.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

5 MEI 2025
Leestijd 4 min
Jean-Pierre Bernaerts
.jpg?auto=compress,webp&upscale=true&width=610&height=488&name=train%20driving%20in%20city%20(1).jpg "<span id=\"hs_cos_wrapper_name\" class=\"hs_cos_wrapper hs_cos_wrapper_meta_field hs_cos_wrapper_type_text\" style=\"\" data-hs-cos-general-type=\"meta_field\" data-hs-cos-type=\"text\" >IT-problemen oplossen: Deel 2. Voorbeeld uit de echte wereld - Treinaankomstdetectie revolutioneren</span>")
In Deel 1. De wetenschappelijke methode onderzochten we de toepassing van de wetenschappelijke methode bij het oplossen van zakelijke uitdagingen. In deel 2 duiken we in een probleem uit de praktijk en laten we zien hoe de wetenschappelijke methode bij ACA wordt gebruikt om een revolutie teweeg te brengen in de detectie van treinaankomsten voor een klant.
In deel 1. De wetenschappelijke methode onderzochten we de toepassing van de wetenschappelijke methode bij het oplossen van zakelijke uitdagingen. In deel 2 duiken we in een probleem uit de praktijk en laten we zien hoe de wetenschappelijke methode bij ACA wordt gebruikt om de detectie van treinaankomsten voor een klant revolutionair te verbeteren.
De reis begon met de vraag van een klant: "Kunnen we binnen een paar seconden nauwkeurig detecteren of treinen aankomen en vertrekken op een perron?". Om deze vraag te beantwoorden, pasten we de iteratieve aanpak van de wetenschappelijke methode toe, die vijf belangrijke stappen omvat:
Om een vraag als de bovenstaande op te lossen, zijn meestal een paar iteraties nodig om tot een volledig bevredigend resultaat te komen.
De onderzoeksvraag luidt als volgt: "Is het mogelijk om de aankomst en het vertrek van een trein op een perron te detecteren met de tijdresolutie van enkele seconden met behulp van een smartphone?". In de eerste stap is het belangrijk om het probleem te analyseren: het begrijpen van de eigenschappen van aankomst en vertrek. Rekening houdend met de beperkingen van het project, kunnen deze eigenschappen worden gemeten met behulp van de GPS-functionaliteit in een smartphone. Bovendien is de snelheid nauwkeurig beschikbaar in de ontvangen gegevens, omdat deze wordt gemeten met behulp van de dopplerverschuiving van de draaggolffrequenties.
In dit geval konden we vertrouwen op bestaande kennis en aannames, wat een solide uitgangspunt voor probleemoplossing bood. Als er geen bekende waarheden bestaan, moet je vooronderzoek doen. In dit geval konden we ons baseren op eerder werk.
Onze hypothese: "Als we de positie en snelheid met eenGPS verzamelen, kunnen we de aankomst en het vertrek op een platform betrouwbaar bepalen op basis van de positie- en snelheidskenmerken en met een goede tijdresolutie."
De hypothese is meetbaar, wat belangrijk is om een experiment op te zetten waarbij gelabelde gegevenspunten vergeleken kunnen worden met de voorspelde gegevens.
In stap 3 zetten we een proof of concept op dat zich richt op essentiële gegevens en de voorgestelde oplossing om onnodige details te vermijden voordat we de hypothese bewijzen. We ontwikkelden een app die aGPS-info en gelabelde snelheid opslaat voor rijden of stilstaan. Omdat we de beperkingen van aGPS kenden, pasten we filters toe die gebruik maakten van versnellingsmetergegevens, treinbeperkingen en voorspelde routes, waardoor de locatienauwkeurigheid aanzienlijk verbeterde. Dit resulteerde in een aanzienlijke verbetering van de locatiegegevens.
De resultaten van de experimenten:
Ondanks de goede aanvankelijke resultaten voldeed de voorgestelde oplossing niet aan de essentiële vereiste voor tijdresolutie. Het bouwen van een systeem met een consistente outputsnelheid wordt onhaalbaar tijdens het rijden in een enorme kooi van Faraday die signalen kan blokkeren.
De eerste iteratie voldeed niet aan de verwachtingen, maar dat ontmoedigde ons niet. We realiseerden ons de onoplettendheid in tijdresolutie. Bovendien pasten we in die tijd bij ACA met succes nieuwe technieken toe op een soortgelijk probleem.
De versnellingsmeter leverde betrouwbare gegevens en door deze te combineren met de gyroscoop en magnetometer verkregen we gerichte versnelling. Omdat we verschillende versnellingspatronen verwachtten voor verschillende vervoerswijzen en -toestanden, zoals stilstaan en rijden, besloten we een Naïve Bayes-algoritme te gebruiken. Dit algoritme voor leren onder toezicht creëert een probabilistische classificator die stilstand en rijden voorspelt op basis van gemeten eigenschappen.
Er ontstond een nieuwe hypothese: "Naïve Bayes classifier kan worden gebruikt om onderscheid te maken tussen het versnellingspatroon van lopen en de superpositie daarvan met een versnellingspatroon van een trein in beweging."
Er werd een applicatie gemaakt om gegevens te verzamelen die werden gelabeld met de juiste toestand. Vervolgens trainden we de Naïve Base-klassificator met behulp van verschillende gegevenskenmerken, zoals maximum, minimum, gemiddelde, norm, standaardafwijking, afstand tot het platform en minimaal vereiste snelheid.
Meerdere classifiers werden getraind, getest en beoordeeld met behulp van verwarringmatrices. De resultaten toonden aan dat rijden 94% van de tijd correct werd geïdentificeerd, maar dat stilstand slechts 48% van de tijd correct werd geïdentificeerd, waarbij de classificator stilstand in 52% van de gevallen ten onrechte als rijden bestempelde.

De Naïve Bayes classificeerders hadden niet de vereiste nauwkeurigheid voor ons probleem. De kenmerken overlapten elkaar aanzienlijk, waardoor geen onderscheid kon worden gemaakt tussen stilstaan en rijden. Bovendien konden de classificeerders de voorbijgaande aard van aankomst en vertrek niet nauwkeurig vastleggen, waardoor verder onderzoek naar een oplossing nodig was.
De vorige experimenten toonden aan dat snelheid en positie onvoldoende tijdsresolutie hadden en dat probabilistische modellen moeite hadden met de voorbijgaande aard van aankomst en vertrek. Nu we het belang van het voorbijgaande aspect inzien, is het duidelijk dat eigenschappen als snelheid of positie niet cruciaal zijn; in plaats daarvan is versnelling de sleutel. Aankomst kan worden gedefinieerd als een vertraging gevolgd door een periode zonder versnelling, terwijl vertrek een versnelling is die wordt voorafgegaan door een periode zonder versnelling.
Er werd een nieuwe hypothese geformuleerd: "Het is mogelijk om de voorbijgaande aard van aankomst en vertrek op een platform te gebruiken om de aankomst en het vertrek te detecteren met een goede tijdsresolutie en een goede nauwkeurigheid."
Om ons te richten op het gebruik van versnellingsmeterdata voor aankomst- en vertrekdetectie, gebruikten we data van de vorige iteratie, waarbij we een nieuw onderzoeksdomein betraden met als doel een signaalanalysealgoritme te bouwen voor classificatie.
In de volgende stappen worden meerdere grafieken toegevoegd. De rode achtergrond geeft aan dat de trein op het perron stond, groen geeft aan dat de trein in beweging was.
Bekijk de grafiek van het Y-kanaal van de versnellingsmeter. We kozen ervoor om de versnelling in eerste instantie niet te projecteren op de werkelijke as, om het in zijn ruwe vorm te houden en zo de benodigde rekenkracht te minimaliseren.
Er was niet veel te vertellen aan ons programma met deze gegevens, het ziet er voornamelijk willekeurig uit.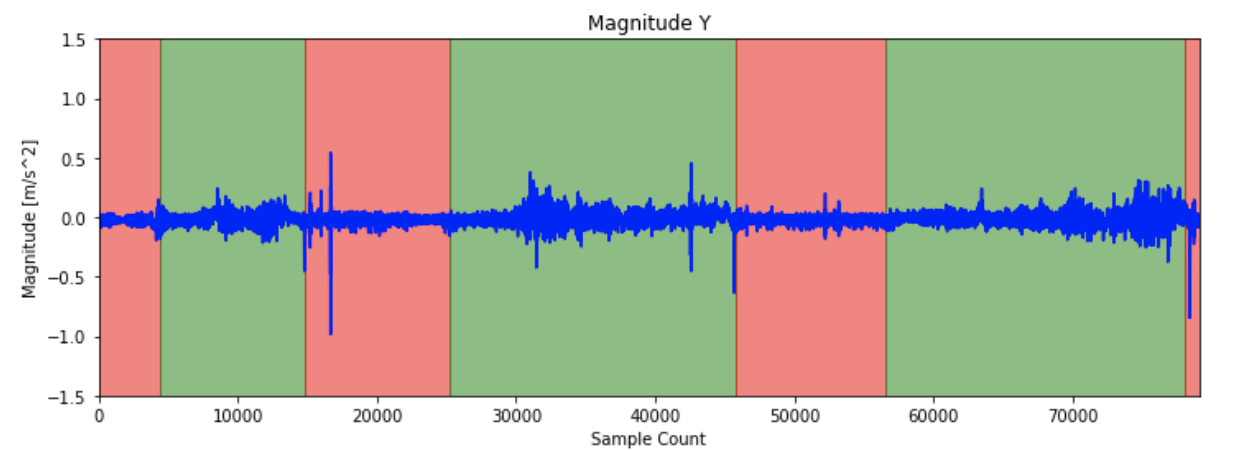
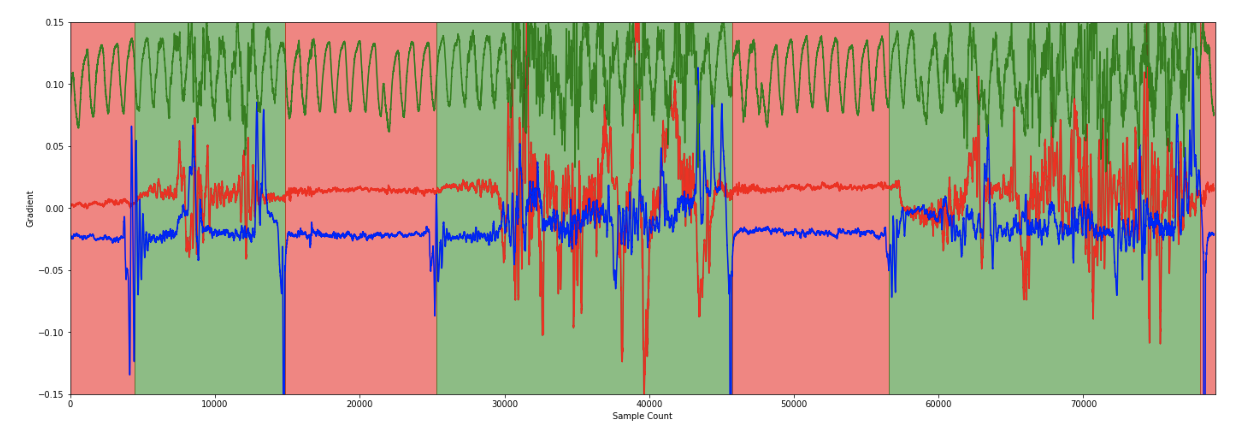
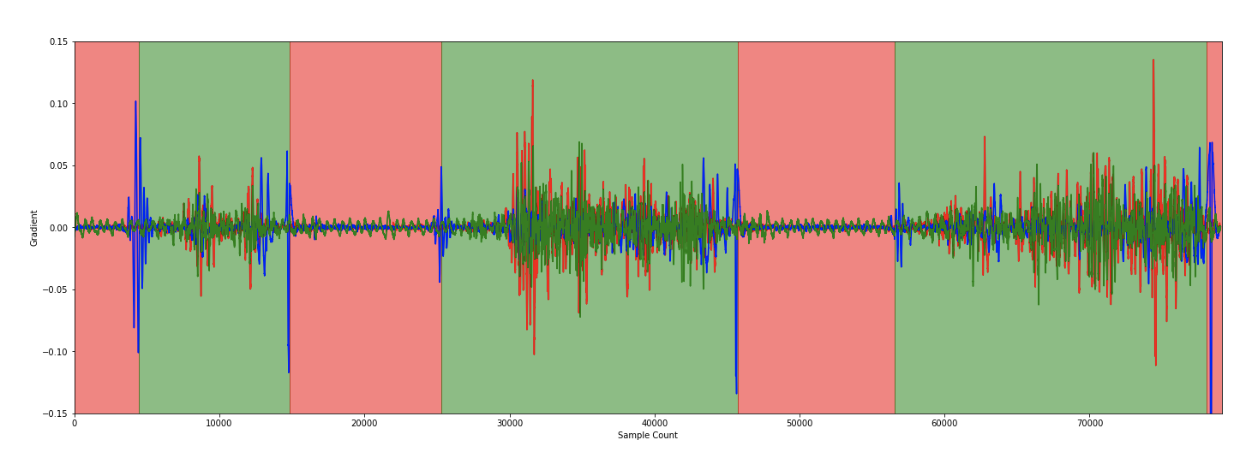
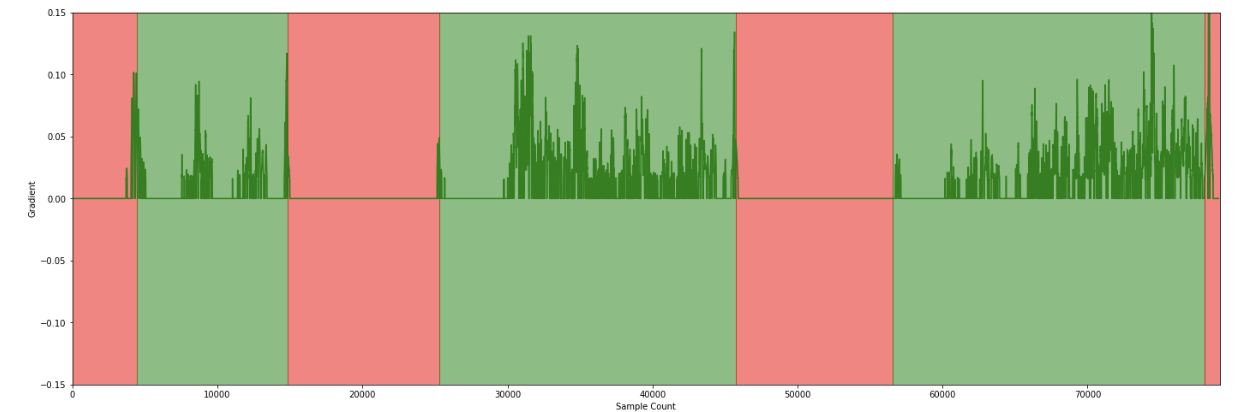
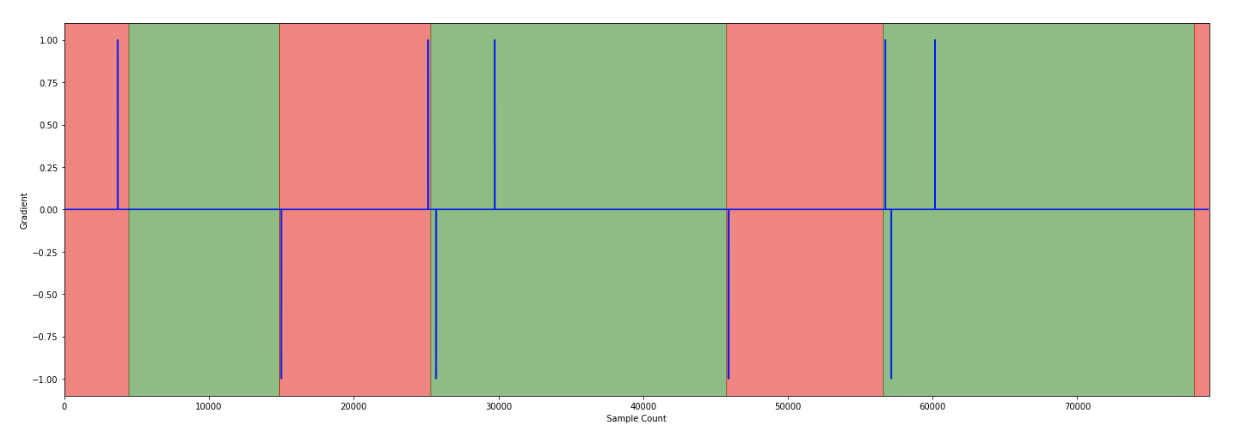
De gegevensanalyse vond voornamelijk plaats tijdens het experiment. Vervolgens werd ons algoritme getest met ongebruikte gegevens, waarbij enkele fout-positieven werden gevonden, maar geen fout-negatieven. Dit vergemakkelijkt het optimaliseren van de gegevens. Hoewel gegevens niet uit het niets gegenereerd kunnen worden, helpt het combineren van metingen met aGPS-gegevens om valse positieven uit te filteren.
Het algoritme dat in deze iteratie van de wetenschappelijke methode werd ontwikkeld, bewees onze laatste hypothese.
"Het is mogelijk om de voorbijgaande aard van aankomst en vertrek op een platform te gebruiken om de aankomst en het vertrek te detecteren met een goede tijdresolutie en een goede nauwkeurigheid."
In deze blogpost hebben we het volledige proces beschreven om een complex probleem met precisie op te lossen. Door middel van iteraties, leren van mislukkingen en het weggooien van veronderstelde kennis, hebben we een betrouwbare oplossing gemaakt.
Het algoritme, dat bekende wiskunde combineert met aGPS-gegevens, kan nauwkeurig de aankomst en het vertrek van treinen op een perron detecteren met alleen een smartphone, met een tijdresolutie van minder dan 1 seconde.
Liferay DXP is de afgelopen jaren uitgegroeid tot een veelgebruikt portaalplatform voor het bouwen en beheren van geavanceerde digitale ervaringen. Organisaties gebruiken het voor intranetten, klantportalen, self-service platforms en meer. Hoewel Lif
Lees verder

Op de hoogte blijven van de nieuwste trends en best practices is cruciaal in de snel evoluerende wereld van softwareontwikkeling. Innovatieve benaderingen zoals EventSourcing en CQRS kunnen ontwikkelaars in staat stellen flexibele, schaalbare en veil
Lees verder

Je kunt niet iets ontwerpen of ontwikkelen voor alle 7,9 miljard mensen op deze planeet. Dus als we aan een project beginnen, bepalen we een doelgroep om het te beperken. Van daaruit bouwen we onze functies en ontwerpen op een manier die geschikt lij
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
