.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 7 min
Cedric Dunon

AWS Config is een service waarmee u de configuraties van uw AWS-bronnen kunt beoordelen, controleren en evalueren. Dit kan worden gebruikt voor:
In deze blogpost wil ik gedetailleerd uiteenzetten hoe u uw cloudresources kunt bewaken met deze tool. Dit eerste deel bespreekt het instellen van een AWS Config-account, het inschakelen van meldingen wanneer resources niet voldoen en de implementatie.
AWS is het belangrijkste cloudplatform dat we bij ACA gebruiken. We beheren meerdere accounts in AWS om allerlei applicaties te hosten voor onszelf en voor onze klanten. In de loop der jaren hebben we steeds meer projecten opgezet in AWS. Dit heeft geleid tot het aanmaken van veel accounts, die op hun beurt veel cloudresources gebruiken. Dit betekent natuurlijk dat het bijhouden van al deze resources ook steeds uitdagender wordt.
AWS Config heeft ons geholpen om met deze uitdaging om te gaan. We gebruiken het omalle resources in onze hele AWS-organisatie te inventariseren en te bewaken. Het stelt ons ook in staat omcompliance-regels inte stellen voor onze resources die in elk account moeten worden nageleefd. Bijvoorbeeld: een Elastic IP mag niet ongebruikt blijven of een EC2-beveiligingsgroep mag niet al het inkomende verkeer zonder beperkingen toestaan. Op deze manier kunnen we een standaard creëren voor al onze AWS-accounts.
Het inschakelen van AWS Config in je organisatie geeft ons een aantal voordelen.
In dit eerste deel van mijn AWS Config blog wil ik laten zien hoe je AWS Config instelt voor een enkel account. In een toekomstige blogpost zal ik meer uitleggen over hoe je dit voor een hele AWS organisatie kunt doen. De afbeelding hieronder toont een overzicht van de setup in een enkel account, met daarin
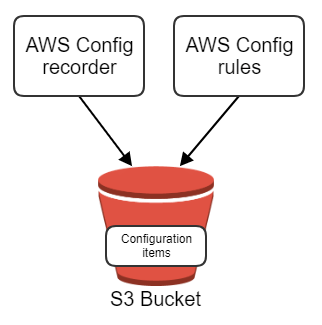
De AWS Config recorder is het belangrijkste onderdeel van de set-up. Je kunt de standaardrecorder inschakelen in de AWS-console. Standaard neemt deze alle resource types op. Meer informatie over alle beschikbare resourcetypes vind je op deze pagina.
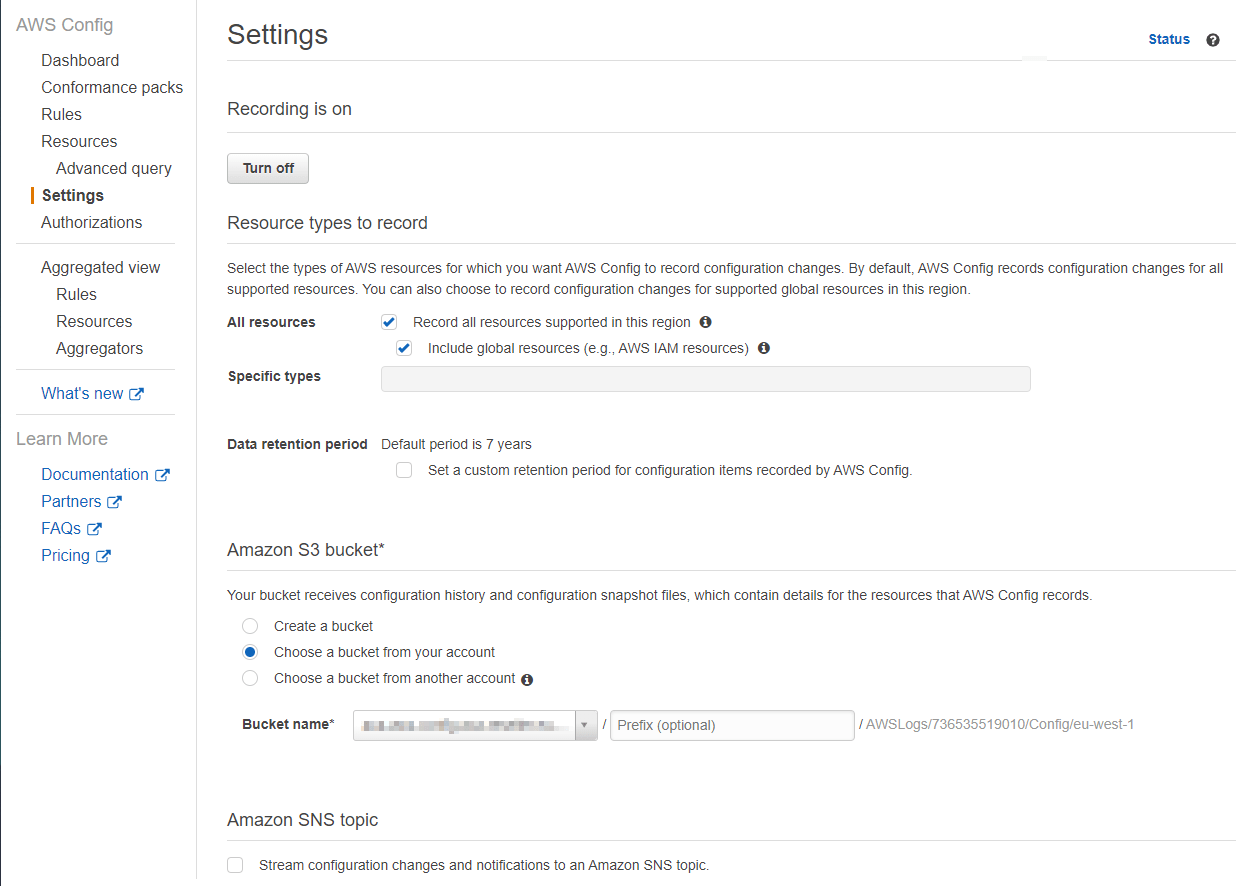
Wanneer je begint met opnemen, worden alle AWS-resources opgeslagen in de S3-bucket als configuratie-items. Het opnemen van deze configuratie-items is niet gratis. Op het moment van schrijven kost het $0,003 per opgenomen configuratie-item. Deze kosten worden gegenereerd wanneer het configuratie-item voor het eerst wordt opgenomen of wanneer er iets verandert aan het configuratie-item of een vanzijn relaties. In de instellingen van de AWS Config recorder kun je ook aangeven hoe lang deze configuratie-items moeten worden opgeslagen in de S3 bucket.
De AWS Config regels zijn het belangrijkste onderdeel van je setup. Deze regels kunnen worden gebruikt als compliancy controles om ervoor te zorgen dat de bronnen in je account zijn geconfigureerd zoals bedoeld. Het is mogelijk om aangepaste regels te maken of te kiezen uit een grote set vanAWS beheerde regels. In onze setup bij ACA hebben we ervoor gekozen om alleen AWS managed rules te gebruiken, omdat deze aan al onze behoeften voldeden. In de afbeelding hieronder zie je een van de regels die we hebben ingezet.
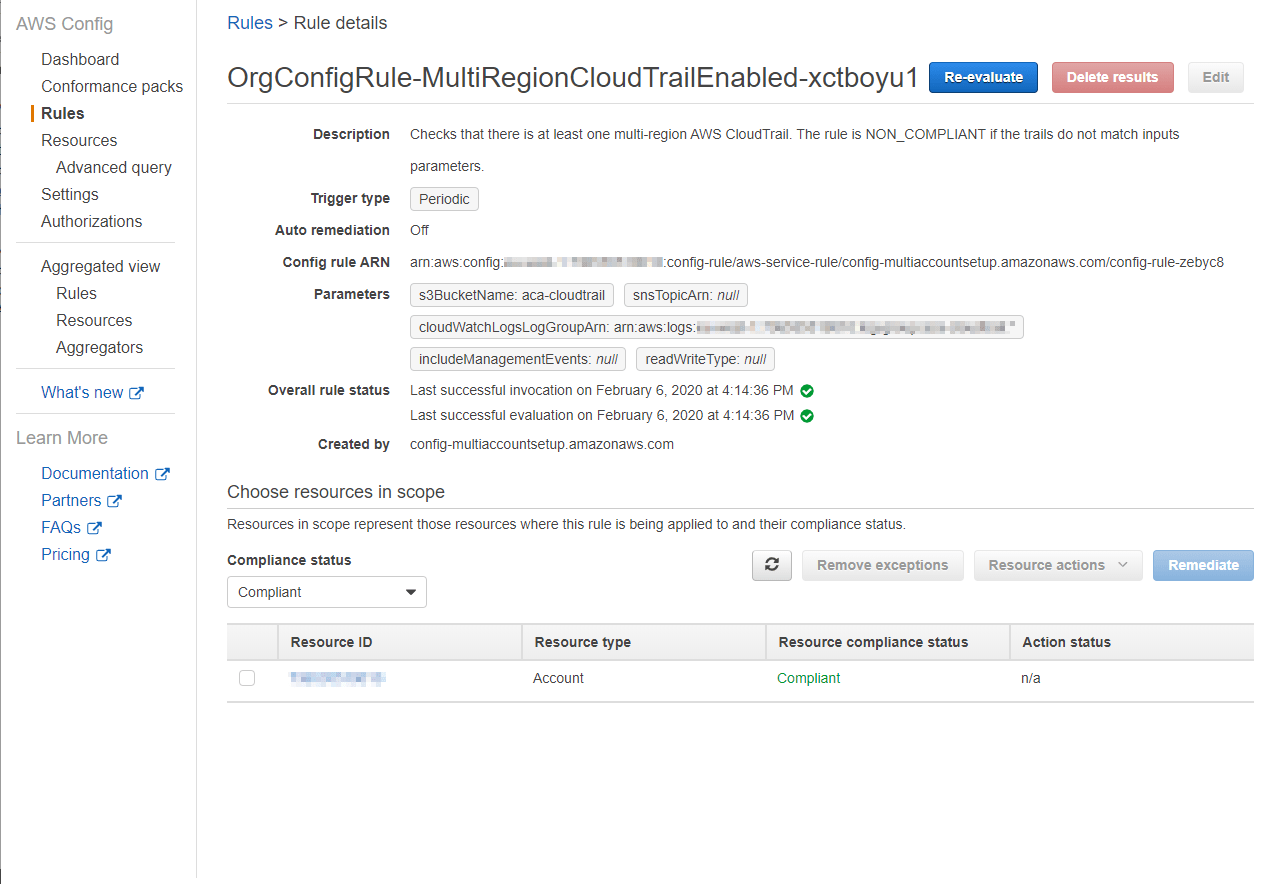
Net als het vastleggen van configuratie-items, kost het uitvoeren van regelevaluaties geld. Op het moment van schrijven is dit $0,001 voor de eerste 100.000 regelevaluaties per regio, $.0008 van 100.000 - 500.000 en daarna $.0005.
Er zijn veel regels beschikbaar met verschillende voordelen voor je AWS account. Dit zijn enkele van deAWS beheerde regels die we hebben geconfigureerd:
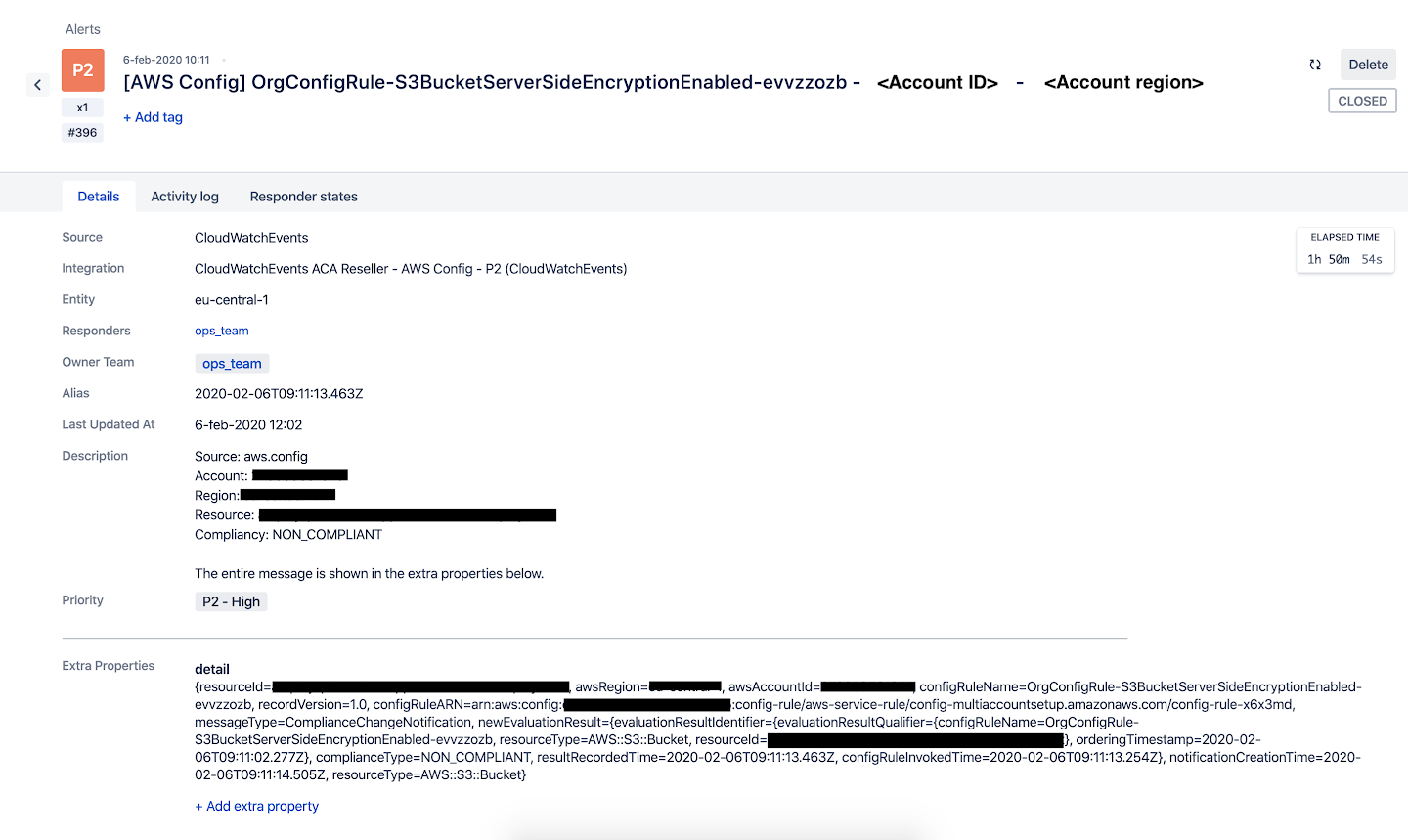
AWS Config-regels controleren configuratie-items. Als een configuratie-item niet voldoet aan de eisen van de regel, wordt het gemarkeerd als 'niet-conform'. Wanneer dit gebeurt, wil je hiervan op de hoogte worden gebracht zodat je de juiste acties kunt ondernemen om het probleem op te lossen. In de afbeelding hieronder zie je hoe we de notificaties voor onze AWS Config-regels hebben geïmplementeerd.
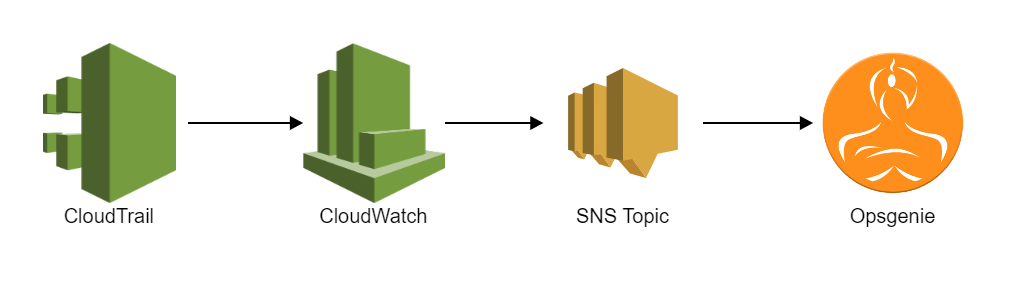
Om te beginnen met meldingen, moet CloudTrail zijn ingeschakeld en moet er een spoor zijn dat alle activiteit in het account logt. Nu kan CloudWatch de CloudTrail-gebeurtenissen oppikken. In onze setup hebben we 5 CloudWatch-eventregels gemaakt die meldingen versturen op basis van prioriteit. Dit maakt het voor ons mogelijk om te beslissen wat het prioriteitsniveau van de melding voor elke AWS Config-regel moet zijn. De afbeelding hieronder laat hier een voorbeeld van zien.
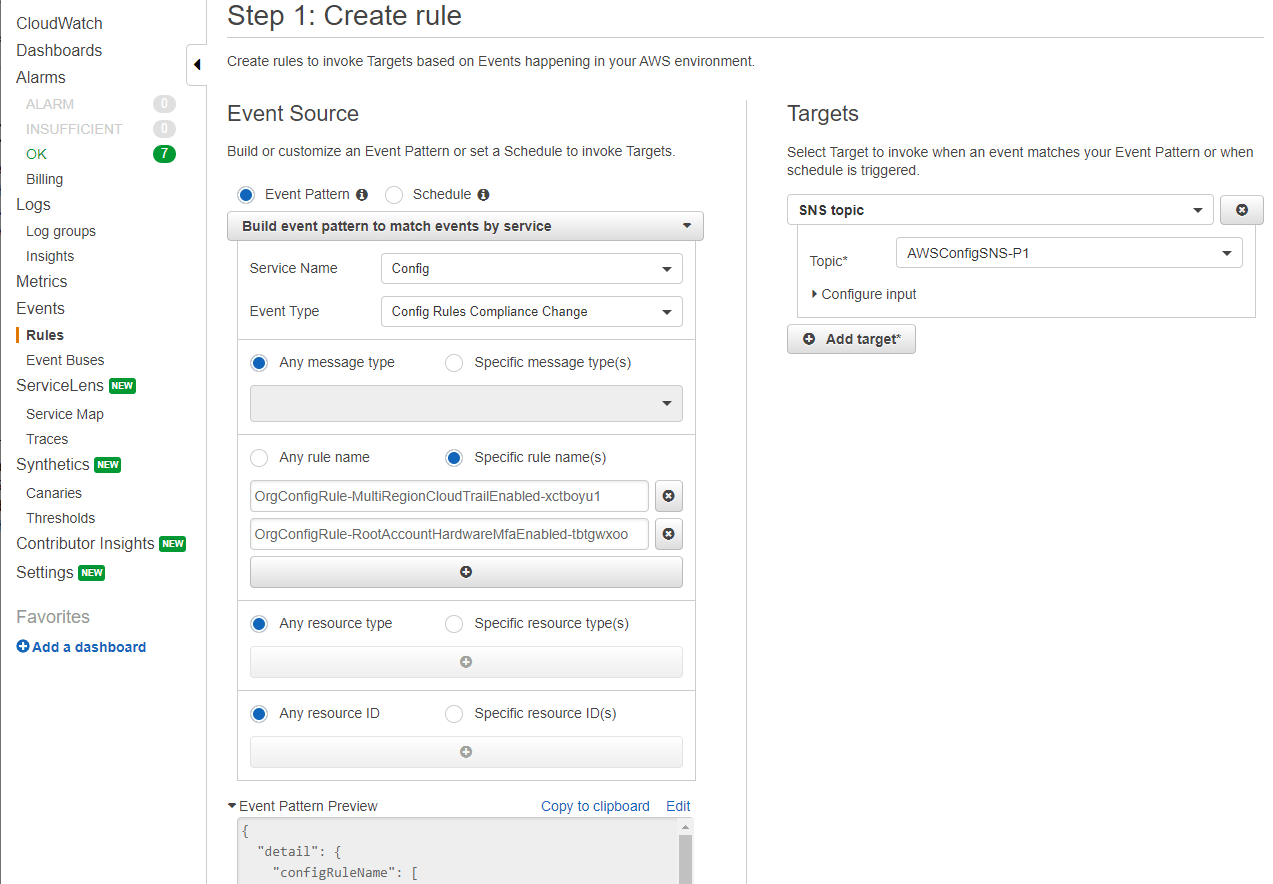
In de sectie 'Targets' zie je het SNS topic dat de meldingen van de CloudWatch event rule ontvangt. Opsgenie heeft een apart abonnement voor elk van de SNS topics (P1, P2, P3, P4 & P5). Op deze manier ontvangen we meldingen wanneer er wijzigingen in de compliance plaatsvinden en zien we ook de ernst ervan door naar het prioriteitsniveau van onze Opsgenie-melding te kijken.
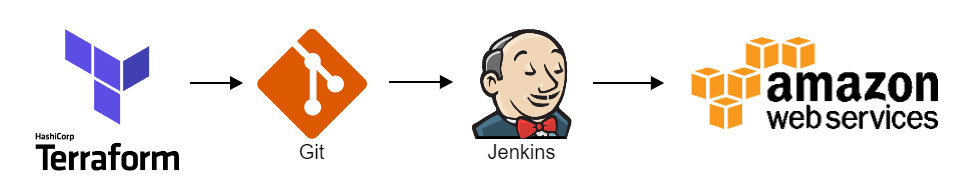
Bij ACA proberen we onze AWS-infrastructuur altijd te beheren met Terraform. Dit is niet anders voor AWS Config. Dit is onze implementatieworkflow:
We beheren alles wat met AWS Config te maken heeft in Terraform. Hier is een voorbeeld van een van de AWS Config regels in Terraform, waarbij de waarde van het rule_identifier attribuut kan worden gevonden in de documentatie van de AWS Config beheerde regels:
De Terraform code wordt versiebeheer met Git. Als de code moet worden ingezet, doet Jenkins een checkout van de Git repository en zet het uit op AWS met Terraform.
Met AWS Config krijgen we meer inzicht in onze AWS-cloudbronnen. AWS Config verbetert onzebeveiliging, voorkomt dat we resources in gebruik houden die niet worden gebruikt en zorgt ervoor dat onze resources optimaal worden geconfigureerd. Naast deze voordelen biedt het ons ook een inventaris van al onze resources en hun configuratiegeschiedenis, die we op elk moment kunnen inzien.
Tot zover deze blogpost over AWS Config. In een toekomstig deel wil ik uitleggen hoe je het instelt voor een AWS-organisatie. Als je dit onderwerp interessant vond en je hebt een vraag of je wilt meer weten over onze AWS Config setup, neem dan contact met ons op viacloud@aca-it.be


We zijn als ACA Group officieel ISO 27001 compliant! Onze Information Security Manager Simon Vercruysse legt uit wat die certificatie precies inhoudt en wat de voordelen zijn voor jouw (toekomstige) project.
Lees verder

CloudBrew is altijd een hoogtepunt op onze kalender geweest, maar de editie van 2025 voelde anders. Misschien lag het aan de timing. Slechts een maand eerder, in november 2025, opende de Azure Belgium Central-regio eindelijk haar deuren. ACA opereert
Lees verder

Een betere uptime, lagere kosten en vendor lock-in vermijden. Dat zijn drie van de redenen waarom onze klanten kiezen voor een multicloud-strategie. Onze Cloud project manager Roel Van Steenberghe legt uit wat zo’n strategie precies inhoudt en wat de
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
