.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 8 min
Bregt Coenen

Om deze alternatieve aanpak te implementeren, zijn er een paar vereisten waaraan voldaan moet worden:
Laten we aannemen dat je applicatie een StatefulSet gebruikt die er ongeveer zo uitziet:
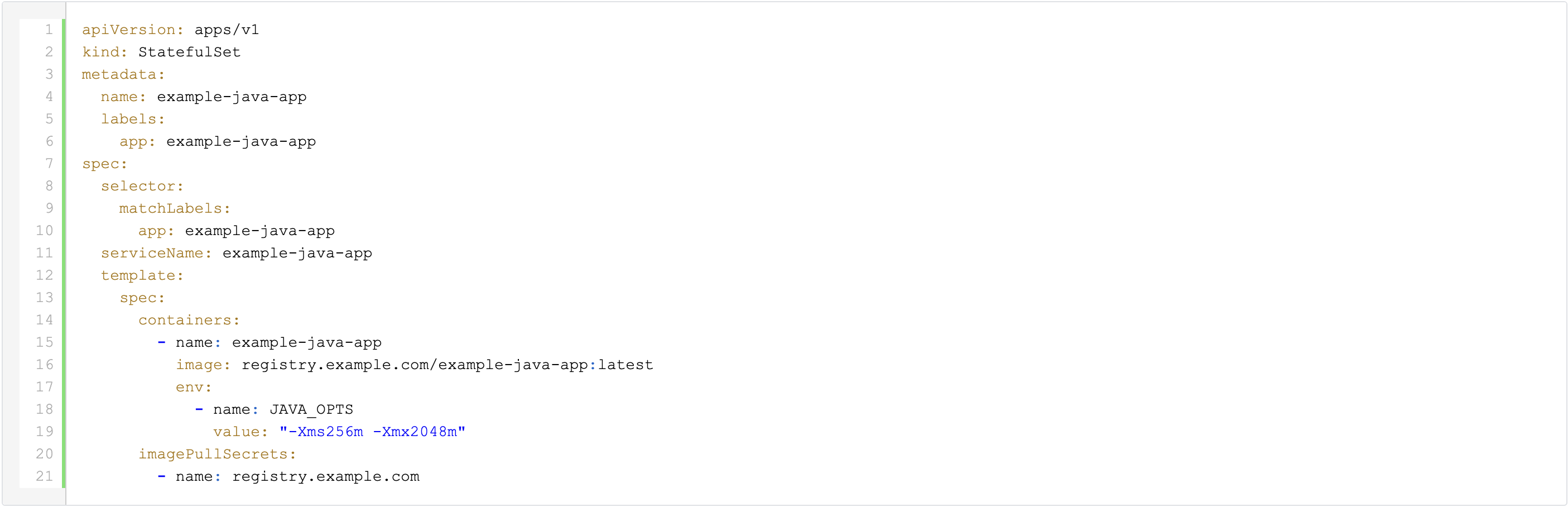
De naam van de JAVA_OPTS omgevingsvariabele kan variëren afhankelijk van de specifieke applicatie.
Om het implementatieproces te vereenvoudigen, maken we een aangepast image dat de New Relic agent jar bevat. Om dit image te maken, gebruiken we een Container File, die er ongeveer zo uit kan zien:

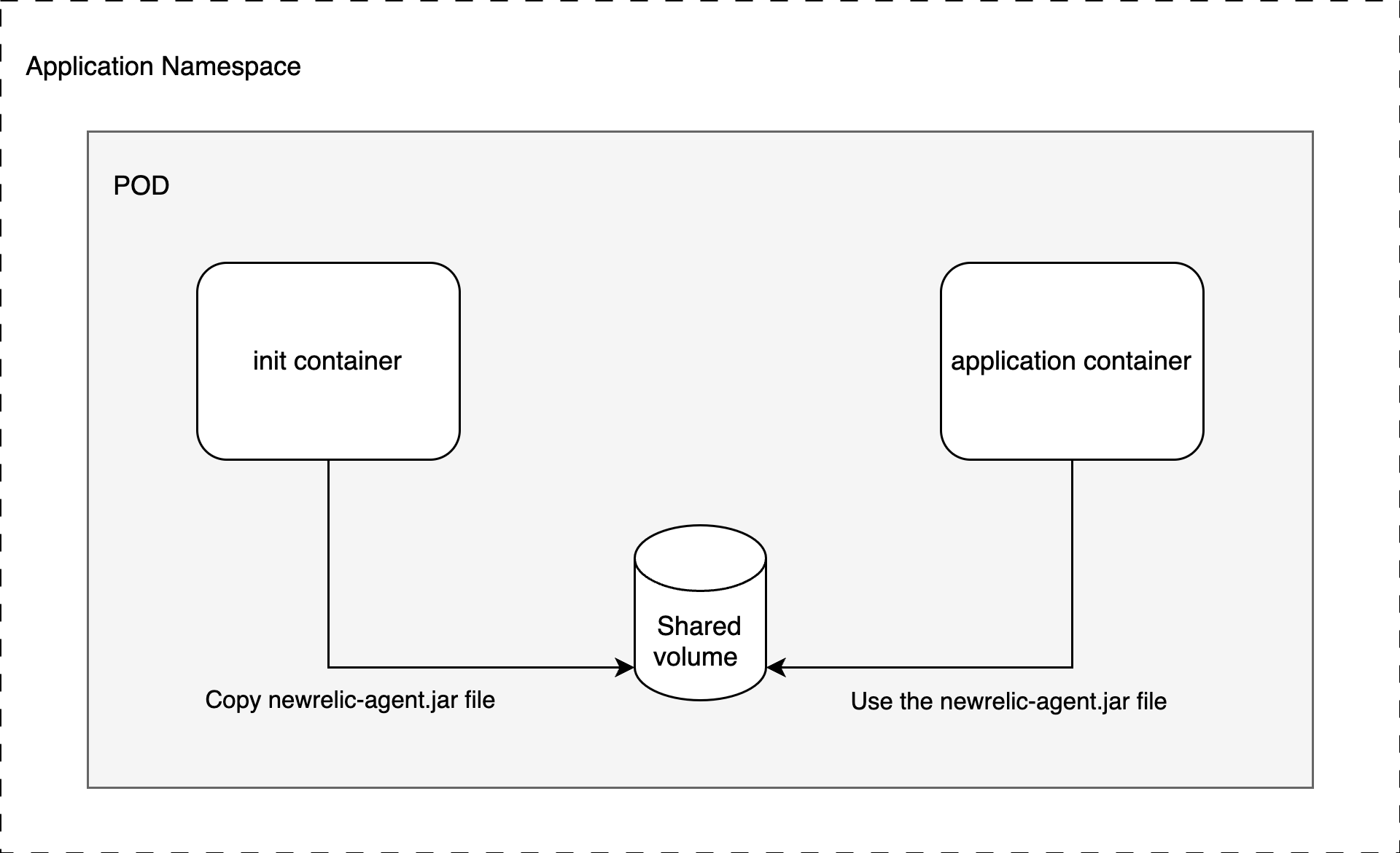
Om de applicatie de New Relic agent jar te laten gebruiken, maken we gebruik van de concepten Kubernetes Init Container en emptyDir.
De resulterende StatefulSet ziet er als volgt uit:
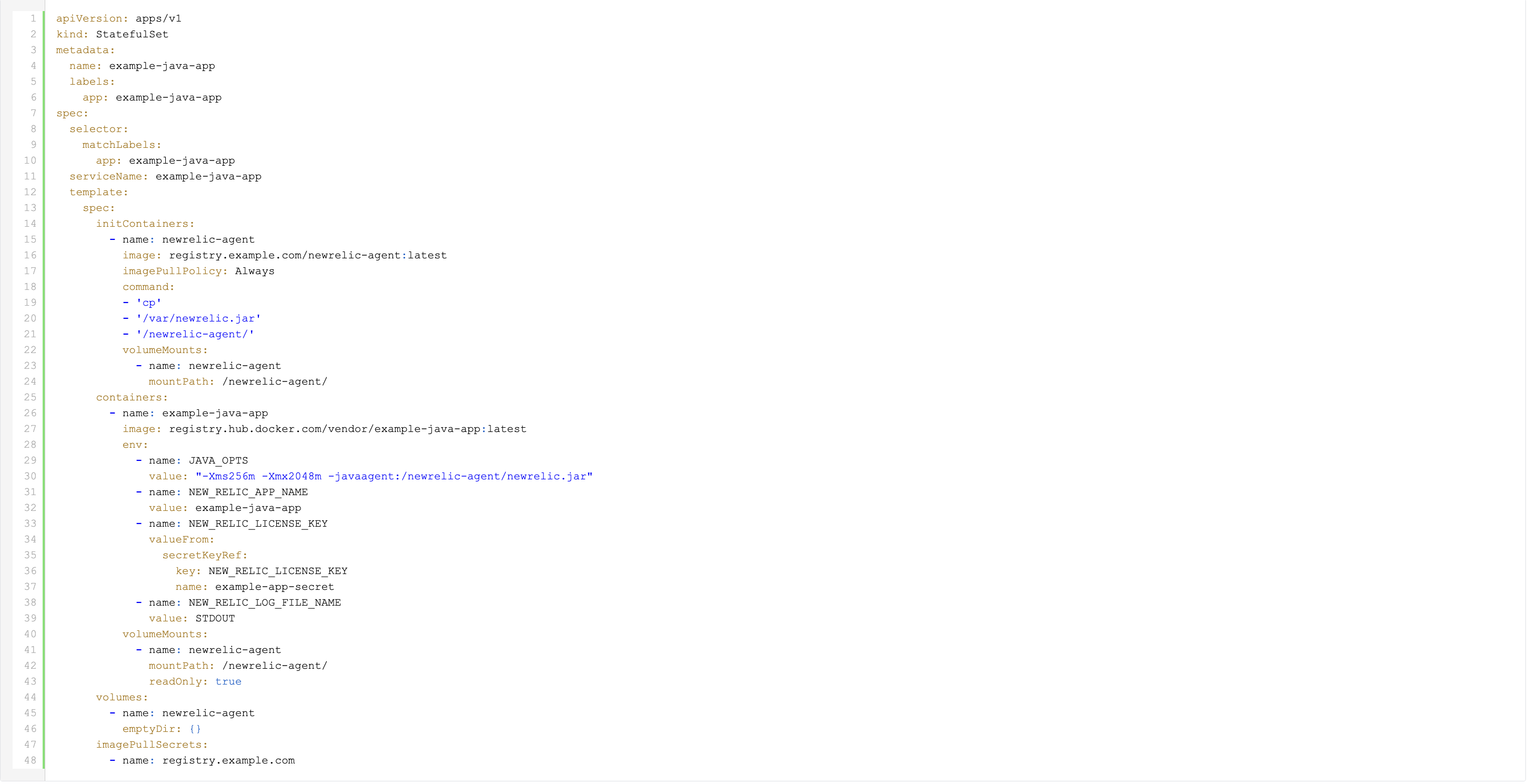
In plaats van de New Relic agent jar in de applicatie-image op te nemen, gebruiken we onze aangepaste newrelic-agent image als een Init Container. Deze container kopieert het newrelic.jar bestand naar een emptyDir volume.
Aangezien de Init Container vóór de gewone applicatiecontainer draait en beide hetzelfde volume delen, is het newrelic.jar-bestand toegankelijk wanneer de JVM start.
Afgezien van het gedeelde volume, hebben we een paar New Relic agent-specifieke omgevingsvariabelen nodig:
Er zijn een paar extra omgevingsvariabelen beschikbaar in de New Relic Java agent documentatie die gebruikt kunnen worden.
Naast deze basisconfiguratie kun je ook de configuratie van de New Relic server-side agent gebruiken.
Zoals je kunt zien in de JAVA_OPTS omgevingsvariabele, moeten we nog steeds de JVM instrueren om de New Relic agent jar te gebruiken. Het is de moeite waard om te vermelden dat dit specifieke bestand zich op het gedeelde volume bevindt.
Let ook op de "imagePullPolicy" die we hebben ingesteld op "Always" om ervoor te zorgen dat we altijd de laatste image-versie ophalen, zelfs als deze nog steeds dezelfde tag gebruikt.
Om ervoor te zorgen dat de New Relic agent altijd up-to-date is, kun je een Continuous Integration pipeline opzetten die automatisch een nieuwe container image bouwt wanneer er een nieuwe agent versie beschikbaar komt.
Daarnaast kun je de image taggen met major, major.minor, en major.minor.patch, naast "latest". Hierdoor kun je de agentversie vastpinnen op basis van de specifieke vereisten van je toepassing.
Afhankelijk van de image tag die gespecificeerd is in het manifest bestand van de applicatie, kan het updaten net zo eenvoudig zijn als het herstarten van de applicatie pods.
Als je er de voorkeur aan geeft om de New Relic agent vast te zetten op een specifieke versie, moet je de newrelic-agent image tag in de StatefulSet bijwerken en deze wijziging implementeren in je Kubernetes cluster.
In ieder geval hoef je niet langer een aangepaste image te bouwen om de New Relic agent jar toe te voegen, wat frequentere updates van de agent mogelijk zou moeten maken.
Wil je meer ontdekken over Kubernetes?


CloudBrew is altijd een hoogtepunt op onze kalender geweest, maar de editie van 2025 voelde anders. Misschien lag het aan de timing. Slechts een maand eerder, in november 2025, opende de Azure Belgium Central-regio eindelijk haar deuren. ACA opereert
Lees verder

Een betere uptime, lagere kosten en vendor lock-in vermijden. Dat zijn drie van de redenen waarom onze klanten kiezen voor een multicloud-strategie. Onze Cloud project manager Roel Van Steenberghe legt uit wat zo’n strategie precies inhoudt en wat de
Lees verder

In de complexe wereld van moderne softwareontwikkeling worden bedrijven geconfronteerd met de uitdaging om verschillende applicaties die door verschillende teams worden ontwikkeld en beheerd, naadloos te integreren. De Service Mesh is van onschatbare
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
