.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

1 JUN. 2021
Leestijd 7 min
Jan Eerdekens

Elk jaar organiseert ACA IT-Solutions een ACA Ship-IT Day. Tijdens deze dag krijgen onze teamleden de kans om hun innovatieve ideeën uit te werken en kennis op te bouwen. Teamleden verdelen zich in teams en werken het idee zoveel mogelijk uit in slechts één dag. In deze blogpost vertellen we over de ACA Ship-IT Day van dit jaar en de projecten die eruit zijn voortgekomen!
Met meer dan 180 gepassioneerde teamleden die innovatie en kwaliteit als hoofdingrediënten hebben, staat het thema van dit jaar in het teken van"innovatie op één dag". Door de pandemie van het coronavirus moesten veel organisaties vorig jaar een snelle digitale transitie doormaken. Met digitale innovatie als een van onze expertises willen we andere organisaties helpen met deze uitdagingen. Het doel van de ACA Ship-IT Day van dit jaar was om innovatieve toepassingen te creëren die onze klanten kunnen helpen.
Samen met een aantal van onze klanten hebben de verschillende Ship-IT teams innovatieve ideeën gevalideerd en uitgewerkt tot proof-of-concepts. Laten we erin duiken!
Bij ACA staat de eindgebruiker altijd centraal inalles wat wedoen. Metdat in gedachten bouwde het eerste team een klantenportaal voor onze klanten.

Dit klantenportaal iseen centrale plek voor essentiële informatie, waar een klant
We willen betrokken, tevreden en blije klanten. Een aangepaste portal is één ding dat ons kan helpen om dit doel te bereiken. Naast dat hoofddoel zal het werken in dit klantenportaalde efficiëntie verhogen, onnodige communicatie verminderen en de service en ondersteuning vooronze klantenverbeteren en stroomlijnen.
De portal zelf is gebouwd inLiferay enintegreert met verschillende back-end systemen, zoals:
"Ik ben erg blij met wat we hebben kunnen bereiken. Tijdens de dag kon ik met eigen ogen zien hoe we in staat zijn om in zo'n korte tijd iets innovatiefs te bouwen. Ik ben echt onder de indruk van hoe vakkundig mijn andere teamleden zijn!"- Dorien Jorissen , Duurzaamheidsexpert bij ACA Groep

De teamleden van het mobiele team ontwikkelden samen een prototype vaneen mobiele applicatie die werkzoekenden en werkgevers matcht. Werkzoekenden kunnen naar links (leuk vinden) of rechts (niet leuk vinden) vegen over verschillende sollicitaties. Klinkt dat bekend? We noemen het "Tinder voor werkzoekenden". 😀 Eerst maken werkzoekenden een profiel aan.

Werkzoekenden maken eerst een profiel met hun cv aan op de app. Daarna kunnen ze beginnente swipen tussen de sollicitaties waarin ze geïnteresseerd zijn. Deze sollicitaties kunnen worden gefilterd op functie, locatie, sector, anciënniteit, enzovoort. Daarnaast kunnen werkzoekenden(chat)berichten sturen naar de werkgever waarin zegeïnteresseerd zijn.
Werkgevers kunnen hun bedrijf in beeld brengen op de app door een bedrijfsprofiel aan te maken. Ze ontvangen notificaties wanneer een werkzoekende hen leuk vindt, maar ze kunnen ook hun zoekresultaten zien en gegevens en cv's verzamelen op hun dashboard. Voor werkgevers is het ook mogelijk om berichten te sturen naar en vragen te beantwoorden van werkzoekenden die hen leuk vinden.

De mobiele applicatie is geschreven in hetReact Nativeframework en in de React webtaal. De uiteindelijke output van die ontwikkeling is een native app op zowel iOS als Android.
"Ik vond het geweldig! We begonnen de dag met brainstormen om onze focus te bepalen en wie wat zou doen. Gedurende de dag kwamen we regelmatig bij elkaar om onze voortgang te bespreken en de resterende taken te prioriteren. We keken naar wat we aan het einde van de dag zouden kunnen afleveren, één uur per keer. Genoeg reden voor wat gezonde stress :)"
- Joren Vos , Mobile solution engineer bij ACA Group

Een van onze klanten in de gezondheidszorg was al op zoek naar een oplossing die automatisch bepaalde objecten herkent, zoals verwondingen. De dagelijkse opvolging van verwondingen bij patiënten is immers tijdrovend en niet altijd even precies. Daarom ontwikkelde dit derde schip-IT teameen complete AI/AR mobiele oplossing voor letselbeheer. Met deze app kon onze klant tijd besparen, fouten verminderen en de genezing van verwondingen verbeteren, omdat zorgprofessionals zich meer kunnen richten op patiëntenzorg.

De applicatie kanverwondingen automatischdetecteren, registreren en volgen doorgebruik te maken van innovatieve technieken zoalsArtificial Intelligence (AI) en AugmentedReality (AR). Dankzij de geleide realtime herkenning worden zorgverleners begeleid naar een perfecte letselregistratie en ontvangen ze realtime voorspellingen. De app maakt live foto's en voegt aanvullingen toe via metadata voor maximaal gebruiksgemak.
Het is mogelijk om extra informatie in de applicatie op te nemen, zoals de mentale en fysieke toestand van de patiënt en voorspellingen op basis van hun database met verwondingen. Zorgverleners hebben toegang tot deze database om vergelijkbare aandoeningen te vinden en hun patiënt efficiënter te helpen.
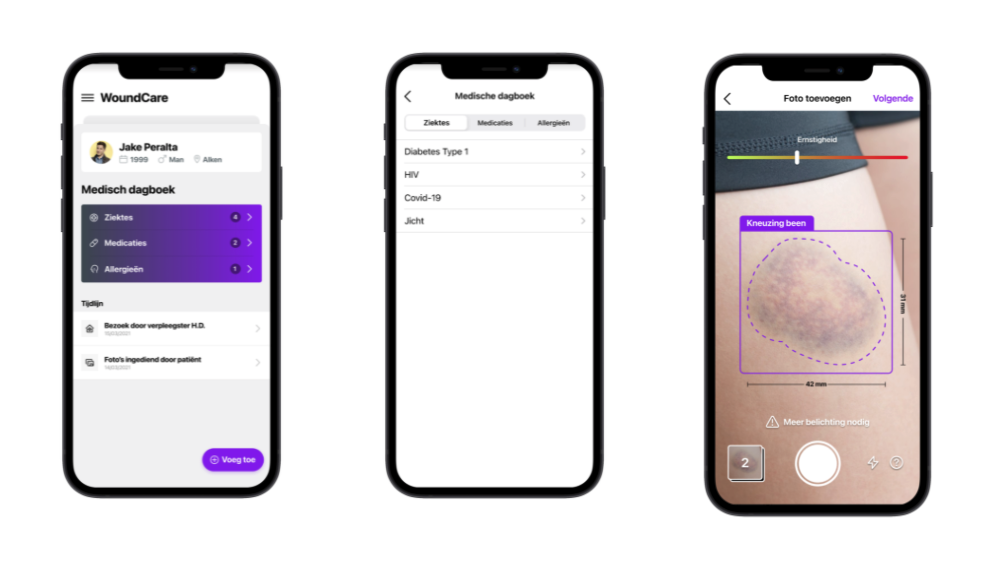
In de applicatie is een persoonlijke tijdlijn geïntegreerd om de evolutie van een bepaalde blessure te volgen, acties voor te stellen en tips te geven. De patiënt kan ook zelf controles uitvoeren via de app. Tot slot beschikt de app over een dashboard met een samenvatting van de geïdentificeerde letsels, statistieken, om onherkende foto's handmatig te koppelen en belangrijke trends te bekijken.

"Het is niet eenvoudig om in slechts 8 uur een app te bouwen om verwondingen te herkennen. We begonnen met het idee dat de app aan het einde van de dag nog niet helemaal uitgewerkt zou zijn, maar dat het meer een prototype zou zijn. We konden laten zien wat er mogelijk is met Google's machine learning kit op iOS. Als we 8 uur extra hadden gehad, hadden we ons detectiesysteem kunnen trainen met modellen om bijvoorbeeld een onderscheid te kunnen maken tussen blauwe plekken en snijwonden."
- Stijn Schutyser , UX / UI Designer bij ACA Group

Veiligheid op de werkplek is cruciaal. Voor hun Ship-IT project wilde dit team de integratie van veiligheidsvoorschriften op de werkplek vergroten en eenvoudige en gebruiksvriendelijke toegang voor alle werknemers in risicoprofielen mogelijk maken.
Het team bouwde eenAugmented Reality (AR) applicatie vooronze klantIDEWE die veiligheidsinstructies, voorschriften en informatiebiedtvoor een specifieke ruimte en/of machine. Op deze manier verkleint het team de kans op een ongeval sterk.
Deze applicatie is flexibel omdat er geen overdaad aan informatie is en hij automatisch geactiveerd wordt door nabijheidstouchpoints. De applicatie kan ook worden aangepast aan het gebruikersprofiel, wat betekent dat ze meldingen krijgen op basis van hun profiel of functie.
Bij het bouwen van deze applicatie heeft ons team twee tools gebruikt. De eerste isGoogle ARcore, een gratis applicatie om AR-toepassingen te maken. Ze gebruikten Google ARCore om een bepaald object te herkennen (in dit geval een QR-code) en vervolgens andere dingen in de wereld in kaart te brengen ten opzichte van de locatie van deze QR-code en ze weer te geven in AR.

"Voor mijn bachelorscriptie heb ik veel geëxperimenteerd met AR in een industrie 4.0 context. Door mijn eerdere ervaring was dit project echt voor mij gemaakt! Ik vond het geweldig om met het team samen te werken en buiten de gebaande paden te denken :)"
- Louis Hendrickx , Java solution engineer bij ACA Group

Er zijn een aantal architectuurtrends in de cloud-native ruimte. In dit Ship-IT-project wilde een teamde mogelijkheden van service mesh verkennen voor ontwikkeling en implementatievoor onze klantValipac. Eenservice mesh, zoals het open-source projectIstio, is een manier om te controleren hoe verschillende onderdelen van een applicatie gegevens met elkaar delen. Op deze manier begrijpen we beter hoe applicaties zich gedragen en verzoeken afhandelen.
Het activeren en tunen van out-of-the-box mogelijkheden voor Valipac geeft ons vooral inzicht in hoe applicaties samenwerken via request-response mechanismen. Dit is onvoldoende om goede inzichten te krijgen in applicaties die asynchroon samenwerken met events (d.w.z. event-driven architectuur). Ons team onderzocht hoe we service mesh kunnen uitbreiden om ook inzicht te geven in deze interacties op een topologiegrafiek. Het team schreef een plug-in voor de Istio service mesh op basis vanWebAssembly. Deze plug-in genereert de metriek achter de topologiegrafiek met de bron van de producent van een gebeurtenis en de bestemming van de consument van een gebeurtenis.
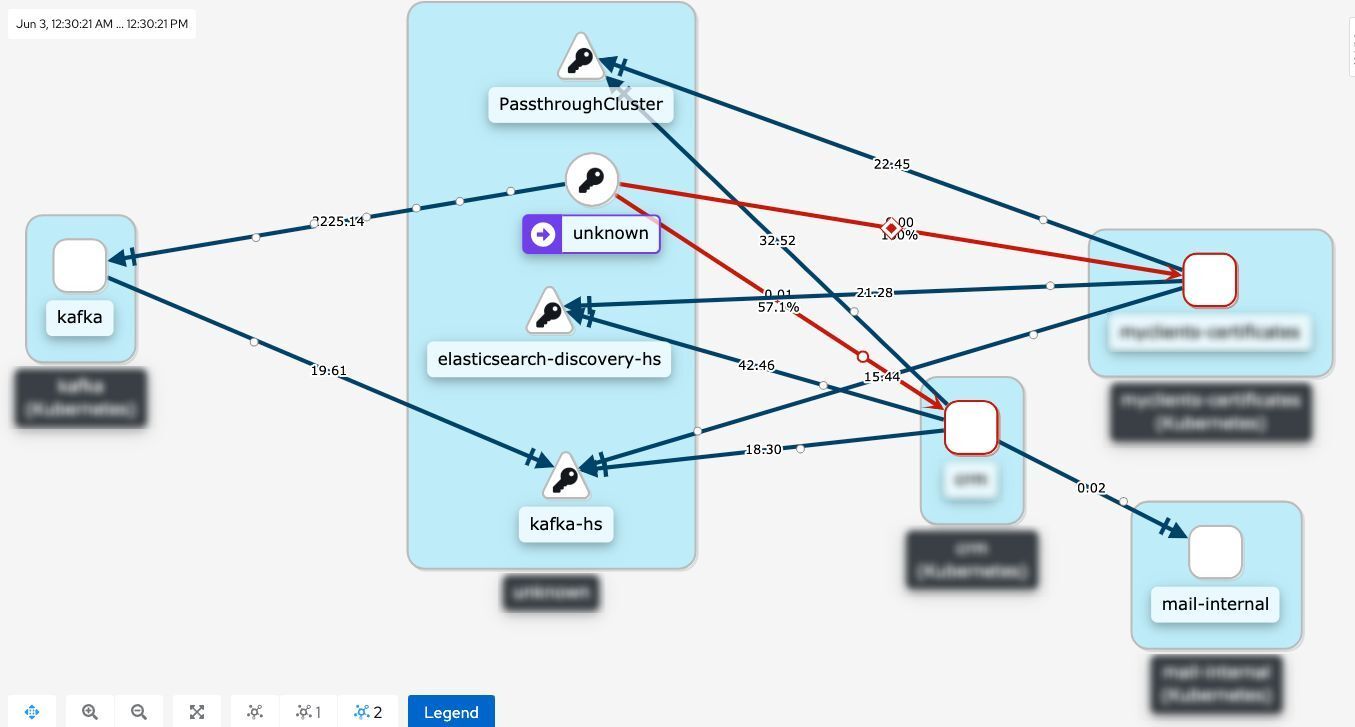
Een les die ons team heeft geleerd is dat het schrijven van een dergelijke plug-in met WebAssembly niet zo eenvoudig is. Ze hadden immers niet veel ervaring met de taal omdat het een relatief nieuwe technologie is. Het team kwam echter tot de conclusie dat ze de topologiediagram ook op dezelfde manier kunnen bouwen vanuit de applicatiecode zelf. Op deze manier zien we via de topologiegrafiek ook welke applicaties samenwerken via events, wat leidt tot een verhoogde observeerbaarheid van het applicatielandschap voor event-driven architecturen zoals Valipac.
Voor onze Atlassian-experts is het leveren van een goede service voor onze klanten hun topprioriteit.Ze willen de ACA-ondersteuning dichter bij onze klantMLOZ brengen. Daaromwilden ze de applicaties die we bij MLOZ draaien integreren metons eigen track-it systeem. Op deze manier ontvangt ons supportteam alle relevante informatie direct wanneer het ticket door de klant wordt aangemaakt.

Ons team gebruikteAutoblocks voorde integratie in dit project. Autoblocksis een integratieplatform van onze partnerAdaptavist datintegreert met Atlassian tools.
De klant van dit Ship-IT project levert transport aan apotheken en zal dit in de toekomst ook uitbreiden naar patiënten. Op dit moment hebben ze niet veel middelen om orders te volgen en op te volgen. Ons 8e Ship-IT stapte in en wilde hen helpen dooreen gebruiksvriendelijk platform te bouwenom bestellingen op te volgen, feedback van eindgebruikers te ontvangen ende gebruikersde mogelijkheid te geven om bepaalde items opnieuw te bestellen.
Door een dergelijk ordervolgsysteem te creëren, biedt het team voordelen aan verschillende actoren van onze klant. Apotheken zullen een beter overzicht hebben van de status van de bestellingen, die ze kunnen doorgeven aan hun eindklanten. Patiënten aan hun kant kunnen op een eenvoudige en gebruiksvriendelijke manier bestellingen plaatsen, volgen en opvolgen.
![]()
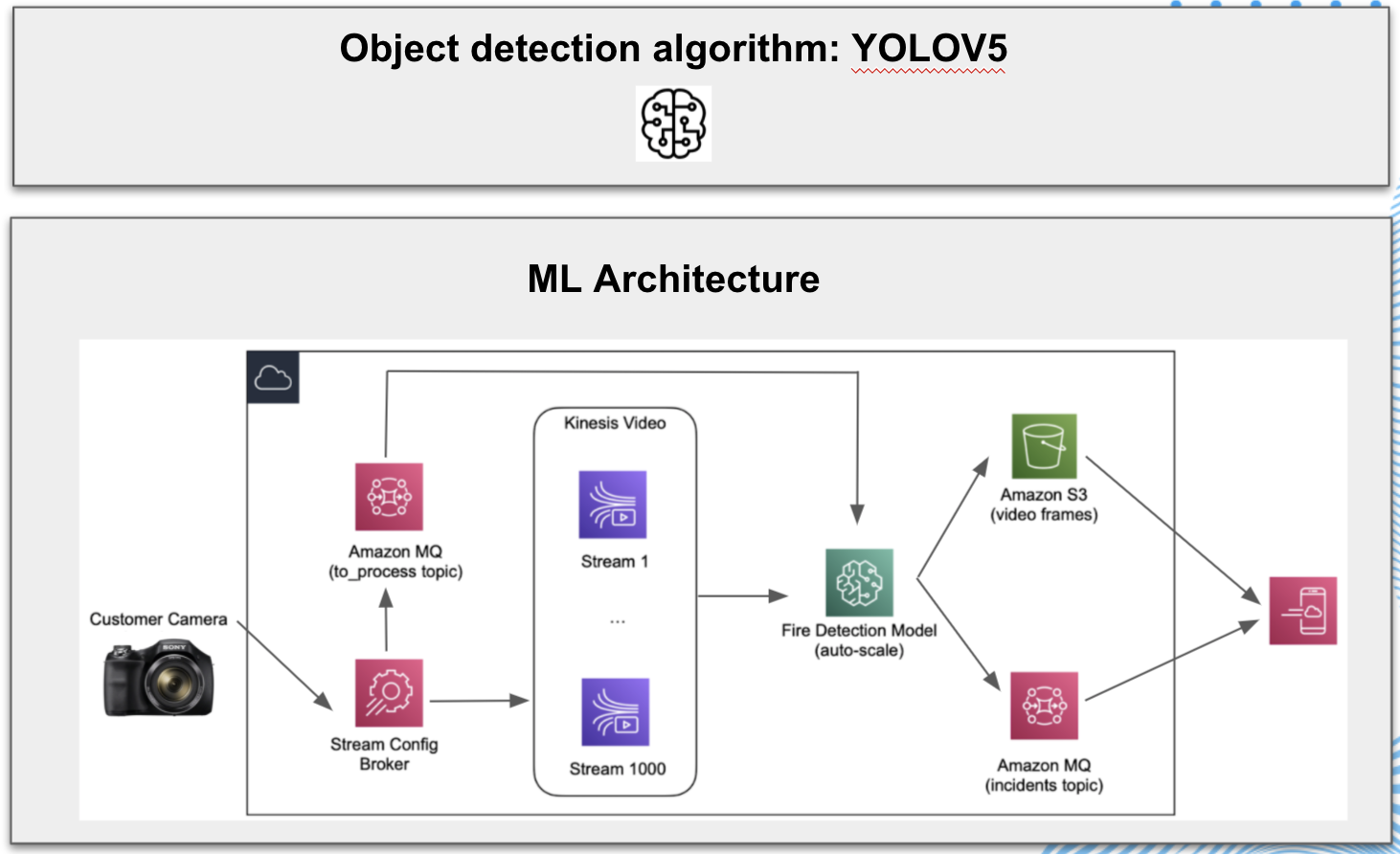
Onze klant is een van de belangrijkste producenten van diepgevroren aardappelproducten voor private labels ter wereld. Hun faciliteiten bevatten meer dan 1000 camera's die de productielijnen bewaken. Momenteel worden de videostromen bewaakt door operators. Dit zorgt ervoor dat de operators een enorm aantal camera's moeten bewaken. Dit betekent dat incidenten niet altijd onmiddellijk worden gedetecteerd. Wanneer er brand uitbreekt, kan dit grote gevolgen hebben voor zowel de veiligheid als de productiecapaciteit.
Daarom richtte dit Ship-IT project zich op het ontwikkelen van een real-time meldapplicatie die gebruik maakt van machine learning en cloud-infrastructuur om brand te detecteren op basis van camerafeeds. Het identificeren en lokaliseren van een vlam in videoframes is een objectdetectieprobleem. Het You Only Look Once (YOLO) machine learning model is een geavanceerd algoritme voor real-time objectdetectie. In dit project gebruikte het team een recente implementatie van YOLO, YOLOV5, ontwikkeld door Ultralytics. Deze eenfasige objectdetector is gebaseerd op een neurale netwerkarchitectuur die - tijdens het trainen - een set informatieve kenmerken uit invoerbeelden haalt, d.w.z. beelden van binnen en buiten met vuur. Later wordt het getrainde model gebruikt om voor elk frame de aanwezigheid van vuur te identificeren. Als er een vlam wordt gedetecteerd, tekent het model een kader rond de vlam en kent het een vertrouwensscore toe aan die voorspelling.

Aan de operationele kant begint onze oplossing met het aanmelden van een camerafeed van een klant bij een broker die een Kinesis-videostream initialiseert en ook notificaties stuurt naar een verwerkingswachtrij voorzien van Amazon MQ (of vergelijkbaar). De wachtrij wordt gevuld met individuele videoframes die parallel worden verwerkt door het voorgetrainde objectdetectiemodel aan te roepen, d.w.z. YOLOV5, dat wordt ingezet met AWS SageMaker. Zodra een vlam wordt gedetecteerd in een frame, wordt een downstream event geactiveerd om een applicatie/notificatie-engine op de hoogte te stellen. Deze architectuur maakt enorme automatisering en schaalbaarheid mogelijk. In het bijzonder kan er horizontaal geschaald worden door het aantal parallelle threads te vergroten, maar ook verticaal door het aantal SageMaker-instanties te vergroten via de auto-scale mogelijkheid van SageMaker.
Om de melding in geval van brand te versnellen, hebben we het mogelijk gemaakt om een mobiele applicatie te bouwen die bestaat uit een realtime melding, een afbeelding van de locatie van de brand en een tijdstempel.
Aan het einde van de dag moesten de verschillende teams een proof-of-concept maken om te demonstreren en een presentatie over te geven. Elk team pitchte hun project aan alle andere teams, die vervolgens stemden voor hun favoriete project op basis van het thema.
Project 1, My ACA, mocht dit jaar de trofee mee naar huis nemen! 🏆Binnen ACA denken we al een tijdje na over het bieden van een optimale klantervaring aan onze klanten. De ACA Ship-IT Day was de perfecte gelegenheid om zo'n portal te creëren op basis van nieuwe tools. Vanwege de innovatieve factor en de toegevoegde waarde voor onze klanten stemden de meeste medewerkers voor dit project. De volgende stappen zijn het testen van het voorstel met een aantal pilotklanten en het maken van een inschatting voor de verdere uitwerking van MVP1, dat vervolgens aan ons managementteam zal worden voorgelegd. Na al deze stappen gaan we op zoek naar een sponsor.
Felicitaties aan het hele team van experts en alle andere teams die hebben bijgedragen aan deze geweldige Ship-IT Day.We kijken uit naar volgend jaar!


Nestelde jouw bedrijf zich al in de zetels van de eerste klasse of heb je je plekje op de AI-trein nog niet gevonden? Onze AI-expert Alexander Frimout legt uit welke processen bij uitstek geschikt zijn voor je eerste AI-businesscase. En vertelt waaro
Lees verder

Voor elke externe tool die je met je AI-systeem wilt verbinden, moet je een custom integratie bouwen. Dat brengt twee grote nadelen met zich mee. Eén: het kost veel tijd. Twee: deze manier van werken is niet schaalbaar. Gelukkig kan het Model Context
Lees verder

Enlit is Europa’s grootste event rond energietransitie. Vanuit ACA Group tekenden Tom Claus and Sven Sambaer present. Ze ontmoetten klanten en partners, legden hun oor te luister en hielden hun ogen open voor de laatste trends. Een verslag over het e
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
