.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 4 min
Robin Janssens




Enkele verschillen:
Je herkent deze situatie misschien wel: als je applicatie groeit, groeit de diversiteit aan elementen mee. Knoppen op verschillende pagina's staan net iets anders of niet precies op dezelfde plek, pictogrammen behoren niet allemaal tot dezelfde set, nieuwere formulieren volgen niet dezelfde structuur als vorige, er zijn verschillende lettertypen of -groottes voor hetzelfde doel, enzovoort. Dat is vervelend en ronduit rommelig.
Het is nog erger als deze inconsistentie ervoor zorgt dat je applicatie volgens je gebruikers niet meer werkt zoals verwacht omdat er ook te weinig consistentie is in de interactiepatronen. Dit kan ertoe leiden dat gebruikers je applicatie of een deel ervan steeds minder gebruiken of er zelfs niet meer mee werken.
"Consistentie" is een belangrijke metriek die de meeste bedrijven onderschatten. Consistentie is een cruciaal onderdeel van elk bedrijf met een digitaal platform of dienst. Het zorgt niet alleen voor een gebruiksvriendelijk product, maar ook voor tal van andere voordelen, zoals: een uniforme ervaring op verschillende apparaten, correcte implementatie van branding, merkbekendheid en nog veel meer... We erkennen allemaal het belang van die consistentie, maar hoe kun je er nu voor zorgen dat je dit ook binnen je organisatie waarborgt?
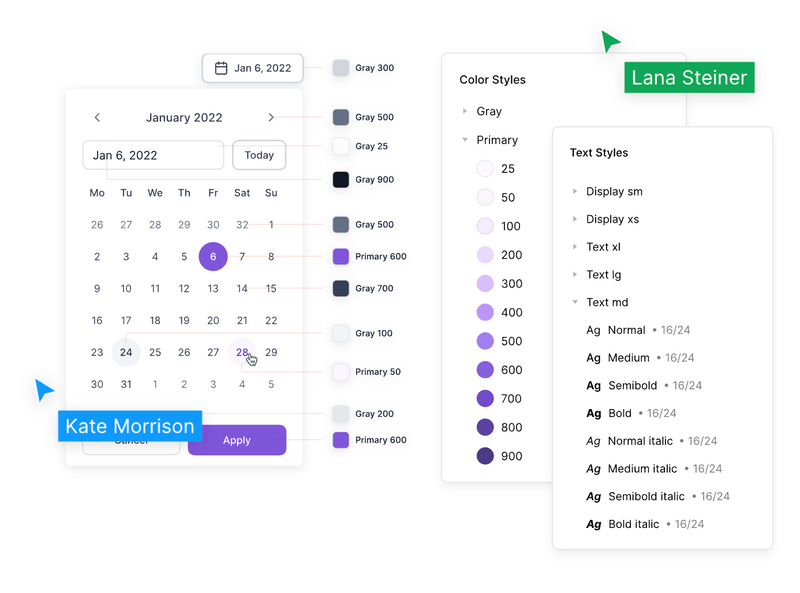
Een ontwerpsysteem is een centrale plek waar alle onderdelen van een digitaal product of set van digitale producten worden beschreven. Je kunt het zien als een soort bibliotheek waarin verschillende visuele componenten zijn opgeslagen voor gebruik in je website, app of social media content. Kleur en typografie zijn primaire componenten in een design systeem, net als knoppen, formulieren, voetteksten en andere componenten.

Ontwerpsysteem 'Atomus', gratis beschikbaar binnen Figma
Het gebruik van een ontwerpsysteem heeft 3 grote voordelen:
Een ontwerpsysteem helpt bij het creëren van een consistent merkimago. Als je eenmaal een ontwerpsysteem hebt gemaakt, wordt het de "enige bron van waarheid" voor je visuele identiteit. Iedereen kan ontwerpen maken die er hetzelfde uitzien, hetzelfde aanvoelen en volgens dezelfde interactiepatronen werken.
Je team kan snel nieuwe componenten ontwerpen op basis van bestaande kleinere elementen die atomen worden genoemd. Je kunt je huidige atomen dus altijd hergebruiken om nieuwe dingen te maken die meteen passen binnen het ontwerp en de look & feel van je ontwerpsysteem.
Bestaande of nieuwe collega's die minder ervaring hebben met UX- of UI-ontwerp kunnen helpen bij het maken van moderne, gebruiksvriendelijke en mooie interfaces. Dit versnelt het werk van uw ontwikkelaars en verhoogt uw efficiëntie!
Daarnaast biedt deze efficiëntie nog een ander voordeel, namelijk dat veranderingen in uw product of dienst zeer snel kunnen worden doorgevoerd. Dit betekent dat u een veel snellere time-to-market kunt realiseren.
Hebben je applicaties soms last van een inconsistente werking of visuele weergave en ben je benieuwd hoe je dit kunt verhelpen met een ontwerpsysteem? Of heb je vragen over hoe je een ontwerpsysteem precies kunt inrichten om ervoor te zorgen dat je niet tegen consistentieproblemen aanloopt?
Reserveer dan hieronder een gratis en vrijblijvend plekje in onze agenda voor een vraag- en antwoordsessie. Tijdens dit gesprek luisteren we graag naar je vragen en geven we je gericht advies.
Liferay DXP is de afgelopen jaren uitgegroeid tot een veelgebruikt portaalplatform voor het bouwen en beheren van geavanceerde digitale ervaringen. Organisaties gebruiken het voor intranetten, klantportalen, self-service platforms en meer. Hoewel Lif
Lees verder

Op de hoogte blijven van de nieuwste trends en best practices is cruciaal in de snel evoluerende wereld van softwareontwikkeling. Innovatieve benaderingen zoals EventSourcing en CQRS kunnen ontwikkelaars in staat stellen flexibele, schaalbare en veil
Lees verder

Je kunt niet iets ontwerpen of ontwikkelen voor alle 7,9 miljard mensen op deze planeet. Dus als we aan een project beginnen, bepalen we een doelgroep om het te beperken. Van daaruit bouwen we onze functies en ontwerpen op een manier die geschikt lij
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
