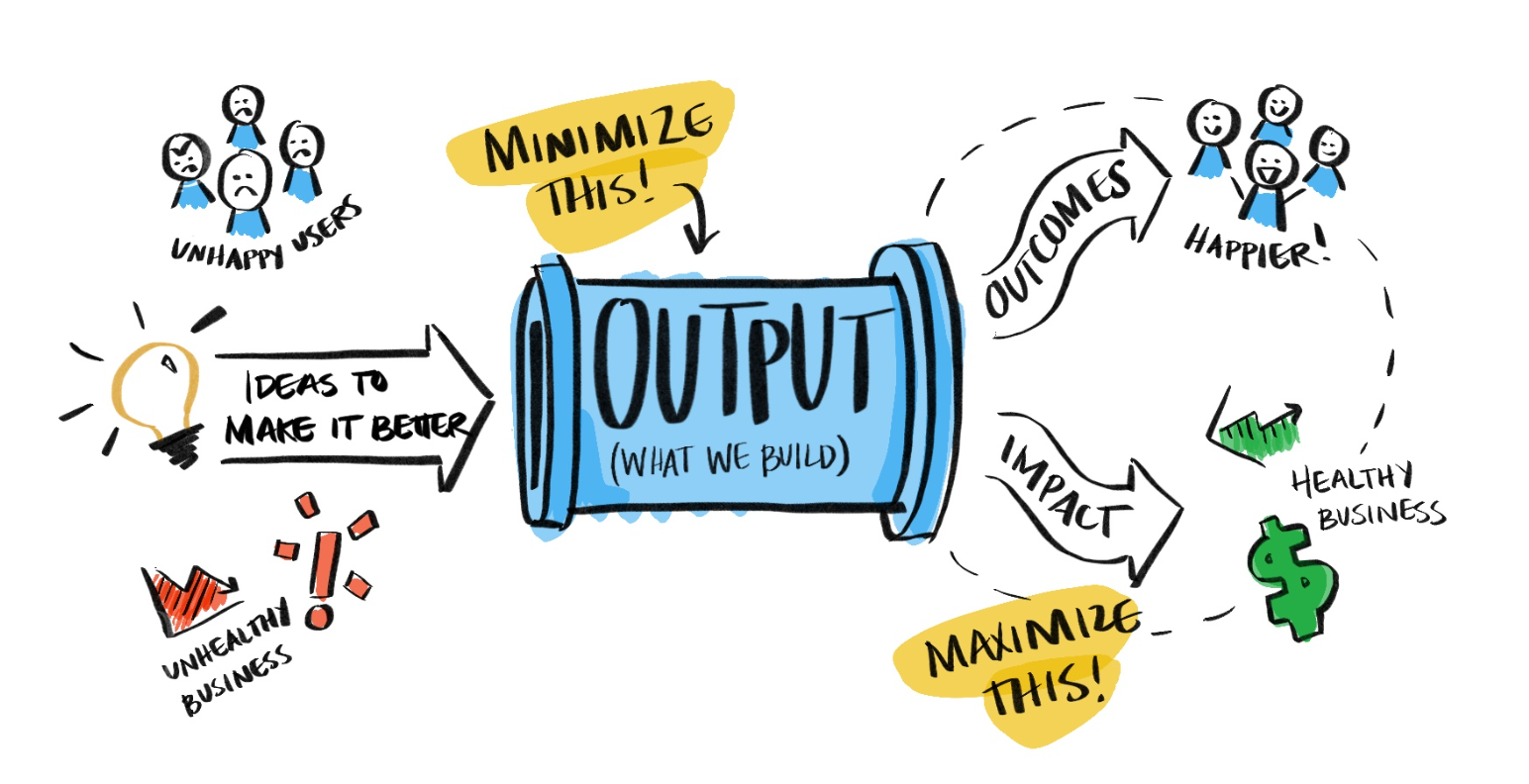
Het doel van je team is niet om output te produceren; het is om een specifiek resultaat te bereiken. Een succesvol team streeft ernaar het gewenste resultaat te maximaliseren en tegelijkertijd de hoeveelheid geproduceerd werk te minimaliseren.

Het eerste Agile Principe stelt dat je topprioriteit is om je klanten gelukkig te maken door waardevolle software zo vroeg en consistent mogelijk op te leveren. Naarmate agile werkwijzen op verschillende gebieden worden toegepast, hebben mensen dit principe geherformuleerd om het belang van het snel en consistent leveren van waarde aan klanten te benadrukken.
Als je succes meet op basis van een resultaatgerichte metriek, zoals "het aantal doorkliks op nieuwsbrieven binnen zes maanden met 15% verhogen", koppel je de inspanningen van je team onmiddellijk aan de waarde voor je organisatie en klanten. Dit helpt je te begrijpen welke impact je maakt en wanneer je echt een verschil maakt.
Als je daarentegen succes meet door alleen te kijken naar de dingen die je produceert, zoals "het aantal opgeleverde features" of "het aantal voltooide punten in een scrum sprint", loop je het risico in wat Melissa Perri (product management expert, spreker en auteur) "de bouwval" noemt. Deze valkuil houdt in dat je je alleen richt op het maken van features zonder rekening te houden met de gewenste resultaten. Wanneer organisaties prioriteit geven aan output boven uitkomsten, lopen ze het risico verstrikt te raken in een cyclus van het bouwen van meer en meer features zonder echt te begrijpen of ze klantproblemen oplossen of bedrijfswaarde creëren.
Door je te fixeren op het opleveren van features als maatstaf voor succes, kun je het grotere geheel uit het oog verliezen. Het vertelt je niet of je de juiste dingen bouwt. Het is dus essentieel om je focus te verleggen naar de resultaten die er toe doen. Dit vereist een mentaliteitsverandering die de behoeften en gewenste resultaten van de klant op de voorgrond plaatst. Door succes te definiëren op basis van resultaten, kan je team ontsnappen aan de bouwval.

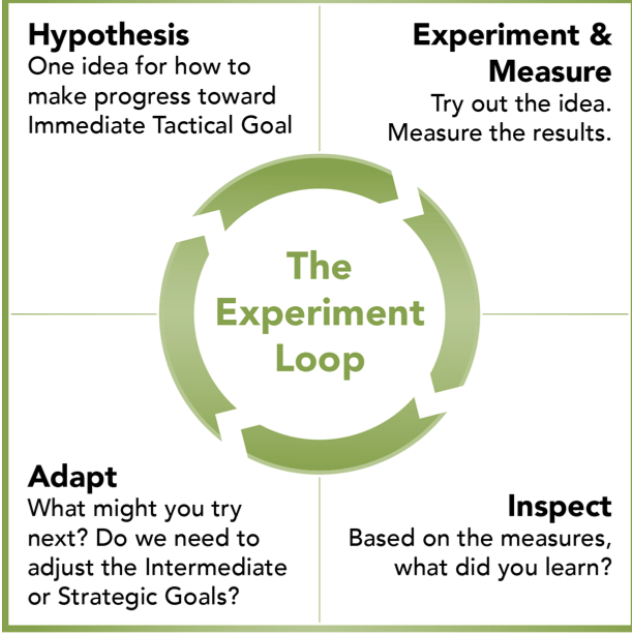
Als je kritisch gaat denken over het leveren van waarde in plaats van features, loop je al snel tegen het probleem aan waar ik het eerder over had: hoe weet je zeker dat de features die je bouwt ook echt waarde gaan leveren? Een resultaatgerichte aanpak erkent dat je misschien niet vanaf het begin alle antwoorden hebt en dat leren een belangrijk onderdeel van het proces is. Daarom heb je bij het werken met uitkomsten een hulpmiddel nodig: het experiment.
Wanneer je resultaatgericht denken combineert met een proces dat gebaseerd is op het uitvoeren van experimenten, begin je echt het ware potentieel van agile benaderingen te ontsluiten. Dit is vooral waardevol in situaties waar veel onzekerheid is. Als je bijvoorbeeld een nieuw softwareproduct maakt, weet je misschien niet zeker of het de gewenste impact zal hebben op je bedrijf en of alle mooie functies die je hebt bedacht wel nodig zijn. Door te focussen op resultaten, kun je doelen stellen die je team toelaten om te experimenteren en verschillende oplossingen uit te proberen tot ze vinden wat het beste werkt.
In een agile context behandelen we elke stap als een hypothese en een experiment gericht op het bereiken van een specifiek resultaat. Dit is waar het concept van een MVP, of Minimum Viable Product, om de hoek komt kijken. Beschouw MVP als het kleinste ding dat je kunt doen of het kleinste ding dat je kunt bouwen om te leren of je hypothese juist is. Dit iteratieve proces van testen, leren en aanpassen stelt teams in staat om te experimenteren, om verschillende oplossingen uit te proberen, totdat ze de oplossing vinden die werkt.
Werknemers vinden het vaak een uitdaging om een diep gevoel van doelgerichtheid en motivatie te ervaren, enkel door de output die ze produceren. Wat mensen echt drijft om elke dag op het werk te verschijnen, zijn niet de specifieke taken waarmee ze zich elke dag bezighouden, maar eerder de betekenisvolle resultaten waar hun werk uiteindelijk aan zal bijdragen.
De nadruk op resultaten helpt om je team op één lijn te krijgen rond een gemeenschappelijk doel en gedeelde doelen. Door duidelijkheid te verschaffen over wat er bereikt moet worden, kun je je team motiveren en in staat stellen om samen te werken aan duidelijke doelen die het product moet bereiken. Hierdoor kan je team prioriteiten stellen in hun werk en functies bouwen die bijdragen aan het bereiken van die doelen. Door hen beslissingen te laten nemen over de functies die ze bouwen, krijgen ze een groter gevoel van eigenaarschap over het werk dat ze doen.

Nu ben je het er misschien wel mee eens dat focussen op resultaten klinkt als een goed idee, maar ze daadwerkelijk implementeren in onze bedrijfspraktijken is niet zo eenvoudig. Elke methodologie heeft zijn nadelen. Eén uitdaging is dat uitkomsten minder gemakkelijk te meten en te kwantificeren zijn dan outputs. Ten tweede staan veel bedrijven onder druk om snel door te gaan naar het volgende project als het ene is afgerond. Helaas wordt het iteratieve proces van testen, leren en aanpassen nog steeds niet vaak toegepast.
Tot slot, wat het moeilijk maakt, is dat we vaak doelen stellen die te hoog gegrepen zijn. Als je het team bijvoorbeeld vraagt om het bedrijf winstgevender te maken of de risico's te verminderen, dan is dat te complex omdat die uitdagingen bestaan uit veel variabelen om te beïnvloeden. Deze doelen op impactniveau zijn te complex voor teams. In plaats daarvan moet je je richten op kleinere en beter beheersbare doelen. Om dit te doen, moet je je team vragen om zich te concentreren op het veranderen van klantgedrag op manieren die positieve bedrijfsresultaten opleveren.
In zijn boek "Outcomes Over Output: Why Customer Behavior Is The Key Metric For Business Success" presenteert Joshua Seiden drie magische vragen die je kunnen helpen bij het identificeren van geschikte resultaten:
Ik zal je een voorbeeld geven van hoe dit werkt. Stel je voor dat je een e-commerce kledingwinkel runt en je hebt te maken met zware concurrentie van een concurrerend bedrijf. Je doel is om de klantloyaliteit te verbeteren, dus stel je het team een breed doel om de frequentie van klantbezoeken te verhogen van één keer per maand naar twee keer per maand.
Om dit effect te bereiken, moet u specifiek gedrag van klanten identificeren dat correleert met het bezoeken van uw site. U merkt bijvoorbeeld dat klanten de neiging hebben om de site te bezoeken na het openen van de maandelijkse nieuwsbrief waarin nieuwe artikelen worden gepresenteerd. Daarom zou een mogelijke uitkomst kunnen zijn om de doorklikratio van de nieuwsbrief te verhogen.
Daarnaast merkt u dat klanten de site ook bezoeken nadat een vriend een afbeelding van een van de artikelen heeft gedeeld op sociale media. Een andere mogelijke uitkomst is dus om klanten aan te moedigen vaker afbeeldingen van artikelen te delen.
Door je te richten op deze klantgedragingen die het gewenste resultaat van sitebezoeken bepalen, zorg je ervoor dat je doelen zowel observeerbaar als meetbaar zijn. Dit is cruciaal omdat je zo de voortgang effectief kunt beheren en bijhouden.
Ik hoop dat dit voorbeeld duidelijk maakt hoe resultaten specifiek kunnen zijn en gemakkelijk kunnen worden uitgesplitst. Onthoud dat een resultaat een gedrag is dat klanten vertonen en dat direct van invloed is op de bedrijfsresultaten. Door dit gedrag te begrijpen, kunt u uw inspanningen afstemmen op de resultaten die echt belangrijk zijn voor uw bedrijf.
👀 Meer weten over onze diensten?


Een klantenportaal 2.0 en een energie app die meer doen dan alleen verbruik tonen. Dat zijn dé twee manieren om als energieleverancier je digitale klantbeleving te verbeteren. In dit artikel geven we een woordje uitleg, een aantal concrete ideeën en
Lees verder
Liferay DXP is de afgelopen jaren uitgegroeid tot een veelgebruikt portaalplatform voor het bouwen en beheren van geavanceerde digitale ervaringen. Organisaties gebruiken het voor intranetten, klantportalen, self-service platforms en meer. Hoewel Lif
Lees verder

Op de hoogte blijven van de nieuwste trends en best practices is cruciaal in de snel evoluerende wereld van softwareontwikkeling. Innovatieve benaderingen zoals EventSourcing en CQRS kunnen ontwikkelaars in staat stellen flexibele, schaalbare en veil
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
