.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 3 min
Stijn Schutyser

Heb je ooit gehoord van de BroadcastChannel API? Wij een paar weken geleden ook niet. We stuitten er toevallig op na een zoektocht naar een oplossing waarmee we konden communiceren tussen verschillende browservensters van dezelfde oorsprong. In deze blogpost bespreken we de API zelf en leren we je hoe je de BroadcastChannel API kunt gebruiken binnen een Angular-applicatie.
Stel je voor dat je een webpagina hebt geopend in meerdere tabbladen, en je wilt communiceren tussen deze tabbladen om ze up-to-date te houden. Hoe zou je dat moeten doen? Na wat speurwerk op internet kwamen we de BroadcastChannel API tegen die rechtstreeks in webbrowsers is geïmplementeerd.
Het blijkt dat deze API al sinds 2015 beschikbaar is. Mozilla Firefox 38 was de eerste browser die de specificatie overnam. In de loop van de volgende jaren volgden andere browsers Mozilla's voorbeeld.
Bekijk de demo hieronder om een voorbeeld te zien van wat er allemaal mogelijk is met deze technologie.
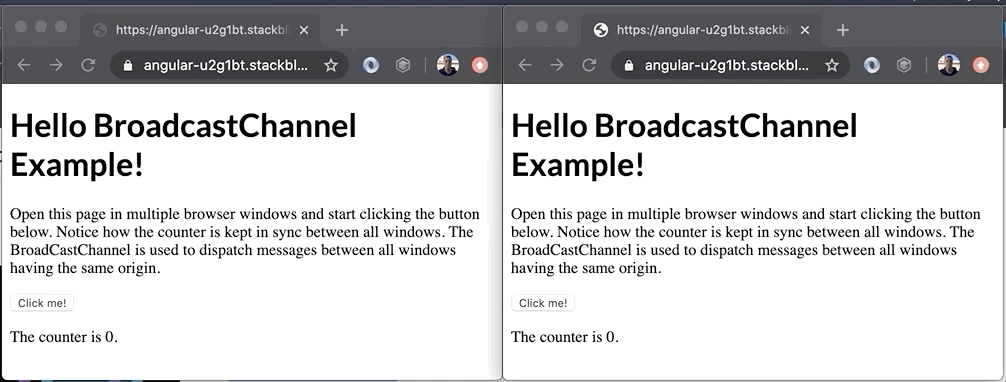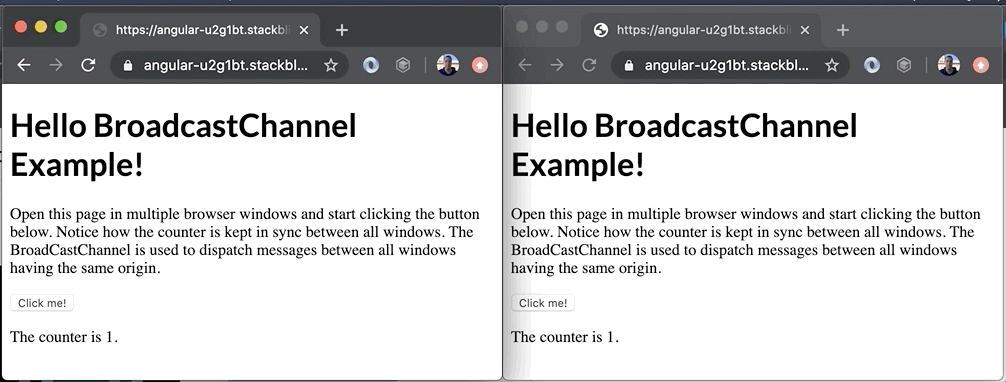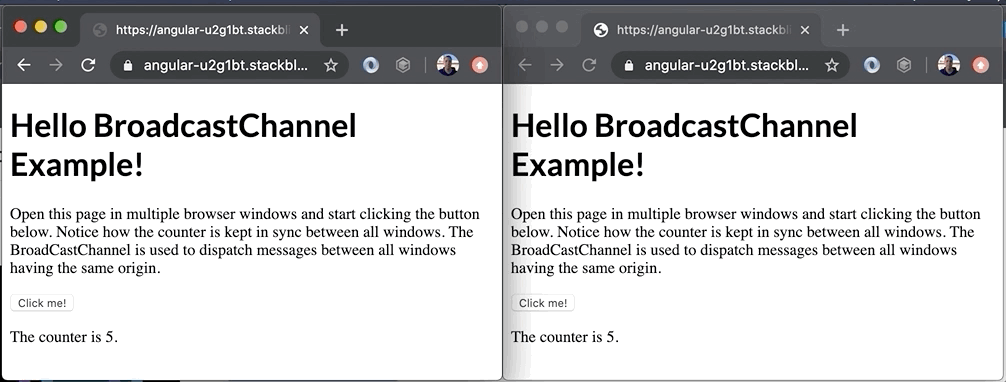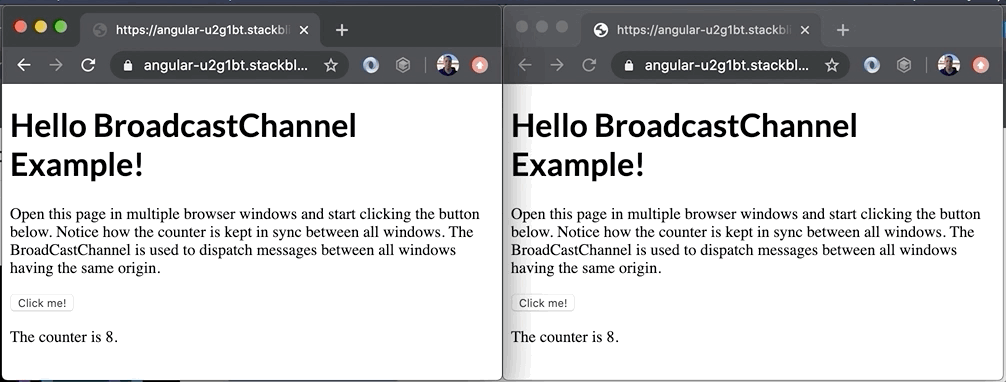
Hoewel het een erg eenvoudige demo is, laat het toch de ware kracht van de BroadcastChannel API zien. In dit voorbeeld wordt de teller in sync gehouden tussen de twee vensters. Het is misschien geen typisch voorbeeld uit de echte wereld, maar je zou de API kunnen gebruiken om:
De BroadcastChannel is in feite een gebeurtenisbus met een producent en een of meer consumenten van de gebeurtenis:
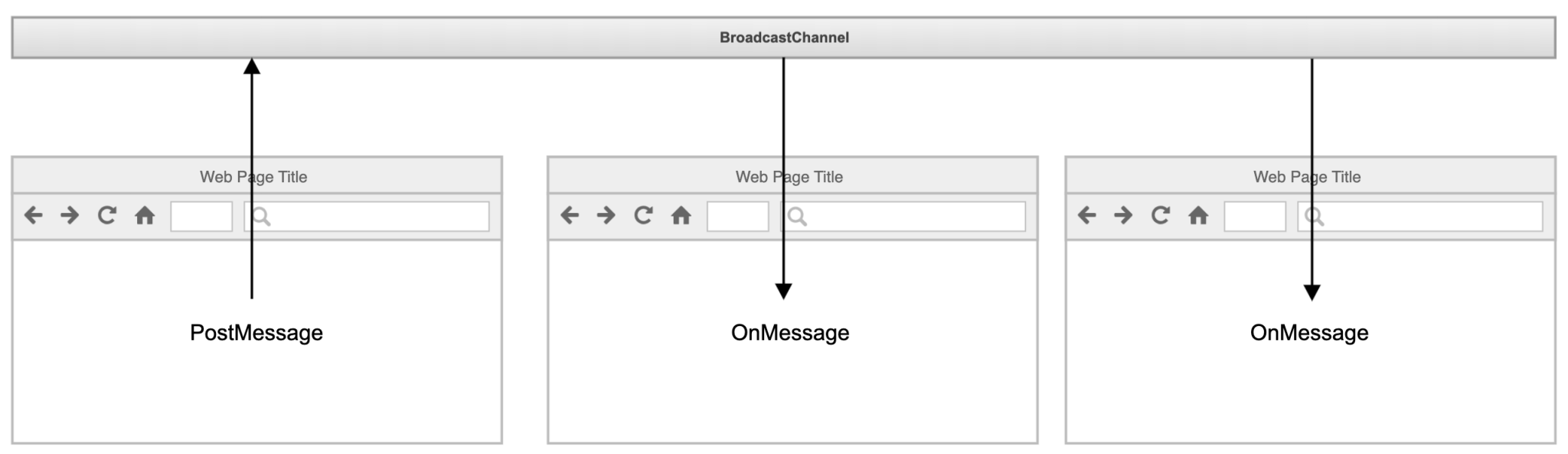
Het aanmaken van een BroadcastChannel is heel eenvoudig. Je hoeft geen bibliotheken te importeren in je code. Je hoeft alleen maar de constructor aan te roepen met een String die de naam bevat van het kanaal dat moet worden aangemaakt.
Nu we een kanaal hebben opgezet, kunnen we het gebruiken om berichten te posten. Het posten van een bericht kan worden gedaan door het aanroepen vanpostMessage op het BroadcastChannel dat je eerder hebt gemaakt.
De postMessage kan allerlei objecten als bericht aannemen. Je kunt in principe alles versturen wat je wilt, zolang de consumer maar weet hoe hij met de ontvangende objecten om moet gaan. Het is echter een goed gebruik om een veld in je berichten te hebben dat het type bericht beschrijft. Dit maakt het eenvoudiger om je te abonneren op berichten van een specifiek type in plaats van een BroadcastChannel per type bericht.
Aan de consumentenkant moet je een BroadcastChannel maken met dezelfde naam als aan de producentenkant. Als de namen niet overeenkomen, zul je (uiteraard) geen berichten ontvangen. Vervolgens moet je de onmessage callback implementeren.
Het BroadcastChannel dat een bericht plaatst zal het bericht zelf niet ontvangen, zelfs als het een luisteraar geregistreerd heeft. Echter, als je een aparte BroadcastChannel instantie aanmaakt voor het posten en consumeren van berichten, dan zal hetbrowservenster dat het bericht gepost heeft het bericht ontvangen. Dat is waarschijnlijk niet iets wat je wilt. Om dit te vermijden, is het de beste gewoonte om een singleton instantie per BroadcastChannel aan te maken.
Je wilt niet overal in je code waar je berichten moet produceren/consumeren naar de BroadcastChannel API verwijzen. Laten we in plaats daarvan een herbruikbare service maken die de logica inkapselt.Op die manier hoef je, als je ooit het BroadcastChannel wilt vervangen door een andere API, slechts één service aan te passen.
In deze specifieke service hebben we goed gebruik gemaakt van RxJS Observables. Let goed op demessagesOfType functie : in dit geval hebben we de standaard RxJS filter operator gebruikt om alleen de berichten te retourneren die overeenkomen met het opgegeven type. Mooi en eenvoudig!
De service is bijna klaar voor gebruik in je Angular-applicatie. Er is nog één uitdaging die je moet aangaan.
Als je Angular al een tijdje gebruikt, ken je waarschijnlijkde Angular Zone. Code die binnen de Angular Zone draait, zal automatisch de wijzigingsdetectie activeren.
De bovenstaande service draait niet in de Angular zone, omdat het een API gebruikt die niet in Angular haakt. Als het een bericht ontvangt en de interne status van een component bijwerkt, is Angular hier niet onmiddellijk van op de hoogte. Dat betekent dat je de wijzigingen niet onmiddellijk terugziet in de browser.Pas nadat de volgende wijzigingsdetectie is geactiveerd, zullen de resultaten zichtbaar zijn in de browser.
Om dit probleem te omzeilen, kun je een aangepaste RxJSOperatorFunction maken. Het enige doel van de OperatorFunction is om ervoor te zorgen dat elke levenscyclushaak van een Observable wordt uitgevoerd in de Angular Zone.
NgZone is een door Angular geleverd object dat je kunt gebruiken om code programmatisch uit te voeren binnen Angular's zone. Het enige dat overblijft is het gebruiken van de bovenstaande OperatorFunction in onze BroadcastService.
Na het bijwerken van de service zijn wijzigingen direct zichtbaar bij het ontvangen van berichten.
Je kunt Angular'sInjectionToken gebruiken om een singleton instantie van de service te maken. Declareer het InjectionToken:
Injecteer de service via het InjectionToken:
Je moet het volgende in gedachten houden als je de BroadcastService gebruikt. Het werkt alleen als
Alle moderne browsers ondersteunen de BroadcastChannel API, behalve Safari en Internet Explorer 11 (en lager). Kijk voor een volledige lijst met compatibele browsers opCaniuse.
Als je een vergelijkbare oplossing moet implementeren in browsers die niet worden ondersteund, kun je in plaats daarvan de LocalStorage van de browser gebruiken.
In deze blogpost hebben we kort beschreven hoe je gebruik kunt maken van de BroadcastChannel API van de browser in een Angular-applicatie. We hebben ook gekeken naar een oplossing voor het koppelen van de API aan Angular's Zone. Je kunt de volledige code van de demo vinden op Stackblitz. Bovendien kun je de BroadcastChannel API documentatie raadplegen op MDN Web Docs.


Bij de ontwikkeling van software kunnen aannames ernstige gevolgen hebben en we moeten altijd op onze hoede zijn. In deze blogpost bespreken we hoe je omgaat met aannames bij het ontwikkelen van software. Stel je voor... je rijdt naar een bepaalde pl
Lees verder

ACA doet veel projecten. In het laatste kwartaal van 2017 deden we een vrij klein project voor een klant in de financiële sector. De deadline voor het project was eind november en onze klant werd eind september ongerust. We hadden er echter alle vert
Lees verder

OutSystems: een katalysator voor bedrijfsinnovatie In het snelle zakelijke landschap van vandaag de dag moeten organisaties innovatieve oplossingen omarmen om voorop te blijven lopen. Er zijn veel strategische technologische trends die cruciale bedri
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!