.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 9 min
Koen Olaerts


Deze applicatie is echter niet gekoppeld aan een repository of een back-end applicatie, wat betekent dat ze niets aan hun menu kunnen toevoegen of wijzigen. Dit is behoorlijk lastig: door de huidige pandemie moesten ze overstappen op een leveringssysteem en ze willen hun website regelmatig kunnen bijwerken.
Toen je dit kleine scenario hoorde, herinnerde je je net dat je ergens een Liferay 7.2 portaal hebt draaien en je vroeg je af of je, met behulp van de nieuwe headless API's, kon inspringen en hen kon helpen.
Nadat u contact had opgenomen met het restaurant, kwam u erachter dat hun eisen vrij eenvoudig waren:
We schreven al een blogpost om dit onderwerp te introduceren, maar in een notendop zou je kunnen zeggen dat deze headless API's veel van Liferay's ingebouwde functies en inhoud voor het grijpen hebben en klaar zijn voor gebruik in een aangepaste front-end applicatie, smart device, IoT-apparaten, ...
Alle beschikbare endpoints van Liferay worden geleverd met swagger documentatie, die jehierkunt vinden. Zoals je kunt zien zijn er veel verschillende domeinen die Liferay voor ons beschikbaar heeft gemaakt. Voor het doel van deze blog zal ik echter een korte blik werpen op deHeadless Admin User en HeadlessDelivery.
Het doel van deze oefening is om met zo min mogelijk inspanning te voldoen aan de eisen van onze klant. Dat betekent natuurlijk dat we optimaal gebruik maken van de beschikbare endpoints en de ingebouwde functies van Liferay.
Dit overzicht zal alleen wat basisinformatie bevatten, zoals:
Als je deHeadless Admin User vandichterbij bekijkt, zie je een endpoint dat alle gebruikersaccounts van een bepaalde site ophaalt:
Als we de werknemers behandelen als gebruikers van een site, kunnen we hun informatie blootstellen aan de Angular-applicatie. Om aan alle vereisten te voldoen, moeten we onze gebruikers verrijken met 2 aangepaste velden:
Nu we een manier hebben bedacht om aan een van de eisen van het restaurant te voldoen, moeten we ervoor zorgen dat onze Angular-applicatie dit ook daadwerkelijk kan aanpakken zonder geblokkeerd te worden. Hiervoor moeten we een beetje configureren in onze portal:
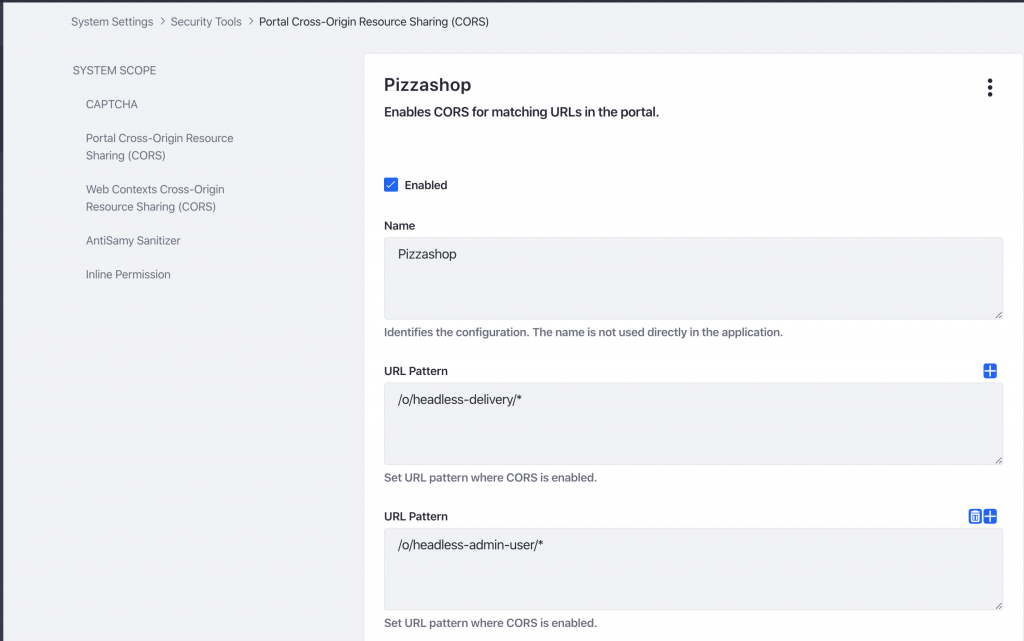
Zoals je in dit voorbeeld kunt zien, heb ik alle eindpunten met betrekking tot headless-delivery en headless-admin-user vrijgegeven. Om voor de hand liggende redenen wilt u dit misschien beperken tot de eindpunten die u wilt blootstellen.
Aanvullende informatie overhet maken van geauthenticeerde verzoeken kan worden gevonden opde officiële site van Liferay.
Als we alle gebruikers van onze gewenste site ophalen, krijgen we het volgende antwoord voor elke gebruiker:
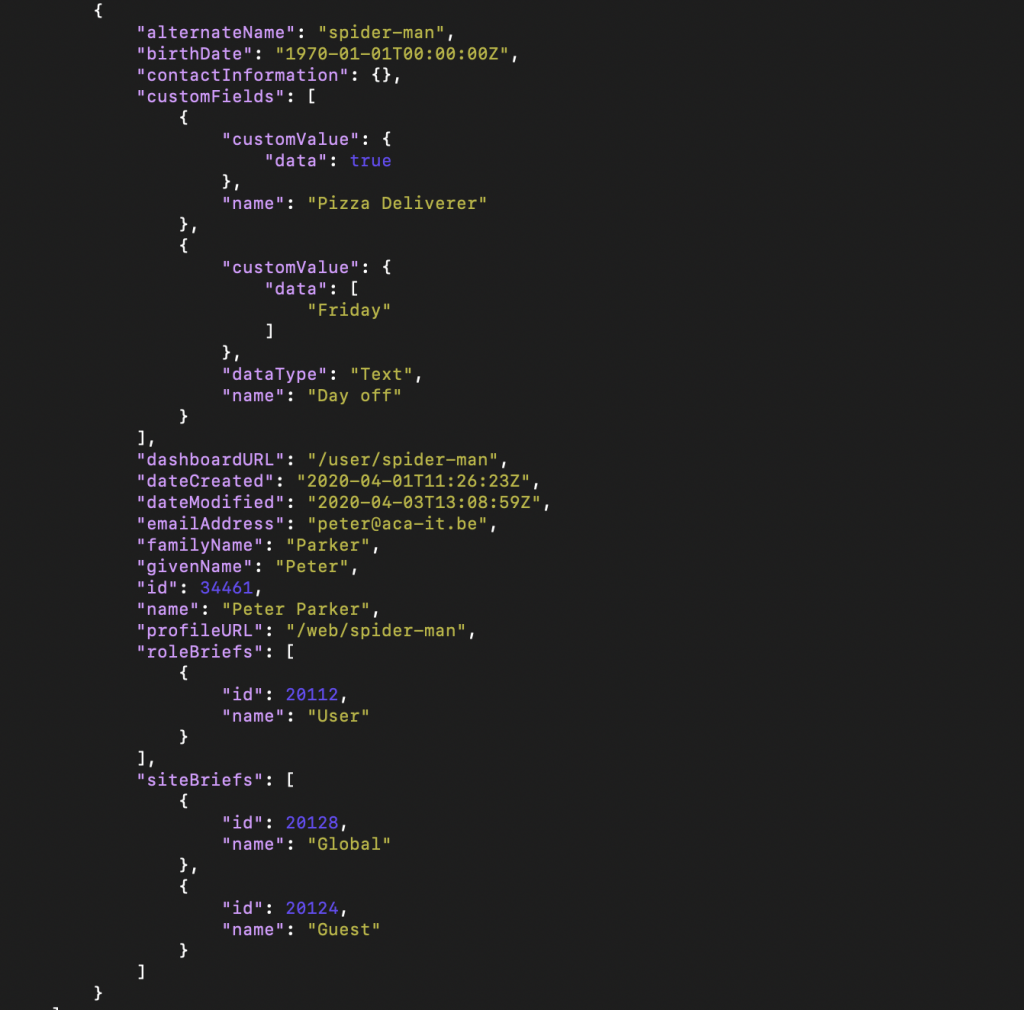
Zoals u kunt zien bevat dit antwoord alle informatie die we nodig hebben, maar ook veel overbodige informatie. We kunnenhet antwoord beperken tot de velden die we nodig hebben door ze toe te voegen aan ons verzoek:
Dat resulteert in de volgende respons voor elke gebruiker:

Met behulp van deze respons kan de Angular-applicatie het vereiste overzicht genereren:

Een nadeel van deze aanpak is dat je beperkt bent tot het domeinmodel van Liferay. Je zult de JSON-respons handmatig moeten parsen of je model moeten afstemmen op dat van Liferay, wat in het geval van deze aangepaste velden een heel gedoe kan zijn.
Om het werknemersoverzicht te maken, hebben we gebruik gemaakt van de Liferay-gebruikers, die we in dit geval perfect konden afstemmen op de vraag van onze klant. Hoewel Liferay een breed scala aan endpoints biedt die gebruikt kunnen worden om aan de vraag van uw klant te voldoen, zal dit niet altijd het geval zijn.
Neem bijvoorbeeld de pizza's op onze menukaart, deze zouden de volgende informatie moeten bevatten:
Er is geen manier om deze informatie te mappen op een bestaand Liferay object. We zullen dus zelf zo'n object moeten maken. Bij voorkeur willen we deze objecten via de headless API ontsluiten met zo min mogelijk inspanning. Aangezien Liferay ons nog niet heeft gezegend met de mogelijkheid om aangepaste objecten te maken die gepaard gaan met hun API's, zullen we hier buiten de gebaande paden moeten denken.
Als je bekend bent met de web content articles van Liferay, dan weet je dat een web content article gebruik maakt van een 'Structure'. Een structuur is iets dat we zelf kunnen maken en waarvan we de velden kunnen definiëren. We kunnen bijvoorbeeld de volgende pizzastructuur maken:
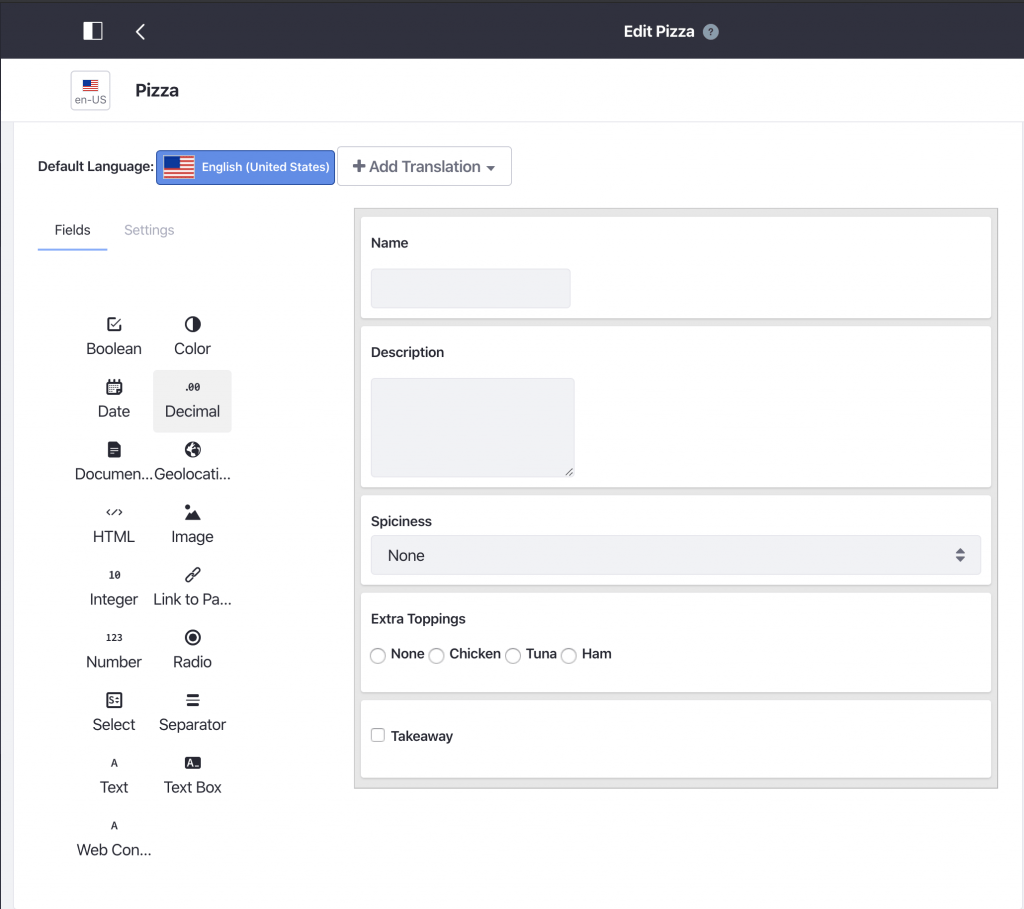
Met deze structuren kunnen we onze verschillende pizza's maken in de vorm van webinhoudsartikelen. Aangezien een webcontentartikel een ingebouwde functie van Liferay is, moet er wel een eindpunt zijn dat ze blootstelt, namelijk:
Maar, en je hebt het waarschijnlijk al geraden, dit geeft ons ook veel overbodige informatie. Dus moeten we de relevante velden toevoegen aan het verzoek:
Dat resulteert in de volgende respons:

Met behulp van deze respons genereert de Angular-applicatie het vereiste menu:

Zoals je misschien hebt gemerkt, hebben we in het bovenstaande voorbeeld nog steeds het nadeel dat we handmatig moeten parsen. Idealiter zouden we het antwoord ook kunnen definiëren. En dat kunnen we... zij het met een omweg. Webcontentartikelen gebruiken niet alleen structuren, maar ook sjablonen. En net als bij structuren kunnen we deze sjablonen ook definiëren.
Onze lokale pizzeria heeft besloten om pasta's op het menu te zetten. Bovendien willen we ons deze keer niet meer bezighouden met het handmatig parsen. We willen gebruikmaken van de interfaces van Angular om dit automatisch te doen. Stel je de volgende interface voor in je Angular-applicatie:
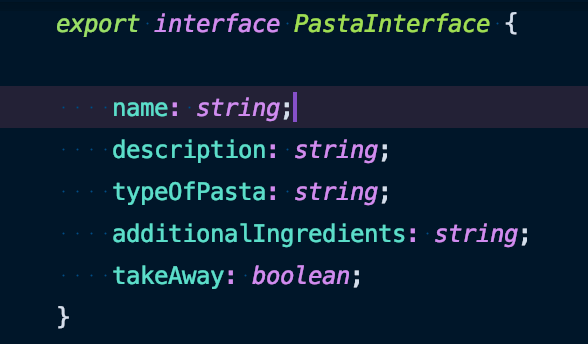
In Liferay kunnen we bijvoorbeeld een sjabloon 'Pasta' definiëren dat overeenkomt met deze interface:
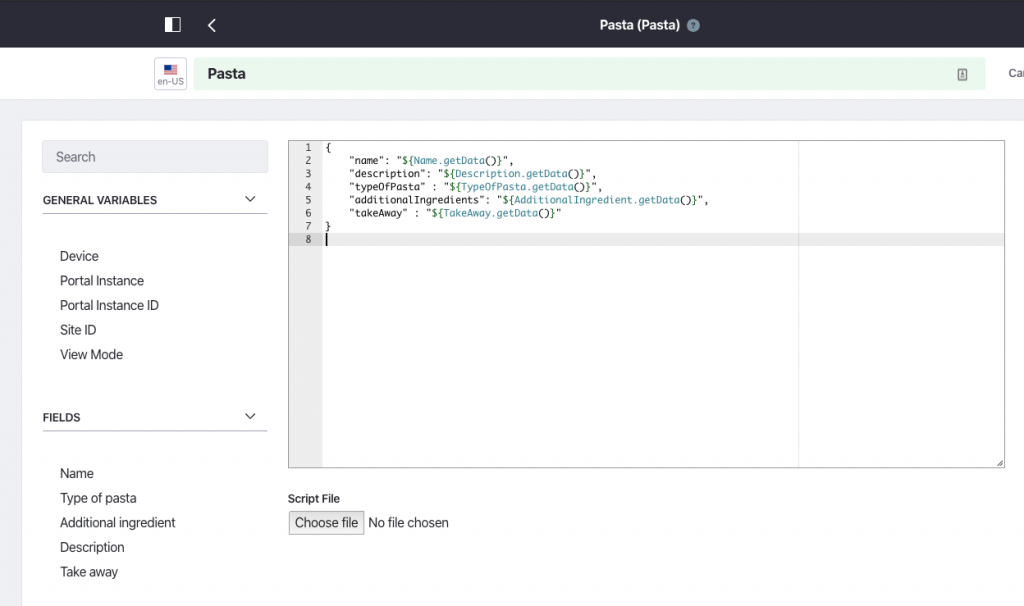
Nu hebben we alleen nog een eindpunt nodig dat ons sjabloon gebruikt en gelukkig voor ons bestaat dat:
Dat resulteert in het volgende antwoord...
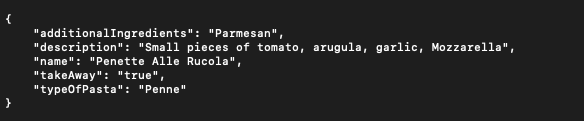
... die kan worden gebruikt om het menu in de Angular-toepassing in te vullen:

Een andere geweldige ingebouwde functie is de mogelijkheid om een filter, sortering of zoekopdracht toe te voegen aan een verzoek. Dit betekent dat Liferay's headless API dit voor je regelt. Hier zijn enkele voorbeelden:
Sorteren op titel
Artikelen met 'Bolognese' zoeken
Filteren op titel
Als u de velden leeg laat, wordt alleen de pagineringsinformatie geretourneerd, inclusief het totale aantal objecten dat door het verzoek is gevonden.
Je kunthier meer informatie vinden over filteren, sorteren en zoeken.Disclaimer: Filteren, sorteren en zoeken kunnen niet worden gebruikt als je je eigen aangepaste sjabloon gebruikt. Hier is echter ook een workaround voor, zij het met het nadeel dat je 1 + n requests moet doen: Je kunt je items sorteren/filteren/zoeken door gebruik te maken van de standaard respons van Liferay, die een URL bevat die je naar je aangepaste respons leidt:
Het is waar dat wanneer je een nieuwe structuur of sjabloon aanmaakt, de Id direct wordt gegenereerd. Maar voor elk klein probleem is er een oplossing. Voor dit probleem in het bijzonder zijn er 2 mogelijke benaderingen:
Aangezien we zo min mogelijk moeite willen doen, gaan we voor optie nummer 2: content sets.
Zonder al te veel in detail te treden, zijn contentsets eigenlijk wat ze klinken: een verzameling content die door een beheerder kan worden gedefinieerd. Gelukkig voor ons kunnen we bijvoorbeeld een verzameling maken van alle webinhoudsartikelen op basis van een of meer structuren. Dit betekent dat we een contentset kunnen maken van al onze pizza's en pasta's, waarbij je ook kunt filteren en bestellen via het configuratiescherm.
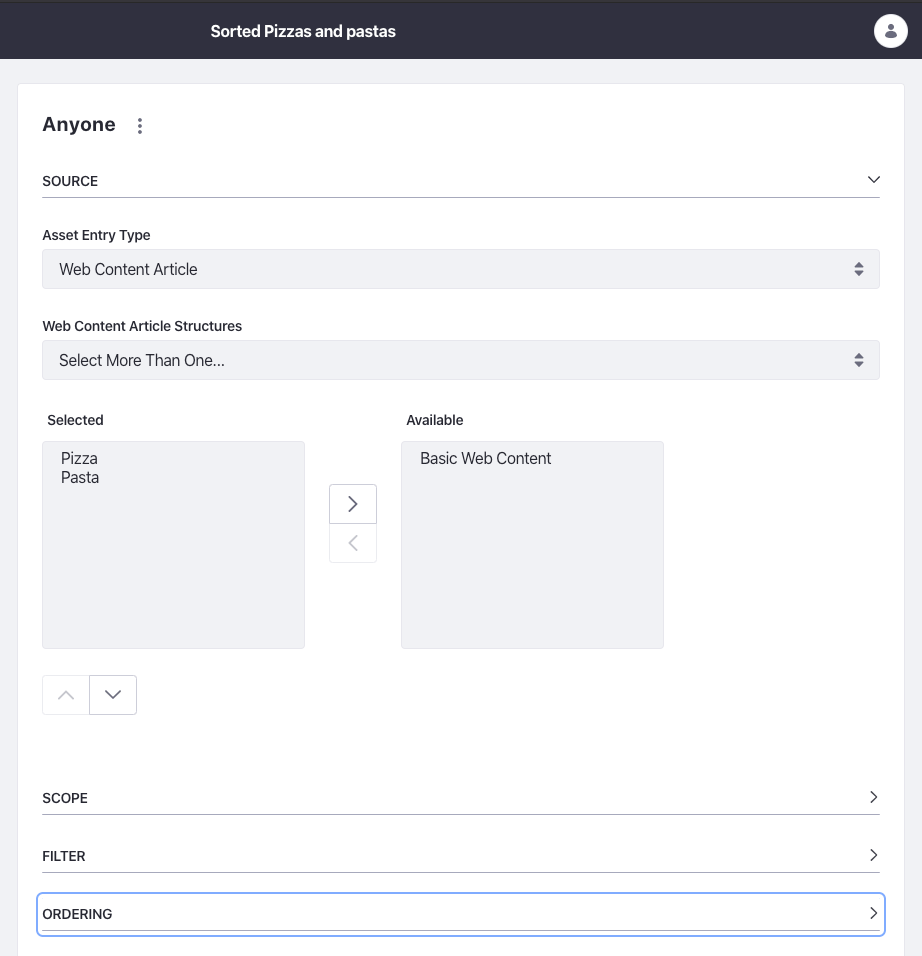
Je voelt misschien al aan waar ik hiermee naartoe wil. Ja, er is ook een eindpunt waarmee we de webinhoudsartikelen kunnen ophalen via de inhoudset:
De sleutel wordt gegenereerd op basis van de naam van de inhoudset, waarbij de spaties worden vervangen door een koppelteken. Gesorteerde pizza's en pasta's zou de sleutel 'gesorteerde-pizza's-en-pasta's' genereren. Meer informatie over het maken van een contentset vindt uhier.
Zonder twijfel hebben Liferay 7.2 headless API's de potentie om aangepaste oplossingen te verrijken met de Liferay functies die we kennen en waar we van houden. Echter, met de introductie van deze headless API's had ik gehoopt dat we een ingebouwde functie zouden hebben om eenvoudig onze eigen aangepaste objecten te maken en de mogelijkheid om deze te ontsluiten via speciale API's. Dat gezegd hebbende, de mogelijkheid om deze functie enigszins te reproduceren door middel van web content artikelen en hun headless API's spreekt voor de flexibiliteit en uitbreidbaarheid van Liferay zelf.
Ik kijk in ieder geval uit naar wat ze nog meer voor ons in petto hebben!


Bij de ontwikkeling van software kunnen aannames ernstige gevolgen hebben en we moeten altijd op onze hoede zijn. In deze blogpost bespreken we hoe je omgaat met aannames bij het ontwikkelen van software. Stel je voor... je rijdt naar een bepaalde pl
Lees verder

ACA doet veel projecten. In het laatste kwartaal van 2017 deden we een vrij klein project voor een klant in de financiële sector. De deadline voor het project was eind november en onze klant werd eind september ongerust. We hadden er echter alle vert
Lees verder
Liferay DXP is de afgelopen jaren uitgegroeid tot een veelgebruikt portaalplatform voor het bouwen en beheren van geavanceerde digitale ervaringen. Organisaties gebruiken het voor intranetten, klantportalen, self-service platforms en meer. Hoewel Lif
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
