.svg?width=174&auto=compress,webp&upscale=true "aca-group (black)")
.svg?width=139&auto=compress,webp&upscale=true "aca-group (black)")

Reading time 4 min
Ibn Renders

Data mesh is revolutionizing the way organizations manage data. Unlike traditional centralized models, data mesh uses a decentralized, domain-oriented structure. But how does governance work in such a distributed system?
At ACA Group, we believe data mesh is an answer to the challenge of managing data by focusing on building a decentralized, self-serve data ecosystem. The goal is to embed data-driven innovation within each department or team, making everyone in the organization responsible for creating reusable data that fuels new products and services across departments.
In a data mesh, not only the management of ownership and infrastructure is different. The key to success is transforming data governance itself. Instead of making a centralized IT team responsible for data governance, data mesh distributes the responsibility across different teams.
This approach, known as "federated computational governance", ensures active participation from both data-producing and data-consuming teams in crafting and adopting governance policies.
To understand the importance of governance in a data mesh, we need to break down the core principles of a data mesh and how they relate to data governance challenges:
In a data mesh, data ownership and responsibility are distributed across different business domains or teams. Each domain becomes a self-contained unit, managing its own data products. This also means that each data product and domain is self-governing, but needs to be interoperable with other data products and domains.
Instead of a monolithic data warehouse, a data mesh is made up of interconnected data products. This implies that each data product might come with its own “local dialect”. The challenge here is how to speak the same language, without speaking the same language.
This approach treats data as a product, with each domain creating and maintaining data products that are discoverable, accessible, and reusable. Metadata management becomes an important topic, since metadata is used to discover, access, integrate with and use the data encapsulated within a data product.
This engine and control panel empowers data producers and consumers alike. Developer portals, data catalogs, lineage tools, and collaboration spaces facilitate seamless navigation, while automated policy enforcement and regular audits are used to ensure compliance and promote data product quality without manual intervention. Automation of governance is a core challenge associated with the self-serve platform.
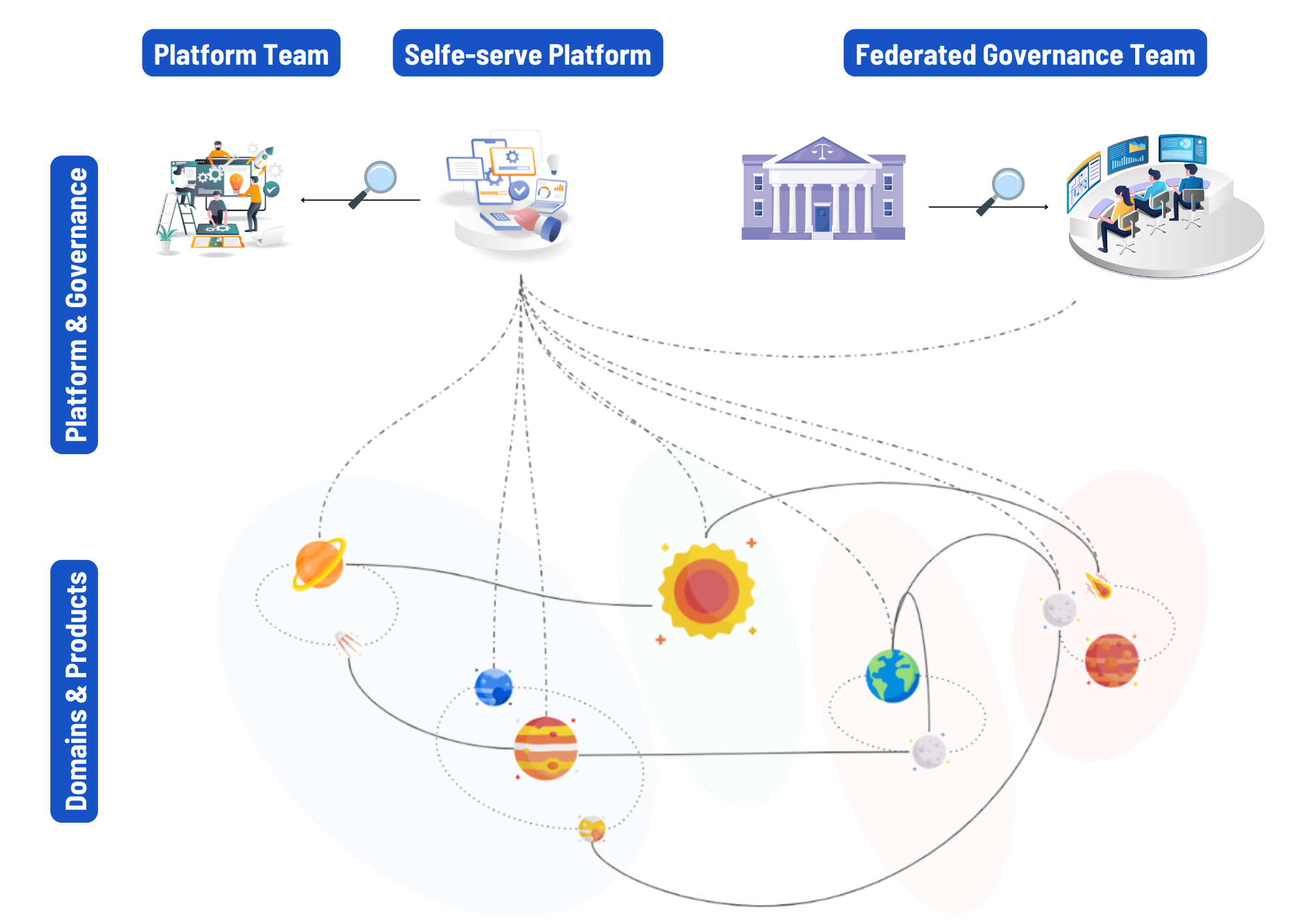
Now that you have a better understanding of the central building blocks and challenges of data governance in a data mesh, let’s take a closer look at each of these challenges individually.
A standout feature of data mesh is federated governance. But what does it actually mean?
“Federated” refers to the fact that while each domain (and data product within those domains) has its own autonomy, they come together to hash out a few things that are relevant and valuable for everyone. You might think of it as a parliamentary democracy, where representatives come together to make joint decisions, which then need to be broadly implemented.
This cross-domain collaboration means that quite a few teams are going to be involved.
This is a group of domain representatives and experts who collaborate across business units and areas of expertise. They ensure data quality, compliance, and alignment with organizational goals.They oversee tasks such as:
This team defines standardized data governance policies and ensures that data products and datasets can be shared and reused, while safeguarding overall quality. To continue our earlier comparison, the Governance team is like a “parliament” that discusses and passes “laws”.
This team is essential to automate and enforce the governance policies defined by the Governance Team on the self-serve platform. They ensure that policies can be adopted by Data Products on a low-effort basis, promoting interoperability and collaboration without introducing unnecessary overhead.
Aligned with business units, domain teams handle operational data governance within their own domains. Responsibilities include:
Importantly, each domain team has the autonomy and resources to execute the standards defined by the federated governance team.
While local domain teams make decisions specific to their domain, federated data governance ensures global rules are applied to all data products and their interfaces. These rules must ensure a healthy and interoperable ecosystem.
Let’s start with an important note: Federated Governance requires a different way of thinking compared to more traditional governance approaches.
Federated governance is focused on promoting autonomy and interoperability as much as possible, keeping interference by a centralized team to an absolute minimum. Do you want to successfully implement federated data governance in your organization? Then, make sure you establish the following key foundations:
Each domain can have its own specific lingo, creating challenges when terms differ in definition across teams. To bridge the gaps between domains, we need a solid basis for “translation” and a common understanding of terms. This is where the enterprise ontology comes in.
You can see it as a large, hierarchically structured “dictionary” that links concepts used in different domains to each other based on a common denominator.
For example: a sales team and a finance team both use the term “customer”, but the definitions for this term used by each team are somewhat different.
Without a shared ontology, combining the data products from these teams would yield inconsistent results, highlighting the need for clarity.
By tagging domain-specific terms to a unified concept (e.g., "customer") in the ontology, teams can reconcile differences and enable cross-domain understanding.
To bridge the gaps between domain-specific terms:
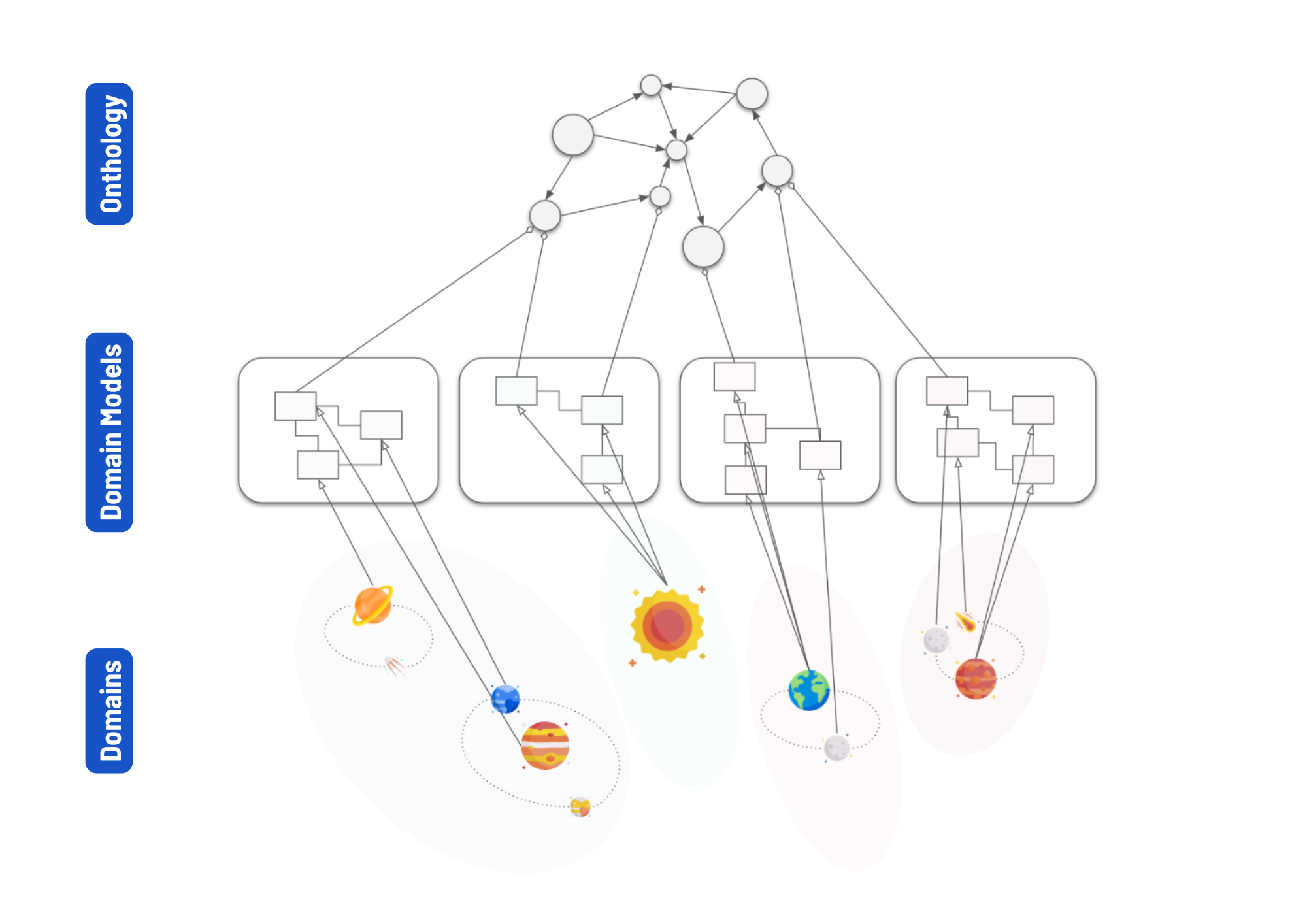
Metadata, often described as "data about data," plays a crucial role in Federated Data Governance within a data mesh. It provides the necessary context to make data understandable, accessible, and usable across different domains.
In a data mesh, metadata should be managed as close to the source as possible. Each data product team is responsible to carefully author and curate the metadata associated with their data product. Exceptions, like the automated addition of data quality metrics from the self-serve platform, can apply, but the data product itself remains the source of truth, and they should be managed as such. In short, metadata should be decentrally managed, but centrally consumable.
Metadata management should be automated as much as reasonably possible and integrated with data governance tools to ensure accuracy and consistency. Key practices include:
The self-serve platform embodies "Federated Computational Governance." It provides tools and infrastructure that allow both users and creators to independently access and manage data products without relying on a central IT team.
Embracing a data mesh architecture requires a different approach to governance. The traditional centralized model of managing data no longer suffices in a world where agility, autonomy, and cross-functional collaboration are paramount.
Federated data governance empowers domain teams to take ownership of their data products while ensuring alignment with global organizational standards. By distributing responsibilities across domain teams, supported by a self-serve platform and strong metadata management practices, organizations can enhance data quality, interoperability, and compliance without adding unnecessary complexity.
However, the success of data mesh governance depends on fostering a strong culture of data ownership, building a robust self-service platform, and establishing clear frameworks that promote seamless cross-domain collaboration.
That’s a lot of buzzwords for one sentence, but it rings true nonetheless:
The key to thriving in data mesh is a governance model that strikes the right balance between autonomy and oversight—allowing teams to produce while safeguarding the integrity and value of the organization's data ecosystem.


In the ever-evolving landscape of data management, investing in platforms and navigating migrations between them is a recurring theme in many data strategies. How can we ensure that these investments remain relevant and can evolve over time, avoiding
Read more

You may well be familiar with the term ‘data mesh’. It is one of those buzzwords to do with data that have been doing the rounds for some time now. Even though data mesh has the potential to bring a lot of value for an organization in quite a few sit
Read more

In recent years, the exponential growth of data has led to an increasing demand for more effective ways to manage it. Building a data-driven business remains one of the top strategic goals of many business stakeholders. And while it may seem logical
Read moreGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
