.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 7 min
Shari Paret

Geautomatiseerd testen, mits goed uitgevoerd, elimineert het verhoogde risico en de extra problemen die handmatig testen met zich meebrengt. In deze blogpost ontkrachten we het misplaatste geloof dat handmatig testen en bewijs verzamelen veel waarde toevoegt.
Bij ACA werken we volgens een agile methodologie. Daarom werken we nauw samen met onze klanten om oplossingen te leveren die hunechte bedrijfsproblemen oplossen. Bovendien streven we ernaar ze snel op te lossen. Deze aanpak heeft keer op keer zijn waarde bewezen, omdat er zo snel mogelijk zoveel mogelijk feedback wordt verzameld.
Sommige klanten dwingen van oudsher grondige handmatige gebruikersacceptatietests af vlak voordat een softwareverandering live kan gaan. De reden ligt voor de hand: hun bedrijf is sterk afhankelijk van deze software, dus alle risico's en financiële gevolgen moeten worden uitgesloten. Dus handmatig testen nadat alle ontwikkeling is voltooid is heel logisch, toch?
Of toch niet? Ons team is er vaak getuige van geweest dat handmatig testen indirectmeer risico's en problemen veroorzaakt, in plaats van minder! We zouden zelfs zo ver willen gaan om te zeggen dathet als een virus is. Een virus dat elk onderdeel van de organisatie infecteert, vaak volledig onopgemerkt! Hoe is dit mogelijk? Omdat handmatig testen niet alleen de eindcontrole is die het had moeten zijn. Het is eenproces. Een proces dat de manier stuurt waarop je change management uitvoert, de manier waarop je resources plant en de manier waarop je verantwoordelijkheid toewijst en verschuift.
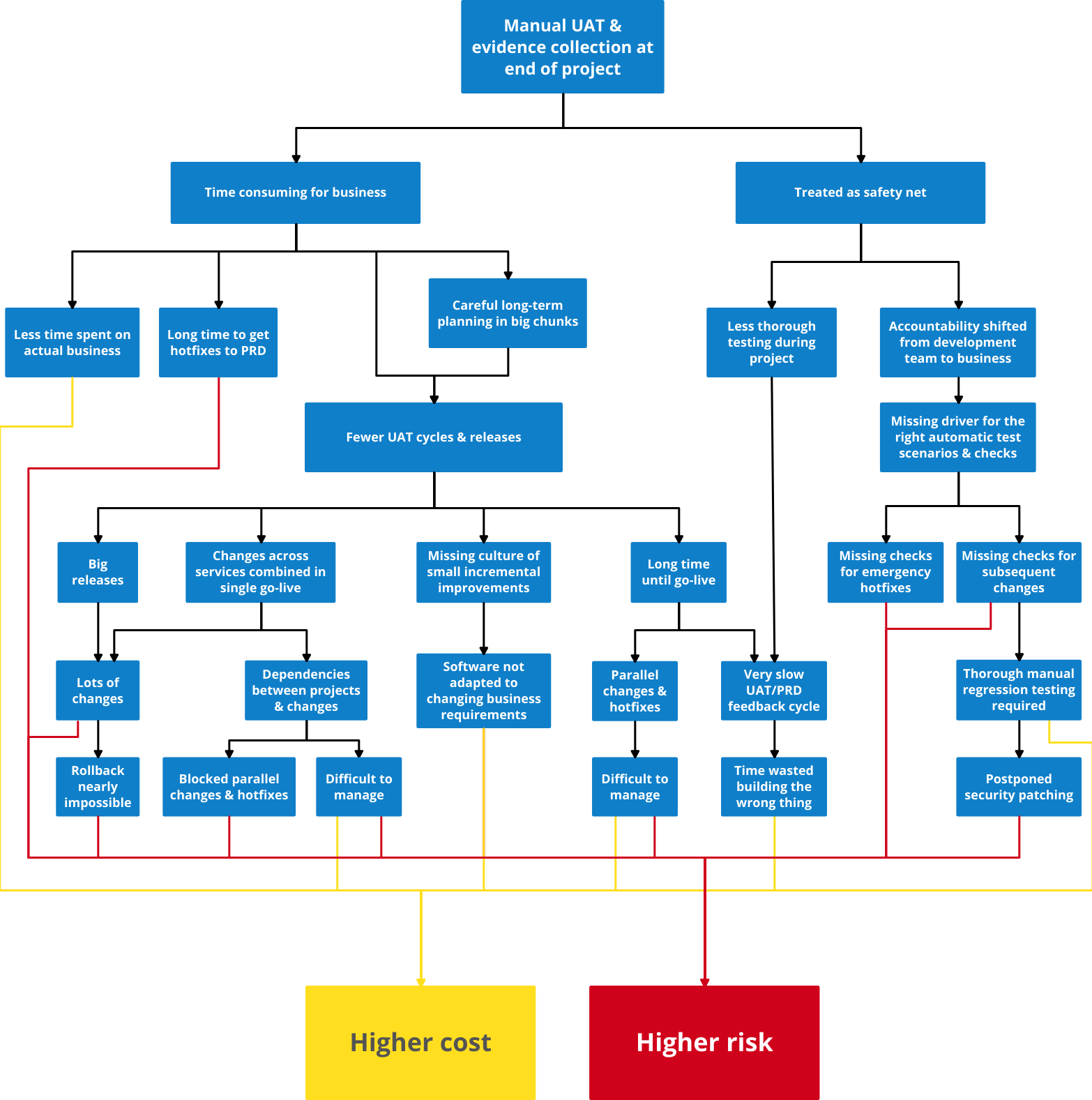
Volkomen duidelijk, toch?

Misschien niet. Laat ik het samenvatten:
Dit alles kost echt geld en brengt echte risico's met zich mee!
In plaats van elk probleem bij de bladeren aan te pakken, probeerden we een relatief kleine actie te ondernemen om het probleem bij de wortel aan te pakken. We probeerden het misplaatste geloof weg te nemen dat dit soort handmatig testen en handmatig bewijs verzamelen veel waarde toevoegt.
We hadden al een enorme hoeveelheid geautomatiseerde tests als onderdeel van onze levenscyclus van testgestuurde ontwikkeling. Dus hoe konden we deze gaan gebruiken? We begonnen met het uitleggen van onze huidige testgewoonten aan de zakelijke gebruikers. Daarna zijn we voor een concreet project samen scenario's gaan definiëren en tot slot hebben we ze continu inzicht gegeven in de resultaten.
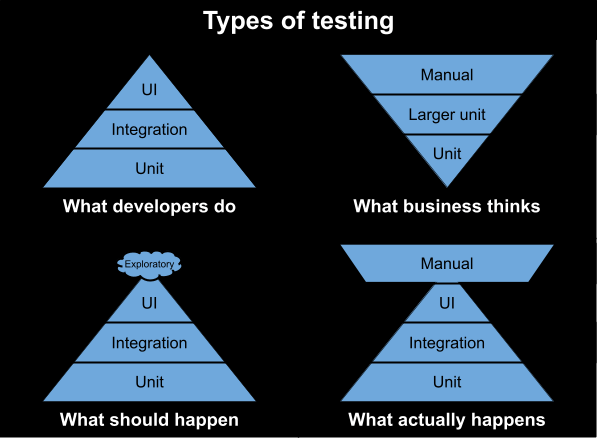
Welke soorten geautomatiseerde tests zijn er al? Welke garanties bieden ze? En welke garanties bieden zeniet?
De business houdt zich bezig met hun business. Ze kennen de applicatiearchitectuur niet, laat staan wat een geautomatiseerde test eigenlijkis. Je kunt ( de meeste) geautomatiseerde tests nietzien, dus hoe kun je ze ooit vertrouwen? Daarom gaat het bij het verminderen van de afhankelijkheid van handmatig testen niet om het veranderen van enkele werkwijzen en het toevoegen van enkele controles.In de kern gaat het omhet verschaffen van inzicht en het verdienen van vertrouwen.
Meer specifiek hebben we het volgende uitgelegd:
Onze bedrijfsdomeinlaag is volledig onbewust van technologie of infrastructuur, dus die dingen kunnen onmogelijk de garanties doorbreken die door de tests op deze laag worden gegeven.
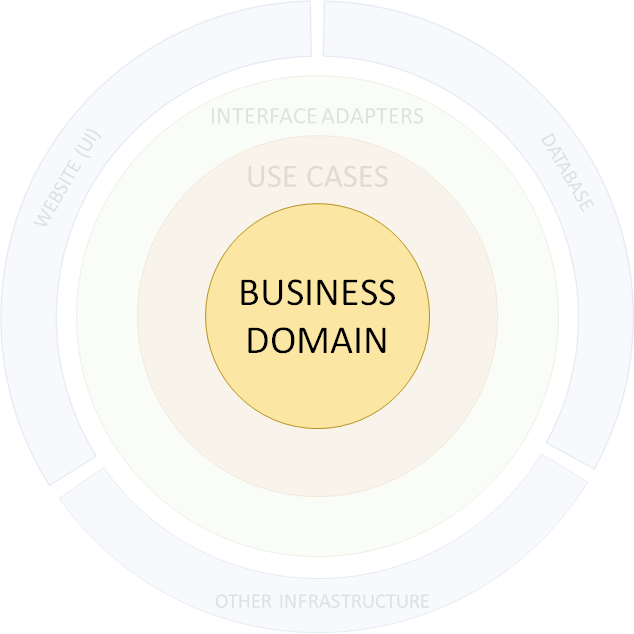
Onze use-case laag vertrouwt alleen op infrastructuur in high-level business termen, bijvoorbeeld op iets dat dingen kan 'opslaan' of 'vinden'. De tests garanderen correcte resultaten voor de acties en queries in deze laag,gegeven de correcte infrastructuur.
Concrete technologie/infrastructuur keuzes zijn plugins aan de rand van onze applicaties, op dezelfde manier als een printer in een computer wordt geplugd: Excel kent het model van je printer niet, het weet alleen dat het kan afdrukken. Als de plugins ('printer') werken, zullen de use cases (acties en query's) ook werken.
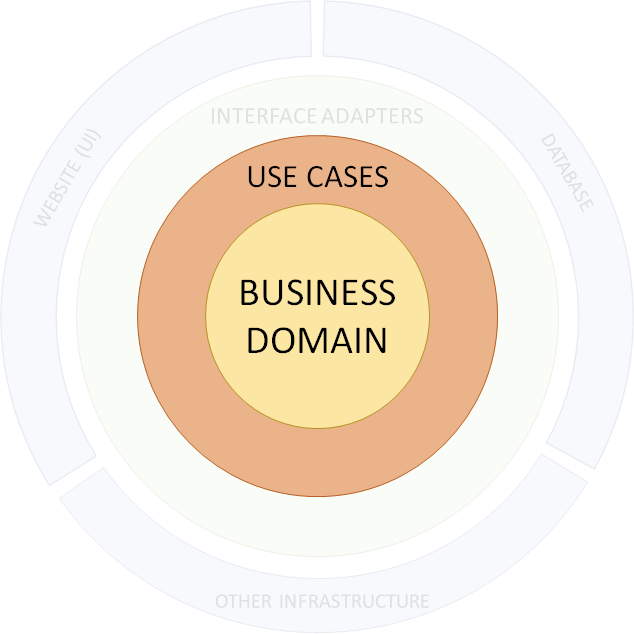
We testen alle lagen ook samen met click-through-UI-tests. Omdat ze visueel kunnen worden weergegeven en alle onderdelen in de integratie omvatten, bieden deze tests veel vertrouwen voor de business.
Er zijn enkele hiaten in onze geautomatiseerde teststrategie. Sommige integraties met infrastructuur of externe services kunnen niet gemakkelijk op een geautomatiseerde manier worden geverifieerd. Hier moet de nadruk liggen op handmatig testen.
Het bedrijf moet zijn tijd niet verspillen door te controleren of er een bepaald bericht verschijnt wanneer je op een bepaalde knop klikt.
Het doel is niet om zakelijke gebruikers in ontwikkelaars te veranderen, maar om hen te laten zien waarom het vertrouwen van ontwikkelaars in deze tests vanzelfsprekend is. Dus in plaats van ze te overstelpen met technische details, vraag waar ze zich zorgen over maken en geef geduldig antwoord. Ze zullen zich niet alle details herinneren en dat hoeft ook niet. Maar het vertrouwen zal blijven. En pas als ze het vertrouwen hebben verdiend, zullen ze accepteren dat hun testgewoonten veranderen. Sterker nog, we hebben gemerkt dat ze er zelf om vragen!
Welke scenario's zijn bedrijfskritisch? Welke controles zijn nodig om voldoende vertrouwen te geven om live te gaan? Dit zijn vragen die we nu behandelen tijdens het uitwerken van story's. Als gevolg daarvan zijn de resulterende geautomatiseerde tests nu een deliverable van elke story geworden.
Handmatige tests richten zich vaak op lange, end-to-end bedrijfsprocessen. Zelfs als bewezen is dat elk onderdeel van het proces op zichzelf perfect werkt en u bent degene die de schakelaar in productie omzet: zouu zich 100% zeker voelen ? Voor degenen die dapper genoeg zijn om ja te antwoorden: het is ofwel omdat je alles tot in detail weet, of je weet niet genoeg!
Daarom hebben we ons gericht op dezelfde end-to-end bedrijfsstromen, gesimuleerd door te klikken via de geïntegreerde applicatie (met uitzondering van slechts enkele kleine externe services).
De juiste geautomatiseerde testscenario's waren nu bepaald, maar hoe konden de zakelijke gebruikers weten dat deze correct waren geïmplementeerd? En hoe konden we ze het bewijs leveren dat ze moesten documenteren? Daarom introduceerden we als laatste stap een gedetailleerd testrapport met alle uitgevoerde stappen in de vormvan Gegeven-Wanneer-Dan.
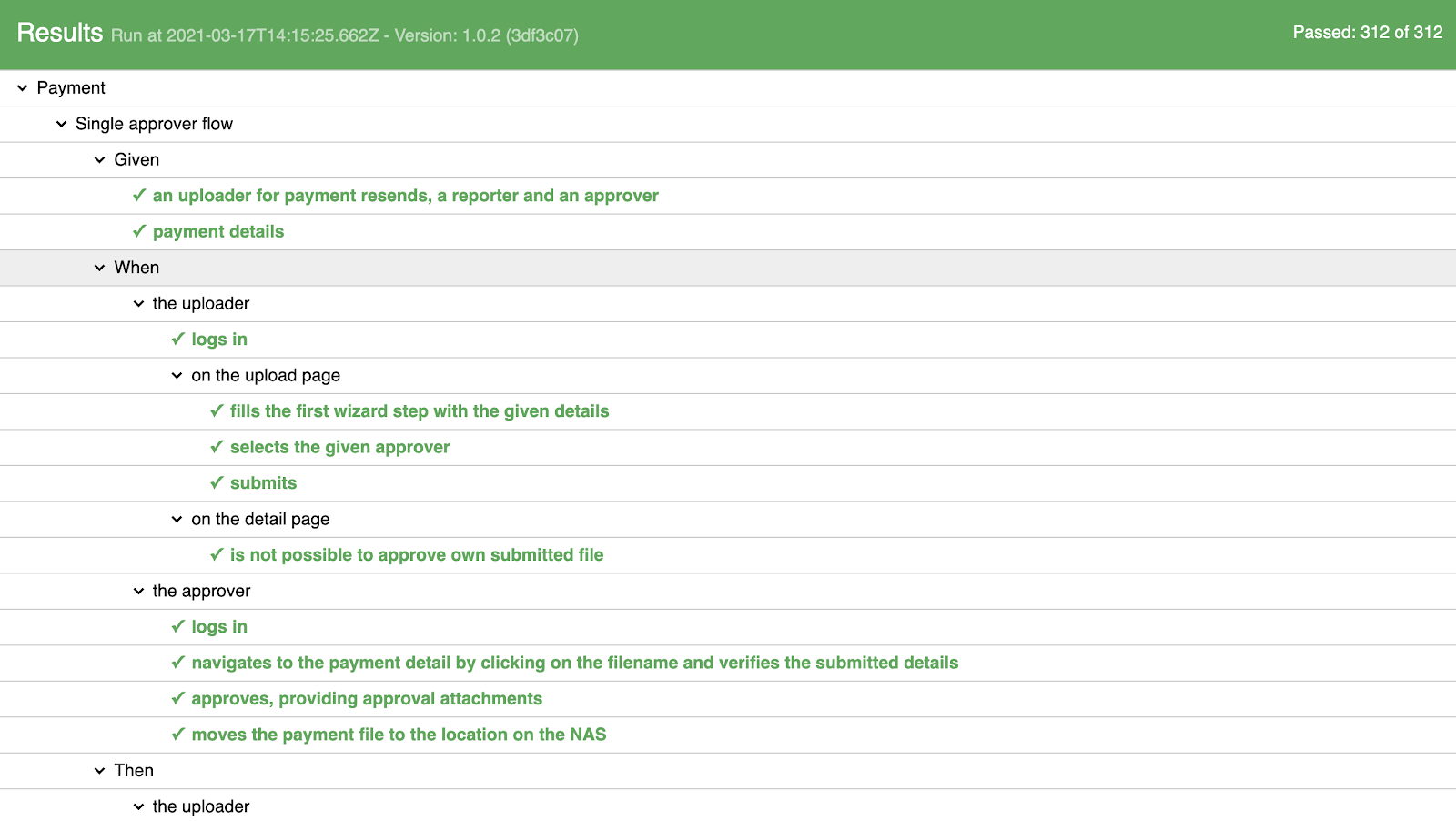
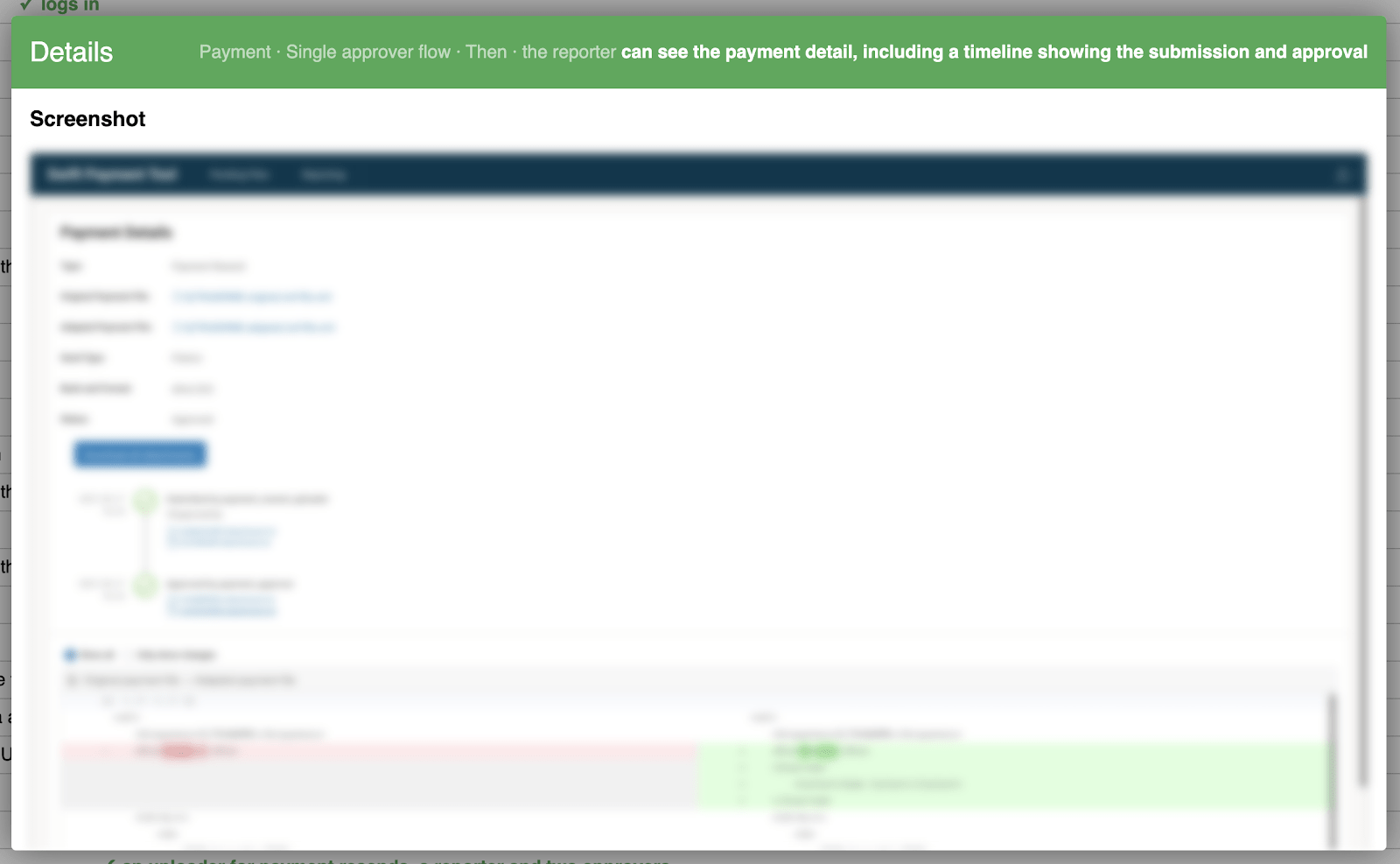
Als je op een stap klikt, wordt een pop-up geopend met schermafbeeldingen en een logboek van alle uitgevoerde controles. Dit geeft onze zakelijke gebruikers bewijs en vertrouwen dat de juiste dingen zijn gecontroleerd.
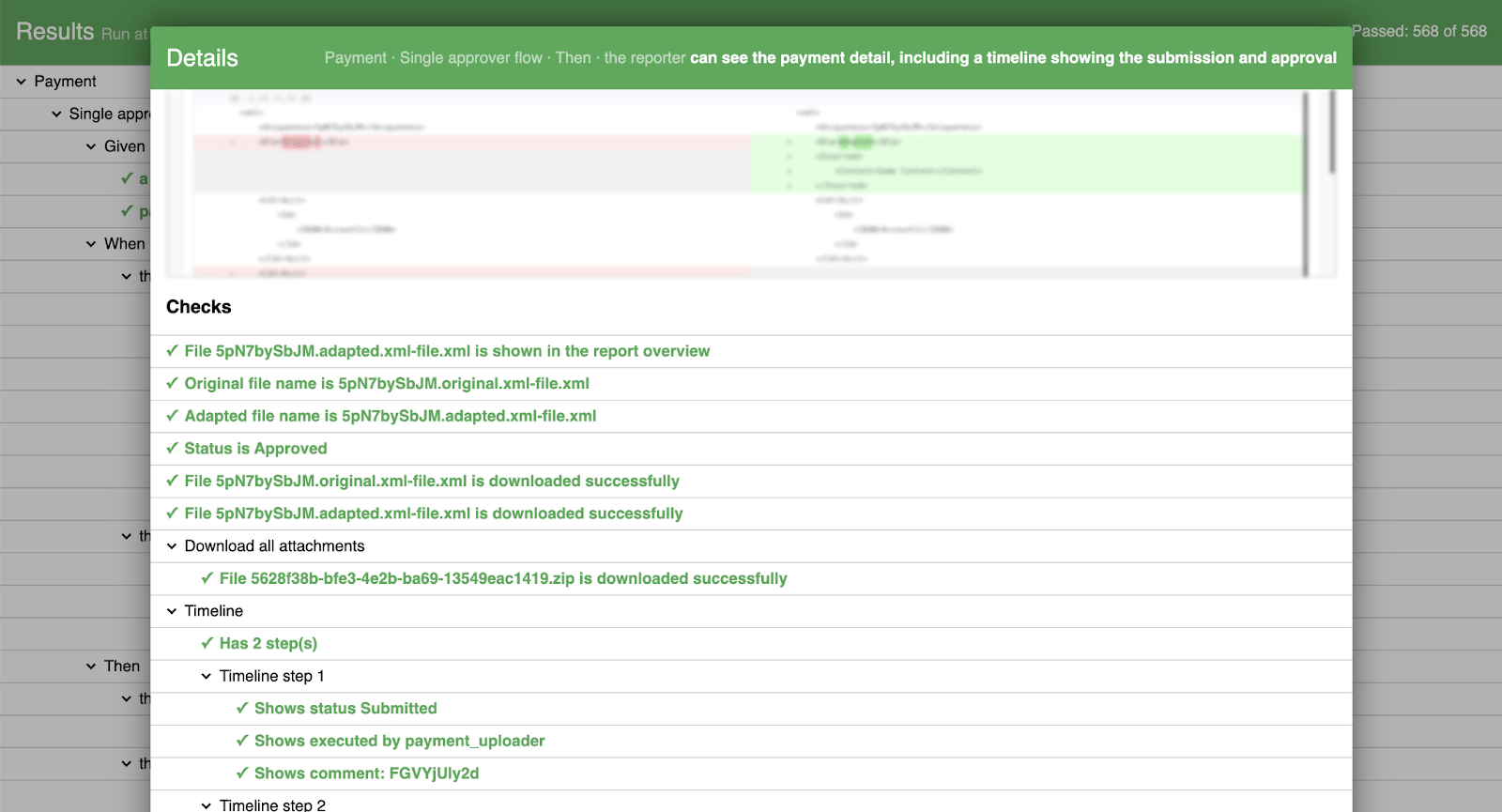
We hebben deze nieuwe manier van samenwerken ongeveer 6 maanden geleden geïntroduceerd, voor meerdere ontwikkelingsgolven van een nieuwe applicatie. Tijdens dit project hebben we veel positieve effecten gemerkt:
Hoewel we ongelooflijk positief zijn over deze nieuwe manier van werken, zijn er nog enkele valkuilen waar we voor moeten oppassen.
We vinden deze nieuwe manier van werken een enorme verbetering, maar het is nog maar het begin. We zien de volgende volgende volgende stappen:
Wat vindt u ervan? Wat vind je (niet) goed aan onze aanpak? Laat het ons weten!


Bij de ontwikkeling van software kunnen aannames ernstige gevolgen hebben en we moeten altijd op onze hoede zijn. In deze blogpost bespreken we hoe je omgaat met aannames bij het ontwikkelen van software. Stel je voor... je rijdt naar een bepaalde pl
Lees verder

ACA doet veel projecten. In het laatste kwartaal van 2017 deden we een vrij klein project voor een klant in de financiële sector. De deadline voor het project was eind november en onze klant werd eind september ongerust. We hadden er echter alle vert
Lees verder

OutSystems: een katalysator voor bedrijfsinnovatie In het snelle zakelijke landschap van vandaag de dag moeten organisaties innovatieve oplossingen omarmen om voorop te blijven lopen. Er zijn veel strategische technologische trends die cruciale bedri
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
