.svg?width=174&auto=compress,webp&upscale=true "aca-group (black)")
.svg?width=139&auto=compress,webp&upscale=true "aca-group (black)")

Reading time 6 min
Patrik Söderström

Effective audits are essential for regulatory compliance, risk management, and improving operational efficiency. However, traditional audit processes can be time-consuming and often provide only limited insights. Fortunately, artificial intelligence (AI) offers a revolutionary solution. By applying machine learning (ML), you can optimize audit processes, uncover hidden risks and patterns, and transform how audits are conducted. This article explores how AI can help make your organization's audits more efficient and secure.
Audit data often holds untapped potential. It contains crucial information about an organization’s operations and risks, but due to its size and complexity, analyzing this data has traditionally been challenging. AI makes it possible to analyze this data at a deeper level, revealing insights that would otherwise remain hidden. As a result, audits can shift from being a necessary task to a strategic opportunity for growth and better decision-making.
AI opens up new possibilities for audits by combining advanced data analysis with automation. Here are some ways AI adds value to the audit process:
By automating repetitive, time-consuming tasks, AI allows auditors to focus on strategic activities. This saves time, boosts productivity, and reduces audit costs.
AI and ML techniques can analyze vast amounts of data with a precision that's hard for humans to match. This leads to more accurate and reliable audit results.
AI can quickly identify anomalies in data through techniques like outlier detection, helping detect fraud or risks early on, so you can address them before they escalate.
AI continuously monitors regulatory compliance, contributing to robust risk management and lowering the chances of fines or legal issues.
AI, using techniques like clustering and Natural Language Processing (NLP), provides deeper insights into complex business processes. This helps identify inefficiencies, risks, and areas for improvement, leading to smarter and more effective operations.
AI technologies are transforming how audits are conducted. Below are some key AI and ML techniques that help make audits more effective:
Clustering algorithms, like K-means, Hierarchical Clustering, and DBSCAN, group data into clusters based on similarities. For instance, K-means works by grouping data points based on their proximity to a central point (centroid), with the closest points forming a cluster.
In auditing, clustering helps segment financial transactions, customer profiles, or operational data, making it easier to spot patterns indicating risks or inefficiencies. This enables you to detect suspicious groups of transactions that may require further investigation.
Outlier detection identifies data points that significantly deviate from the rest of the dataset. This technique is crucial for spotting fraudulent activities, errors, or unusual transactions.
Outlier detection uses statistical methods, ML models like Isolation Forest, and techniques such as Z-score and IQR (Interquartile Range) to detect these anomalies. By highlighting irregular data points, auditors can focus on the most high-risk elements.
NLP enables computers to understand, analyze, and generate text data such as emails, contracts, and reports.
NLP models, like BERT and GPT, use techniques like tokenization, stemming, lemmatization, and sentiment analysis to process and analyze text.
This is ideal for identifying relevant information and risks hidden in large amounts of documentation. For example, NLP can scan thousands of emails for suspicious phrases or patterns that indicate potential compliance risks or fraudulent activities.
Let’s look at a practical example. An international financial services provider decided to modernize their audit processes using AI. Traditional audits were time-consuming and often missed risks due to the overwhelming amount of data involved.
By incorporating AI, the organization could quickly identify risks that had previously gone unnoticed.
The company used an interactive scatter plot chart, powered by clustering, to visually display risk scores for each audit.
This visualization made it easy to spot high-risk audits, with color gradients ranging from blue (low risk) to red (high risk).
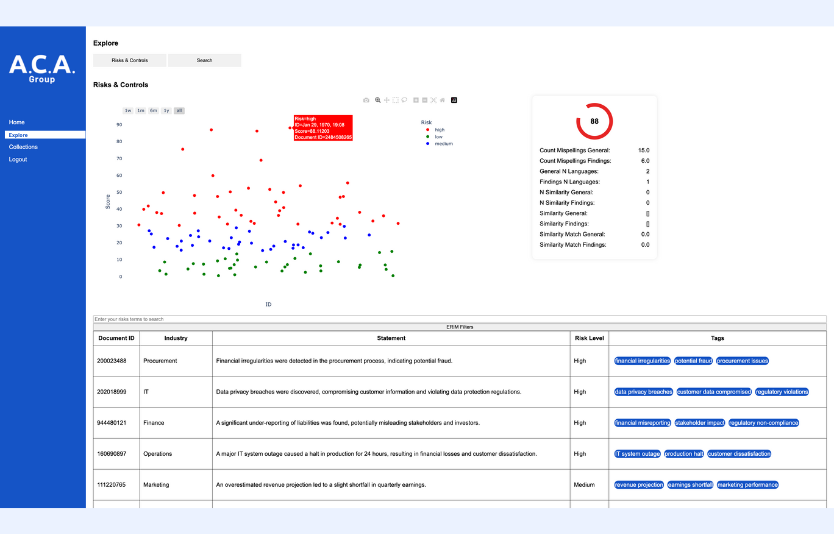
Every document was automatically analyzed and tagged based on common features and patterns. These AI-generated tags provided a structured and organized approach to document management, allowing the company to quickly find key information in a sea of data.
NLP was used to analyze text data from contracts and reports, extracting risk factors. This allowed users to swiftly identify potential risks and gain valuable insights from unstructured data.
By integrating AI technologies into your audit process, you can not only modernize your audits but also significantly enhance your ability to manage risks and ensure compliance. Whether it’s fraud detection, compliance monitoring, or gaining deeper business insights, AI helps you make faster, more accurate decisions. Auditing is no longer just a requirement - it becomes a powerful tool for growth and success.


We need to talk about the "illusion of speed” in the age of AI. In times where every post on LinkedIn seems to show that all your competitors are making a shift from traditional coding to 100% AI agentic software development, reality is somewhat more
Read more

Has your company already settled into the seats of first class, or have you not yet found your place on the AI train? Our AI expert Alexander Frimout explains which processes are ideally suited for your first AI business case. And why some companies
Read more

For every external tool you want to connect to your AI system, you have to build a custom integration. This comes with two major downsides. One: it takes up a lot of your time. Two: you can not scale this way of working. Luckily, the Model Context Pr
Read moreGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
