.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 4 min
Dorien Jorissen

In deze blog duiken we dieper in 'Low-Code' als concept en hoe je het beste Low-Code platform kiest voor jouw bedrijf.
Low-Code, visual development application modelling, citizen development, ... Als je een ontwikkelaar bent, zullen deze termen zeker een belletje doen rinkelen.
Maar wat is Low-Code precies, waarom is het belangrijk voor jou en wie heeft er baat bij? Het antwoord is eenvoudig: "Dat hangt ervan af".
Als we een stap terug doen, is Low-Code een concept dat draait om visuele ontwikkeling of modellering en dat op grote schaal wordt ondersteund door automatisering. Deze definitie maakt het toepasbaar op veel verschillende gebieden in IT en meer.
Een snelle blik op de rapporten van Forrest en Gartner levert meer dan 300 verschillende Low-Code platforms en producten op.
Zijn deze allemaal gelijkwaardig? Duidelijk niet.
Zijn ze allemaal bedoeld voor applicatieontwikkeling? Nogmaals, nee.
Dus hoe kun je bepalen welk Low-Code platform, product of oplossing relevant zou kunnen zijn voor jou en je klanten?
Als we ons concentreren op de leiders en bekende namen, kunnen we gemakkelijk enkele patronen herkennen om ze te categoriseren (zie het voorbeeld hieronder).
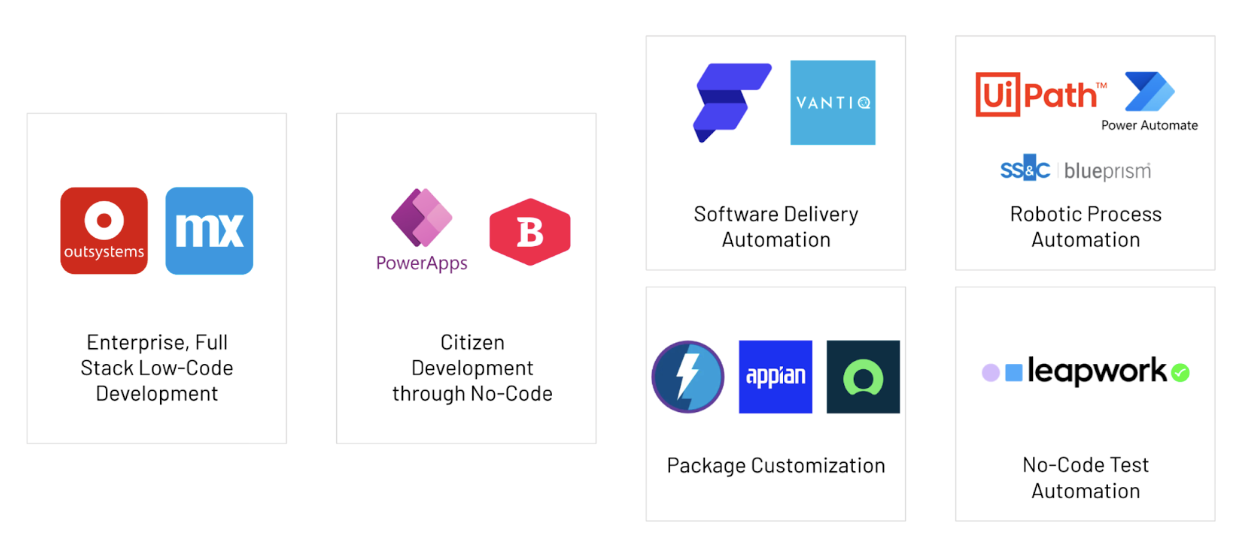
Het gebruik van Low-Code en visuele ontwikkeling/modellering voor het creëren van processen, integraties en automatisering.
Traditionele ontwikkelingsframeworks versterken met Low-Code accelerators om delen van applicaties of startpunten te genereren.
De meeste toonaangevende pakketleveranciers investeren in Low-Code oplossingen binnen hun eigen platform om aanpassingen te vergemakkelijken.
Iedereen kent Selenium, een zeer krachtige tool om testscripts te maken en te onderhouden. Sommige platformen passen zelfs een no-code benadering toe om de testgevallen te modelleren en de Selenium-scripts te laten genereren, uitvoeren en onderhouden zonder dat codering nodig is.
Moe van het werken met Excel of Google Sheets? Zoek je een makkelijk te gebruiken en te leren oplossing om kleine en eenvoudige applicaties voor je team of afdeling te bouwen? Dan zijn Citizen Development platforms de oplossing voor jou. Het is echter niet geschikt voor bedrijfsapplicaties. Gebruik het dus waarvoor het bedoeld is. Je wilt toch ook niet dat je tuinman je nieuwe elektrische auto in elkaar zet?
Een Low-Code enterprise ontwikkelplatform biedt een grafische gebruikersinterface voor programmeren en genereert de onderliggende code automatisch, waardoor ontwikkelaars minder met de hand hoeven te coderen. Deze tools helpen niet alleen met snelle front-end ontwikkeling, maar ook met logica, back-end, integraties en zelfs lifecycle management.
Kan Low-Code traditionele ontwikkeling zoals .Net of Java volledig vervangen? Natuurlijk niet!
Maar Low-Code ontwikkelingsplatforms kunnen zeker helpen om meer projecten in minder tijd op te leveren met hetzelfde aantal mensen. Het stelt organisaties in staat om sneller te reageren op kansen met een kortere time-to-market.
Bovendien kan het helpen om een geldige business case te maken voor projecten die op de lange baan werden geschoven vanwege "andere prioriteiten" en teams die zich voornamelijk richten op bedrijfskritische systemen in uw bedrijf.
Als IT-consultancybedrijf en integrator richten we ons op het leveren van software op maat om aan de specifieke behoeften van onze klanten te voldoen. Low-Code biedt ons een krachtig hulpmiddel om dit te doen. En niet alleen voor de eenvoudige apps! Met het juiste Low-Code platform kunt u zelfs uw legacy moderniseren en klantgerichte web- en mobiele apps bouwen die geïntegreerd zijn met uw ERP, CRM, IAM en brede bestaande landschap.
Het kan je ook helpen je IT-landschap te rationaliseren en te vereenvoudigen en de tools van je bedrijf terug te brengen onder IT Governance zonder dat je de business hoeft te vertellen "sorry, we hebben andere prioriteiten".
ACA koos voor een strategisch partnerschap met OutSystems, een toonaangevend en veruit het meest productieve, veelzijdige en stabiele Low-Code platform op de markt voor enterprise full-stack ontwikkeling.
Ons team van experts werkt al sinds 2016 met OutSystems en heeft ook projecten opgeleverd met andere toonaangevende platforms. We blijven op de hoogte van de laatste aankondigingen, nieuwe functionaliteiten en grote verschillen tussen de 3 toonaangevende Low-Code platforms voor algemene applicatieontwikkeling. Op die manier kunnen we onze klanten adviseren over wat het beste past bij hun behoeften.
OutSystems Developer Cloud is het toonaangevende PaaS cloud native high performance Low-Code platform voor full-stack ontwikkeling en integraties. Het dekt de breedste set use cases. Van interne apps tot B2B- en B2C-klantgerichte web- en mobiele applicaties, processen en zelfs kernsystemen.
Het gebruik ervan voor legacymoderniserings- en innovatieprojecten is een grote versneller voor uw digitale transformatie.
Wat levert OutSystems Developer Cloud op voor bedrijven en de ontwikkelaars en software engineers die het gebruiken om de projecten op te leveren?
Dit alles terwijl je nog steeds de architectuur en best practices in handen hebt.


Tijdens de TVH IT Talks 205 deelde Greg Van Dorpe (Low-Code Offering Lead) ACA’s visie op het huidige IT-landschap met een zaal vol betrokken deelnemers. Hij benadrukte de realiteit die veel teams herkennen: stijgende verwachtingen, een tekort aan ta
Lees verder

Bij de ontwikkeling van software kunnen aannames ernstige gevolgen hebben en we moeten altijd op onze hoede zijn. In deze blogpost bespreken we hoe je omgaat met aannames bij het ontwikkelen van software. Stel je voor... je rijdt naar een bepaalde pl
Lees verder

ACA doet veel projecten. In het laatste kwartaal van 2017 deden we een vrij klein project voor een klant in de financiële sector. De deadline voor het project was eind november en onze klant werd eind september ongerust. We hadden er echter alle vert
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
