.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

6 MEI 2025
Leestijd 4 min
Robin Janssens

Voordat we in detail treden, bespreken we eerst de rol van Event Storming in een agile context.Event Storming is de afgelopen jaren een zeer populaire methodologie geworden en heeft zijn plaats gevonden in de levenscyclus van softwareontwikkeling als techniek voor het verzamelen van vereisten.

Event Storming werd in 2012 ontwikkeld doorAlberto Brandolini als een alternatief voor nauwkeurige UML-diagrammen. Hetis een workshopachtige techniek die projectstakeholders samenbrengt (zowel ontwikkelaars als niet-technische gebruikers) om complexe bedrijfsdomeinen te verkennen in domeingedreven ontwerparchitectuur.
Een van de sterke punten van Event Storming is dat het zich kan richten op de zakelijke belanghebbenden en het hoge interactieniveau. De techniek is eenvoudig en vereist geen enkele technische training.
Met Event Storming kun je verschillende doelen nastreven:
Er zijn drie primaire abstractieniveaus voor Event Storming:
Bij het toepassen van Event Storming moet je eerst de Domain Events in het probleemdomein identificeren op een tijdlijn. De bron van een Domain Event kan het volgende zijn:
Vervolgens schrijven we deze domeingebeurtenis op een oranje sticky note.

Als alle domeingebeurtenissen gedefinieerd zijn, is de tweede stap het vinden van de opdracht die deze domeingebeurtenissen heeft veroorzaakt. Opdrachten worden op blauwe briefjes geschreven en direct voor de bijbehorende domeingebeurtenis geplaatst. Tenslotte moet je de aggregaten identificeren waarbinnen commando's worden uitgevoerd en waar gebeurtenissen plaatsvinden. Deze aggregaten worden op gele plakbriefjes geschreven.
In de afgelopen jaren hebben we Event Storming omarmd als een techniek voor het verzamelen van vereisten binnen ACA-IT Solutions - zozeer zelfs, dat het nu een geïntegreerd onderdeel is van ons portfolio en de manier waarop we software ontwikkelen voor onze klanten. Als u daar meer over wilt weten of als u meer wilt weten over Event Storming, kunt uhier contact met ons opnemen.
De System Modeler gebruikt EventStorming als inspiratie voor het documenteren (modelleren) van de gebeurtenissen die bedrijfsprocessen vertegenwoordigen, het configureren van high-level eigenschappen die aan deze gebeurtenissen zijn gekoppeld en vervolgens het automatisch genereren van Apps en Collaboration Types vanuit het model.
Een System Modeler sessie omvat het gebruik van vijf virtuele sticky notes om te representeren:
De System Modeler maakt ook gebruik van één container:
Hieronder ziet u het resultaat van een EventStorming-sessie in de System Modeler, die het melding- en volgsysteem voor gaten in het wegdek van een stad voorstelt. Het model vertegenwoordigt:
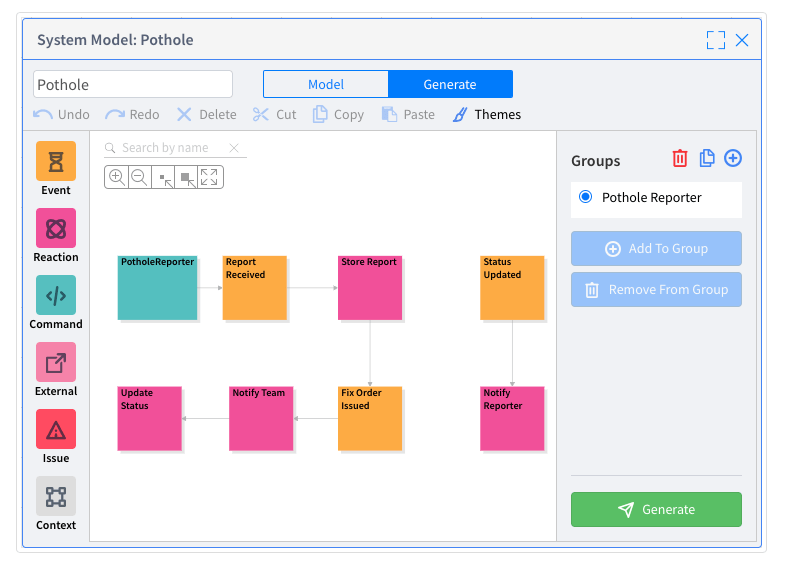
System Modeler is een geweldige manier om de kloof te overbruggen tussen het verzamelen van requirements voor een event-driven applicatie en de daadwerkelijke implementatie. In dit geval doen we dat elektronisch op het canvas. Bovendien is dit een samenwerkingsomgeving, waardoor meerdere mensen tegelijkertijd aan dit model kunnen werken. Met de System Modeler kunnen gebruikers samenwerken met meerdere personen, niet alleen in een bepaalde ruimte, maar op een willekeurig aantal geografische locaties. Dit is een geweldige manier om echt een soort gedistribueerde requirements gathering sessie te doen. Zeker nu de pandemie veel mensen ervan weerhoudt om naar kantoor te gaan!
Op basis van deze sessie voor het verzamelen van vereisten kunnen we nu dit vereistenmodel gebruiken en een toepassing maken. Het enige wat gebruikers hoeven te doen is overschakelen van de 'modelmodus' naar de 'genereermodus' en de verschillende elementen groeperen. Nadat de onderwerpen en samenwerkingstaken zijn gedefinieerd, hoeft u alleen maar op de knop Genereren te klikken.Deze eenvoudige handeling alleen al genereert ongeveer 70% van de code van deze specifieke applicatie! Dit maakt System Modeler waarschijnlijk de eenvoudigste manier om zeer snel van het ontwerpen van applicatie-eisen over te gaan op de ontwikkeling van de applicatie zelf.
Moderne applicaties moeten in real-time werken, omdat ze worden aangestuurd door wat er op dat moment in de echte wereld gebeurt. Ze moeten gemakkelijk kunstmatige intelligentie en IoT-technologie integreren en de applicaties zelf moeten worden gedistribueerd bij de bron van de gebeurtenissen. De softwarelogica moet overal kunnen draaien (cloud, edge, on-premises). Voor deze toepassingen is het ook nodig om mensen in het proces te integreren wanneer een hoger niveau van intuïtie en redenering nodig is. Met System Modeler is het eenvoudig om snel een zeer groot deel van zo'n applicatie te genereren. De System Modeler heeft immers de mogelijkheid om requirements te verzamelen van zakelijke gebruikers, domeinexperts en ontwikkelaars en deze requirements zeer snel om te zetten in een draaiende event-driven applicatie. Het maken van deze supersnelle POC's is een koud kunstje!
Als u meer wilt weten over hoe ACA Group en event-driven technologie uw digitale transformatie kunnen versnellen, neem dan contact met ons op!


Tijdens de TVH IT Talks 205 deelde Greg Van Dorpe (Low-Code Offering Lead) ACA’s visie op het huidige IT-landschap met een zaal vol betrokken deelnemers. Hij benadrukte de realiteit die veel teams herkennen: stijgende verwachtingen, een tekort aan ta
Lees verder

Bij de ontwikkeling van software kunnen aannames ernstige gevolgen hebben en we moeten altijd op onze hoede zijn. In deze blogpost bespreken we hoe je omgaat met aannames bij het ontwikkelen van software. Stel je voor... je rijdt naar een bepaalde pl
Lees verder

ACA doet veel projecten. In het laatste kwartaal van 2017 deden we een vrij klein project voor een klant in de financiële sector. De deadline voor het project was eind november en onze klant werd eind september ongerust. We hadden er echter alle vert
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
