.svg?width=174&auto=compress,webp&upscale=true "aca-group (black)")
.svg?width=139&auto=compress,webp&upscale=true "aca-group (black)")

Reading time 5 min
Stijn Vandereyken

Within ACA, there are multiple teams working on different (or the same!) projects. Every team has their own domains of expertise, such as developing custom software, marketing and communications, mobile development and more. The teams specialized in Atlassian products and cloud expertise combined their knowledge to create a highly-available Atlassian stack on Kubernetes. Not only could we improve our internal processes this way, we could also offer this solution to our customers!
In this blogpost, we’ll explain how our Atlassian and cloud teams built a highly-available Atlassian stack on top of Kubernetes. We’ll also discuss the benefits of this approach as well as the problems we’ve faced along the path. While we’re damn close, we’re not perfect after all 😉 Lastly, we’ll talk about how we monitor this setup.
Our Atlassian stack consists of the following products:
As you can see, we use AWS as the cloud provider for our Kubernetes setup. We create all the resources with Terraform. We’ve written a separate blog post on what our Kubernetes setup exactly looks like. You can read it here! The image below should give you a general idea.

The next diagram should give you an idea about the setup of our Atlassian Data Center.

While there are a few differences between the products and setups, the core remains the same.
By using this setup, we can leverage the advantages of Docker and Kubernetes and the Data Center versions of the Atlassian tooling. There are a lot of benefits to this kind of setup, but we’ve listed the most important advantages below.

Interested in leveraging the power of Kubernetes yourself? You can find more information about how we can help you on our website!
Migrating to this stack wasn’t all fun and games. We’ve definitely faced some difficulties and challenges along the way. By discussing them here, we hope we can facilitate your migration to a similar setup!

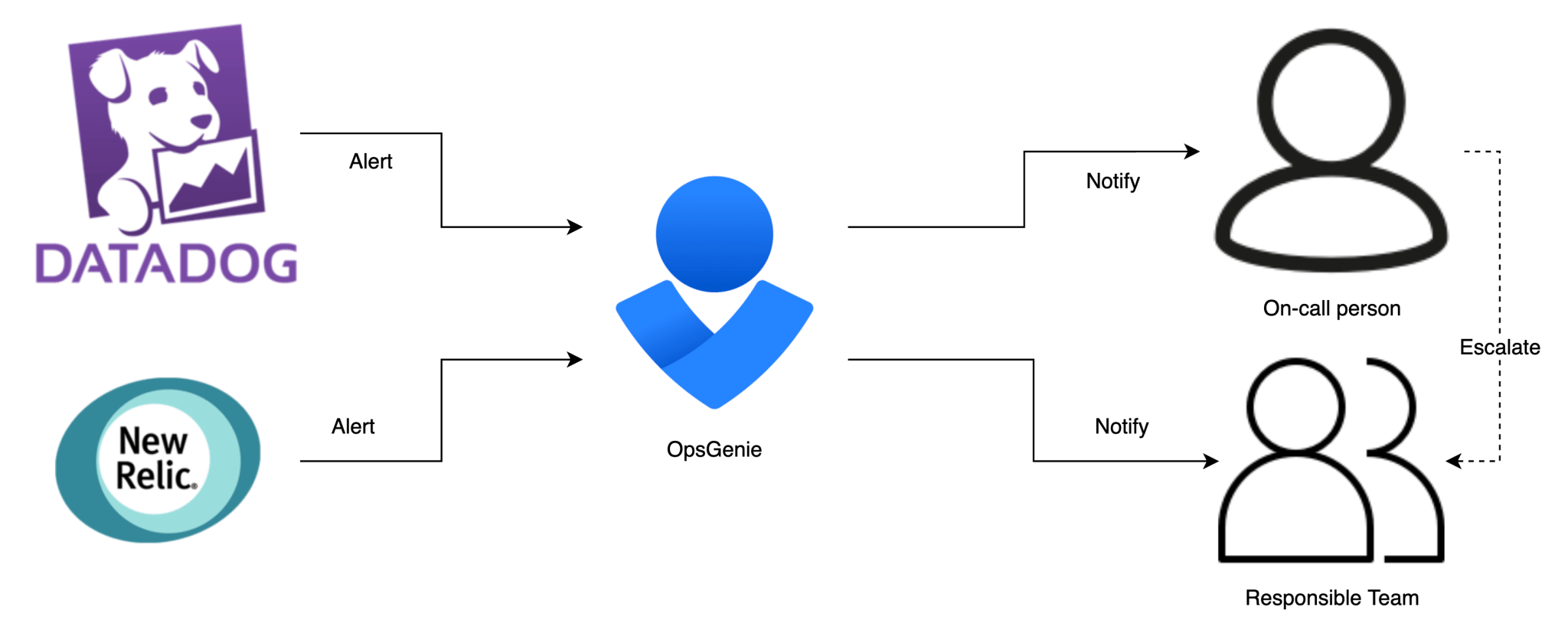
We use the following tools to monitor all resources within our setup
If our monitoring detects an anomaly, it creates an alert within OpsGenie. OpsGenie will make sure that this alert is sent to the team or the on-call person that is responsible to fix the problem. If the on-call person does not acknowledge the alert in time, the alert will be escalated to the team that’s responsible for that specific alert.
In short, we are very happy we migrated to this new stack. Combining the benefits of Kubernetes and the Atlassian Data Center versions of Jira, Confluence and BitBucket feels like a big step in the right direction. The improvements in self-healing, deploying and monitoring benefits us every day and maintenance has become a lot easier.
Interested in your own Atlassian Stack? Do you also want to leverage the power of Kubernetes? You can find more information about how we can help you on our website!



CloudBrew has always been a highlight on our calendar, but the 2025 edition felt different. Perhaps it was the timing. Just the month prior, November 2025, the Azure Belgium Central region finally opened its doors. ACA has always operated from the he
Read more

Better uptime, lower costs, and avoiding vendor lock-in. These are three of the reasons why our customers opt for a multicloud strategy. Our Cloud Project Manager Roel Van Steenberghe explains what such a strategy entails and what the advantages of G
Read more

In the complex world of modern software development, companies are faced with the challenge of seamlessly integrating diverse applications developed and managed by different teams. An invaluable asset in overcoming this challenge is the Service Mesh.
Read moreGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!