.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

23 JUL. 2023
Leestijd 3 min
ACA Group Team
.png?auto=compress,webp&upscale=true&width=610&height=488&name=hubspot%20covers%20(6).png "<span id=\"hs_cos_wrapper_name\" class=\"hs_cos_wrapper hs_cos_wrapper_meta_field hs_cos_wrapper_type_text\" style=\"\" data-hs-cos-general-type=\"meta_field\" data-hs-cos-type=\"text\" >Dataproduct analyse: hoe begin ik eraan?</span>")
In de wereld van data mesh zijn dataproducten essentieel. Maar wat is een gegevensproduct precies en hoe pak je de functionele analyse van zo'n gegevensproduct aan? Dat ontdek je in deze blogpost.
Het basisidee van een data mesh bestaat uit 2 delen:
We baseren onze aanpak op de principes van domein-georiënteerd eigenaarschap, federated computational governance, self-service dataplatforms en productdenken. Vooral dat laatste is cruciaal bij het begrijpen en ontwikkelen van een dataproduct. We streven ernaar om data te beschouwen en vorm te geven als een herbruikbaar product, zodat het op verschillende manieren kan worden gebruikt en de waarde ervan wordt gemaximaliseerd.
Een dataproduct is een autonome, leesgeoptimaliseerde, gestandaardiseerde gegevenseenheid die ten minste één dataset bevat (Domain Dataset), gemaakt om aan gebruikersbehoeften te voldoen.
- Majchrzak Jacek , Auteur op Data Mesh in actie

Het is een logische eenheid die alle componenten omvat die nodig zijn om domeinspecifieke gegevens te verwerken en op te slaan voor verschillende use cases, zoals data analytics, en deze toegankelijk maakt voor andere teams via 'output ports'. Een gegevensproduct heeft ook zijn eigen onafhankelijke levenscyclus en beheerstructuren. In wezen kun je een dataproduct vergelijken met een microservice, maar dan ontworpen voor analytische gegevens.
Dataproducten maken verbinding met bronnen via inputpoorten, zoals operationele systemen, dataplatforms of andere dataproducten, en voeren specifieke bewerkingen uit op de data, zoals transformaties, berekeningen, anonimiseren van data, enzovoort.
Bij het ontwikkelen van een dataproduct moeten verschillende aspecten worden aangepakt, zoals het definiëren van invoer- en uitvoerpoorten, het opschonen van gegevens, transformaties, het in kaart brengen van velden, GDPR-compliance, enzovoort. Daarom is een grondige analyse cruciaal.
Maar hoe begin je aan zo'n analyse?
Een gestructureerde analyseaanpak zorgt voor de beste resultaten. Voor dataproducten vertrouwen we op het Data Product Canvas, dat we koppelen aan een handige checklist.
Het canvas is een visuele voorstelling die de weergave van de verschillende kritieke onderdelen van de analyse van je gegevensproduct vereenvoudigt. De checklist zorgt ervoor dat je niets over het hoofd ziet.
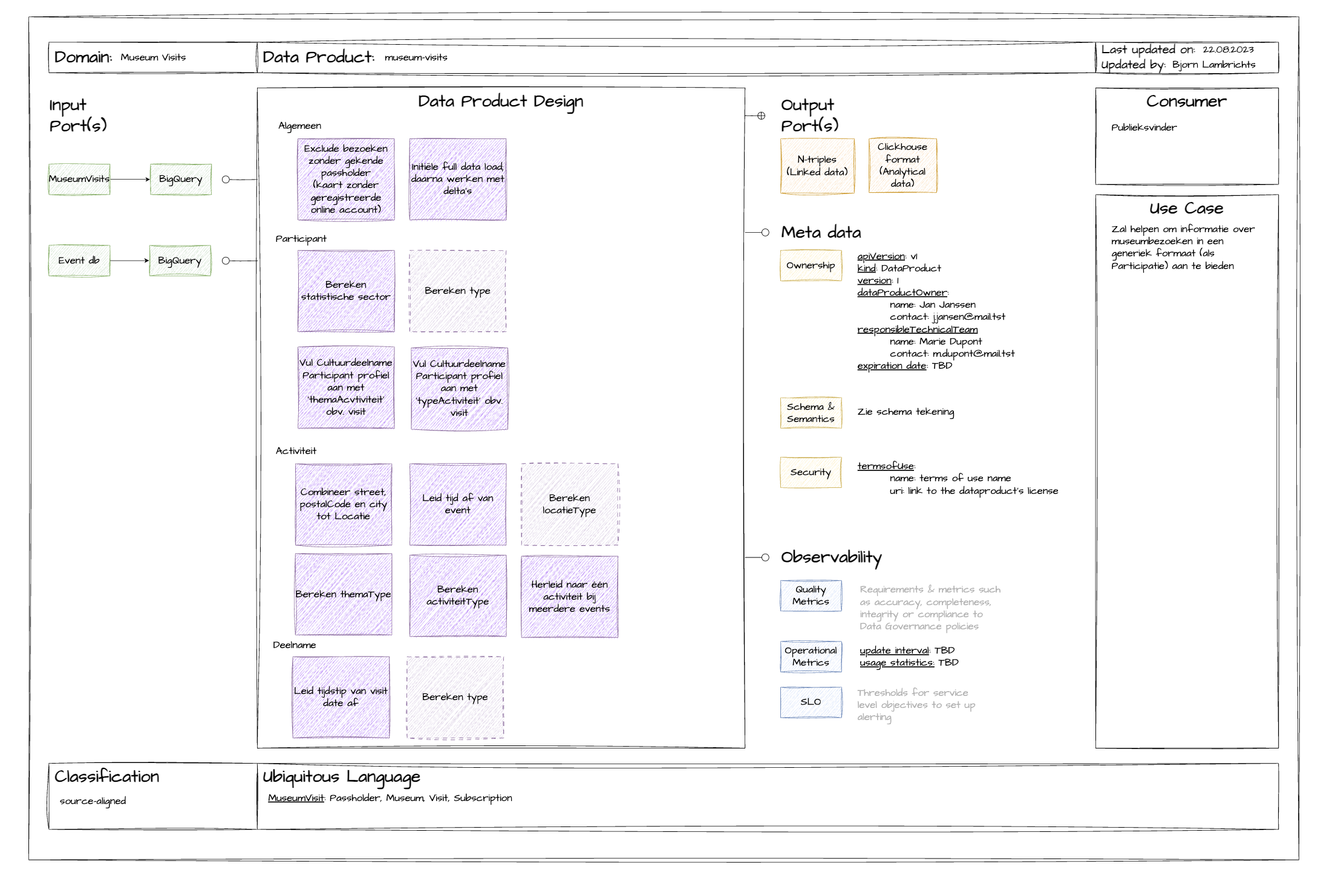
Met het Data Product Canvas zorgen we voor een consistent proces voor het ontwerpen van een dataproduct binnen een organisatie. Het canvas schetst beknopt de aspecten waarmee je rekening moet houden tijdens je analyse.
Met behulp van dit canvas kun je verschillende belanghebbenden bij het dataproduct betrekken. Deze samenwerking leidt tot het gewenste resultaat.
Op basis van onze ervaring met dit canvas, raden we aan het in een bepaalde volgorde in te vullen. Je kunt het beste beginnen met het specificeren van het dataproduct. Op deze manier legt u meteen alle beschrijvende gegevens vast, zorgt u ervoor dat alle belanghebbenden goed geïnformeerd zijn en verduidelijkt u het doel van het gegevensproduct. Ga vervolgens naar de outputpoorten, aangezien de belanghebbenden van het gegevensproduct vaak een goed begrip hebben van de gegevens die ze nodig hebben. Je kunt ze vergelijken met eindgebruikers van een applicatie die baat hebben bij een goede gebruikerservaring. Pak daarna de invoerpoorten aan. Op basis van de feedback van gegevensconsumenten identificeer je de invoerbronnen die de benodigde gegevens kunnen leveren. Sluit ten slotte af met het ontwerp van het gegevensproduct. In deze fase komen input en output samen en probeer je een logische aanpak te bedenken om input om te zetten in de gewenste output.
Zorg ervoor dat je alle beschrijvende gegevens voor je dataproduct verzamelt. Dit omvat:
In veel bedrijven en projecten ontstaat vaak verwarring over de betekenis van bepaalde concepten, termen of woorden. Ubiquitous language, een Domain Driven Design principe, probeert een oplossing te bieden door te streven naar een vocabulaire dat gedeeld en duidelijk begrepen wordt door alle belanghebbenden.
Om spraakverwarring en interpretatieverschillen te voorkomen bij het ontwikkelen en analyseren van een gegevensproduct, is het cruciaal om aandacht te besteden aan alomtegenwoordig taalgebruik. Zorg er daarom voor dat je definities opneemt van termen die relevant zijn binnen de context van het gegevensproduct. Verwijzingen naar andere woordenlijsten, wiki's, enz. zijn ook welkom.
Output ports bepalen het formaat en het protocol waarin gegevens beschikbaar worden gesteld aan je datagebruikers. Bespreek met je gegevensgebruikers (en andere belanghebbenden) het formaat waarin ze gegevens het liefst consumeren. Voorbeelden van soorten uitvoerpoorten zijn analytische gegevens, blob stores, Linked Data, enz.
Input ports specificeren het formaat en de methode waarmee brongegevens kunnen worden gelezen. Door contact op te nemen met de eigenaren van je bronsystemen (of brongegevensproducten), kun je de beschikbare opties ontdekken.
Zorg ervoor dat u het type invoerpoort vermeldt (bijv. API, database, bestand, enz.) en noteer ook uit welke tabellen van het bronsysteem de vereiste gegevens kunnen worden gehaald.
Het is ook erg nuttig om in dit stadium een visuele weergave van het domein van het bronsysteem toe te voegen.
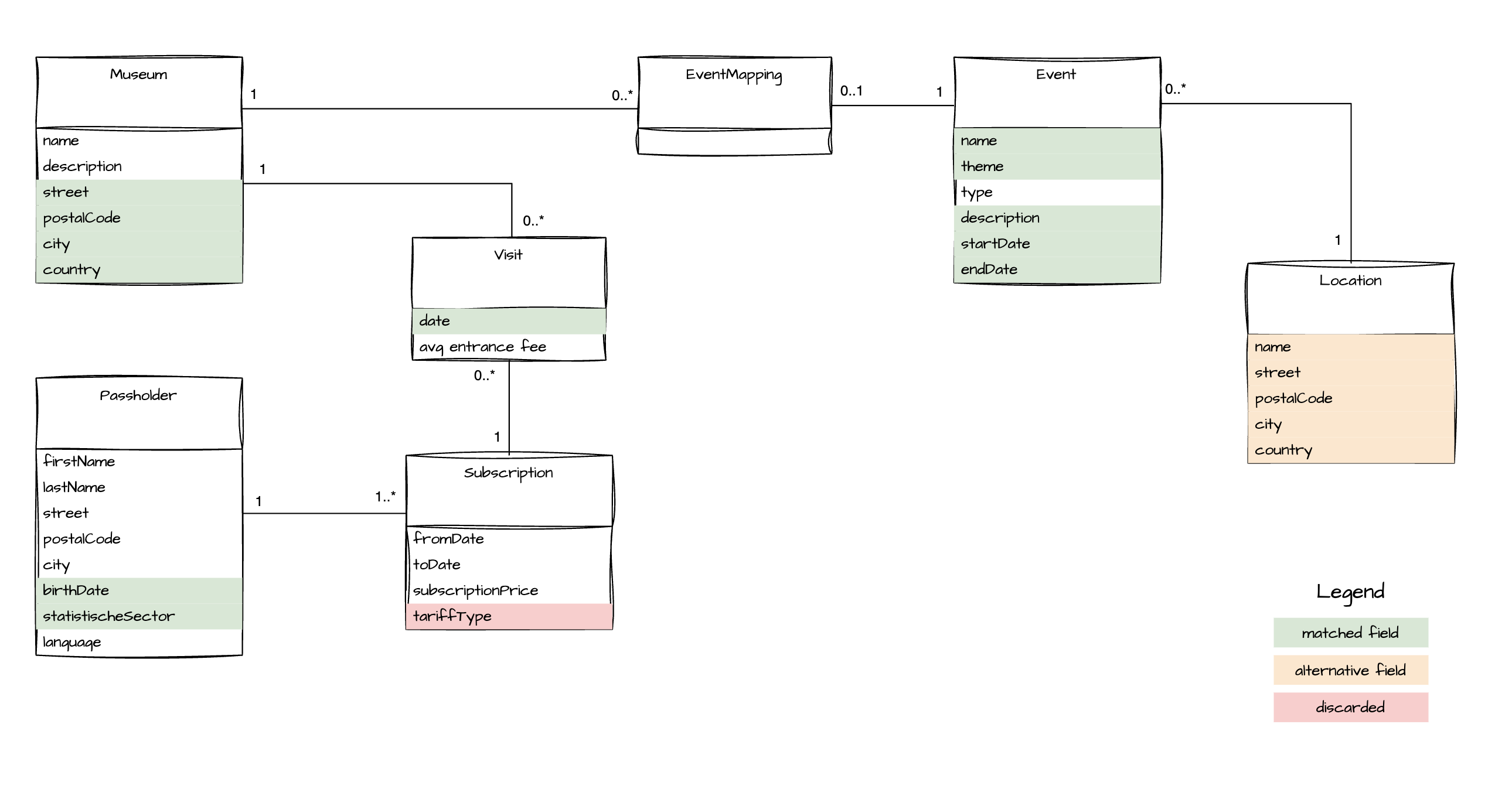
Dit is de laatste en misschien wel de meest kritische stap in de analyse van een gegevensproduct. In deze stap ga je nadenken over de logica van transformaties binnen het gegevensproduct. Denk aan:
In het onderstaande praktijkvoorbeeld behandelen we verschillende van de bovenstaande onderwerpen. Het illustreert hoe bronvelden in kaart worden gebracht en hoe je er effectief mee omgaat. Daarnaast worden bepaalde velden berekend op basis van invoergegevens (bijv. locatie).
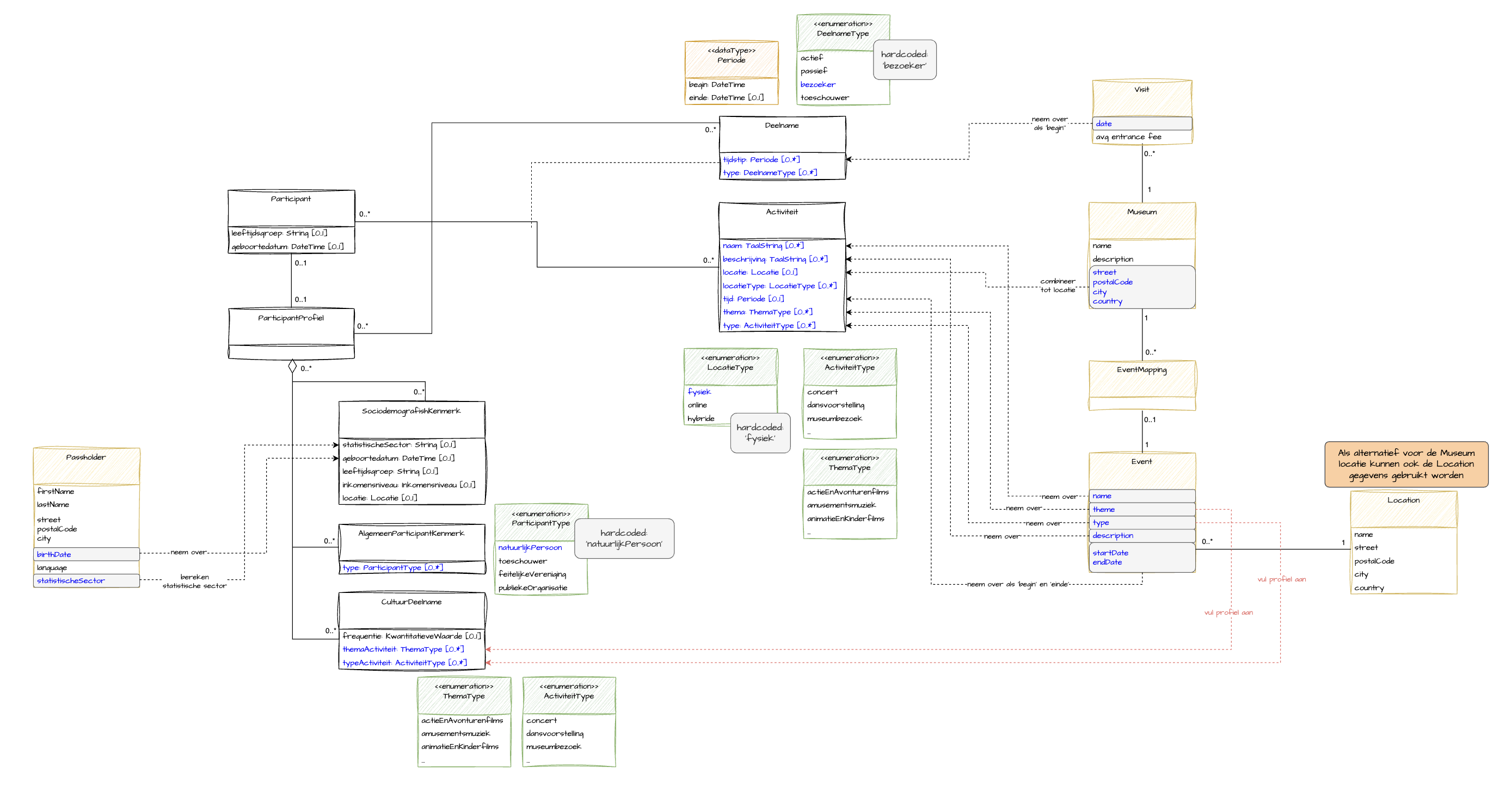
Bij het analyseren van dataproducten komen veel aspecten kijken. Met een goed gestructureerde aanpak, een visueel kader en een eenvoudige checklist kun je deze taak echter met gemak voltooien.


Nestelde jouw bedrijf zich al in de zetels van de eerste klasse of heb je je plekje op de AI-trein nog niet gevonden? Onze AI-expert Alexander Frimout legt uit welke processen bij uitstek geschikt zijn voor je eerste AI-businesscase. En vertelt waaro
Lees verder

Voor elke externe tool die je met je AI-systeem wilt verbinden, moet je een custom integratie bouwen. Dat brengt twee grote nadelen met zich mee. Eén: het kost veel tijd. Twee: deze manier van werken is niet schaalbaar. Gelukkig kan het Model Context
Lees verder

Enlit is Europa’s grootste event rond energietransitie. Vanuit ACA Group tekenden Tom Claus and Sven Sambaer present. Ze ontmoetten klanten en partners, legden hun oor te luister en hielden hun ogen open voor de laatste trends. Een verslag over het e
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
