.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 6 min
Patrik Söderström
-Apr-18-2025-11-03-17-1486-AM.png?auto=compress,webp&upscale=true&width=610&height=488&name=Featured%20image%20(1)-Apr-18-2025-11-03-17-1486-AM.png "<span id=\"hs_cos_wrapper_name\" class=\"hs_cos_wrapper hs_cos_wrapper_meta_field hs_cos_wrapper_type_text\" style=\"\" data-hs-cos-general-type=\"meta_field\" data-hs-cos-type=\"text\" >FinOps implementeren met Azure om bedrijfswaarde te maximaliseren</span>")
Stel je voor dat je je cloudstrategie zou kunnen omvormen tot een fijn afgestelde machine die de kosten verlaagt en maximale bedrijfswaarde oplevert. Dat is precies wat we voor een van onze klanten hebben gedaan door FinOps met Azure te implementeren. Door middel van gerichte optimalisaties en een sterke focus op organisatorische afstemming hebben we onze klant geholpen duizenden euro's te besparen op zijn Azure-factuur, terwijl we een duurzaam raamwerk hebben opgezet om de cloudkosten onder controle te houden. Nieuwsgierig naar hoe FinOps je kan helpen om werkkosten te optimaliseren en beter te schalen? Lees er alles over in deze blog.
Deze grote organisatie is al een paar jaar klant bij ACA Group. Sinds een tijdje verplaatsen ze steeds meer workload van on premise naar Azure. De financiële afdeling was nog steeds bezig met de budgettering en vertrouwde op Capital Expenditure (CapEx), waarbij de IT-infrastructuurkosten vooraf worden betaald en bekend zijn. Dit in tegenstelling tot Operational Expenditure (OpEx), waarbij de kosten dagelijks fluctueren op basis van het daadwerkelijke gebruik van de digitale middelen die in Azure worden verbruikt.
Onze klant had een substantieel maandelijks budget toegewezen voor Azure, dat consequent werd nageleefd. Daardoor was er geen interne aanleiding om FinOps-praktijken te onderzoeken.
Terwijl ACA deze klant hielp met de migratie van zijn werklast, zagen we een bekend patroon: FinOps was nooit overwogen. Virtuele machines voor alle omgevingen draaiden 24/7 zonder Reserved Instances en niet-productie Storage Accounts maakten gebruik van dure Geo-replicatie.
Dit zette ons aan tot het maken van een snel overzicht van mogelijke besparingen, die we samen met een volledige FinOps-oefening voorstelden. De onmiddellijke besparingen waren zo overtuigend dat de klant snel akkoord ging met ons voorstel.
![]()
Als we het hebben over FinOps, verwijzen we naar de standaarden die zijn opgesteld door de FinOps foundation. Dit is een groot project van de Linux Foundation met een enorme community van meer dan 23.000 leden en 10.000 bedrijven.
In een FinOps-oefening begeleiden we onze klanten door twee deliverables:
Het doel van FinOps is niet om de clouduitgaven te minimaliseren, maar om de waarde die onze klanten krijgen door het gebruik van cloudservices te maximaliseren. Dit onderscheid is essentieel, maar wordt vaak verkeerd begrepen. Elke resource in Azure moet worden gebruikt op een manier die de hoogst mogelijke bedrijfswaarde oplevert.

Het maximaliseren van de bedrijfswaarde helpt ook de ecologische voetafdruk van onze klanten te minimaliseren. Het is een resultaat dat nauw aansluit bij ACA's streven naar duurzaamheid.
Laten we eens kijken naar de webapplicatie van onze klant die draait op een Azure App Service. Elke gebruikersinteractie genereert een belasting voor het systeem en waarde voor het bedrijf.
![]()
Laten we voor het gemak zeggen dat de bedrijfswaarde 1 EUR is elke keer dat een gebruiker de webapplicatie opent. Met duizenden gebruikers levert de applicatie 1000 euro aan waarde.
Het is onze taak om ervoor te zorgen dat de App Service is geoptimaliseerd om deze vraag effectief af te handelen, zodat de bedrijfswaarde wordt gemaximaliseerd. Als we de App Service moeten opschalen, is dat een goede zaak! Zolang we de meest efficiënte middelen en instellingen gebruiken, vergroten we de capaciteit en helpen we de klant om nog meer waarde te genereren.

Het FinOps Assessment omvat meerdere workshops met de belangrijkste stakeholders van onze klant. We brachten de Finance, Business, Engineering en Operations van de klant samen om te laten zien hoe zij allemaal een rol spelen in de cloudkosten.
Met meer dan 20 Target Capability Scopes in FinOps selecteert de klant een paar belangrijke gebieden om zich op te richten voor optimalisatie. In dit geval selecteerde de klant het volgende:

Anomaliebeheer richt zich op onverwachte of abnormale uitgavenpatronen in de cloud. In 2024 ervoer de klant bijvoorbeeld een stijging in de kosten voor een schaalset voor virtuele machines gedurende een paar weken. Ze realiseerden zich dat detectie te lang duurde en wilden betere controles om dit te voorkomen.
Tariefoptimalisatie zorgt ervoor dat de meest kosteneffectieve prijsmodellen en kortingen worden gebruikt. Voordat we met de FinOps-oefening begonnen, hadden we al potentiële besparingen geïdentificeerd, bijvoorbeeld door Reserved Instances te gebruiken. Daarnaast analyseerden we het tarief dat ze betaalden voor Azure resources.
Workload Optimization zorgt ervoor dat resources zoals App Services en Virtual Machines efficiënt worden gebruikt. Is het bijvoorbeeld zinvol voor een niet-productieomgeving om de resources 24/7 te laten draaien?
Samen met de klant stellen we doelen voor elke Target Capability. Ze zeiden bijvoorbeeld dat Anomaly Management erg belangrijk voor ze is en dat ze op dat gebied een Knowledge Leader willen worden.
Tijdens de workshops met alle belanghebbenden was het onze rol om de juiste vragen te stellen om de geselecteerde Target Capability Scopes te beoordelen. Voor Anomaly Management werd het duidelijk dat ze nog in de beginfase zaten, waardoor ze een "1/Deeltelijke Kennis" evaluatie kregen in dat onderdeel.
Toen alle workshops waren afgerond, konden we een eindoordeel vellen over alle Target Capability Scores. Dit gaf de klant een benchmark, wat betekent dat we bij de volgende evaluatie over 4 maanden kunnen zien hoe ver ze zijn gekomen met betrekking tot hun doelen.
Nu de workshops achter de rug waren, konden we ons richten op het geschreven rapport en verder duiken in de technische details van de Azure-omgeving van de klant.
Dit bestond uit twee delen:
We draaiden scripts voor het verzamelen van informatie om configuratiedetails te extraheren en in een leesbaarder formaat te presenteren.
We analyseerden handmatig de resultaten van tools zoals Azure Cost Management en Advisor.
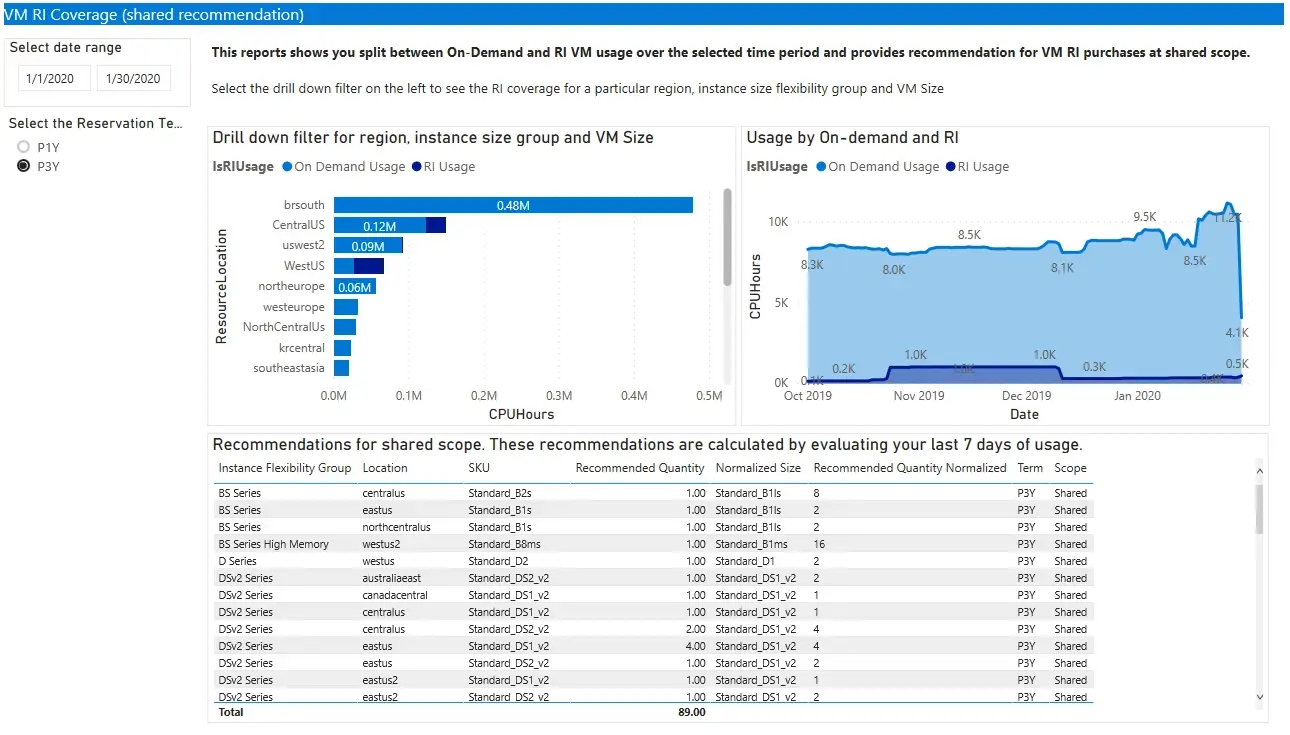
Met zowel de uitvoer van de scripts als de gegevens van de portal, zagen we dat de volgende gebieden de grootste besparingen konden opleveren:
We hebben onze bevindingen en aanbevelingen gebundeld in een schriftelijk rapport. Samen met de klant beoordeelden we het rapport en stippelden we vervolgstappen uit.
💡 Een van de aanbevelingen was om de FinOps Toolkit te implementeren. Dit is een set besturingselementen, Power BI-rapporten en werkboeken die zijn afgestemd op het FinOps-raamwerk. We waren blij om te zien dat ze dit samen met onze andere aanbevelingen hebben omarmd.
In de toekomst zal de klant Azure blijven gebruiken voor zijn workload. Het verschil vanaf nu is dat ze het zullen doen met de mindset van het maximaliseren van de bedrijfswaarde. Over vier maanden zal ACA de status van de FinOps-reis opnieuw beoordelen en hen helpen meten hoe ver ze zijn gekomen.
De langetermijnstrategie houdt ook in dat ACA gebruikmaakt van de strategische samenwerking met Anodot voor FinOps. Samen verleggen we de grenzen van FinOps door kostenefficiëntie te combineren met carbon accountability. Dit zorgt voor een standaard toolset en een uniforme zichtbaarheid van FinOps in al hun omgevingen.
![]()
➡️ Bij ACA Group zijn we experts in FinOps! Laat ons u begeleiden tijdens het FinOps-traject om ervoor te zorgen dat u het volledige potentieel van uw cloudinvestering benut.


CloudBrew is altijd een hoogtepunt op onze kalender geweest, maar de editie van 2025 voelde anders. Misschien lag het aan de timing. Slechts een maand eerder, in november 2025, opende de Azure Belgium Central-regio eindelijk haar deuren. ACA opereert
Lees verder

Een betere uptime, lagere kosten en vendor lock-in vermijden. Dat zijn drie van de redenen waarom onze klanten kiezen voor een multicloud-strategie. Onze Cloud project manager Roel Van Steenberghe legt uit wat zo’n strategie precies inhoudt en wat de
Lees verder

In de complexe wereld van moderne softwareontwikkeling worden bedrijven geconfronteerd met de uitdaging om verschillende applicaties die door verschillende teams worden ontwikkeld en beheerd, naadloos te integreren. De Service Mesh is van onschatbare
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
