.svg?width=174&auto=compress,webp&upscale=true "aca-group")
.svg?width=139&auto=compress,webp&upscale=true "aca-group")

Leestijd 9 min
Peter Hardeel
-1.png?auto=compress,webp&upscale=true&width=610&height=488&name=hubspot%20covers%20(1)-1.png "<span id=\"hs_cos_wrapper_name\" class=\"hs_cos_wrapper hs_cos_wrapper_meta_field hs_cos_wrapper_type_text\" style=\"\" data-hs-cos-general-type=\"meta_field\" data-hs-cos-type=\"text\" >De principes van data mesh toepassen op een IoT-data-architectuur</span>")
Laten we beginnen met uit te leggen wat 'data mesh' is en welke principes het nastreeft. We beginnen met te kijken hoe de operationele ruimte de afgelopen tien jaar is geëvolueerd.
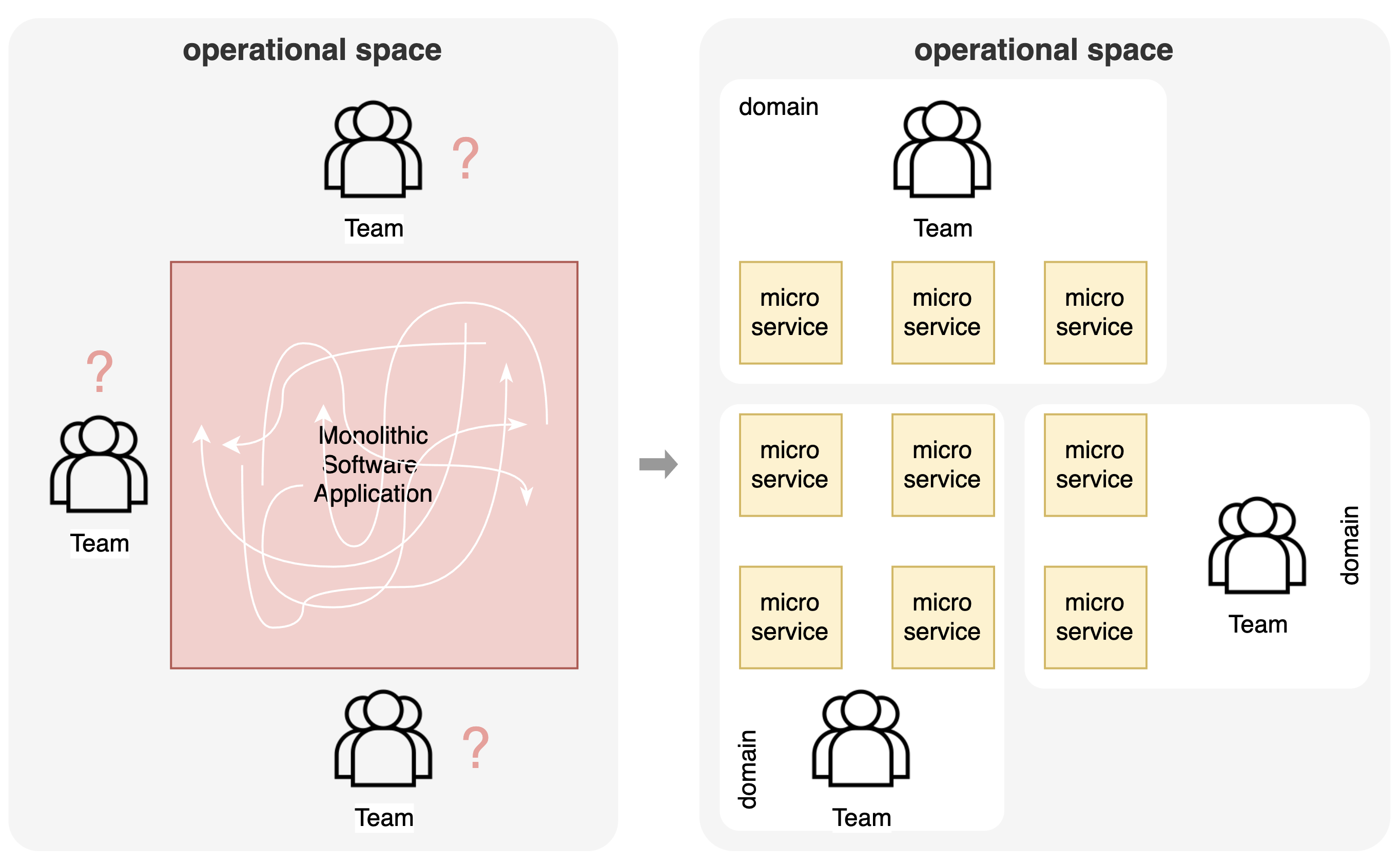
In het verleden werden softwareapplicaties vaak gebouwd als grote monolithische systemen met hun typische problemen. Een monolithische architectuur evolueert meestal naar een 'grote modderbal' die het moeilijk maakt om dingen te onderhouden, te veranderen en de nodige bedrijfsflexibiliteit te bieden die een bedrijf nodig heeft. Tegelijkertijd biedt een dergelijke architectuur bij het schalen naar meerdere teams binnen een bedrijf niet genoeg flexibiliteit en maakt het onduidelijk welk deel van de software eigendom is van welk team. Als oplossing onderging de operationele ruimte een evolutie naar een microservices-architectuur. Met behulp van technieken uit domain driven design wordt een decompositie ontworpen op basis van bedrijfsdomeinen en in softwareservices. De uitdaging is om de juiste granulariteit te vinden om de gewenste bedrijfsflexibiliteit in een samenstelbare architectuur mogelijk te maken. Deze decompositie maakt het ook mogelijk om op te schalen naar meerdere teams. Elk team is verantwoordelijk voor een bedrijfsdomein, wat betekent dat elke microservice duidelijk eigendom is van één team.
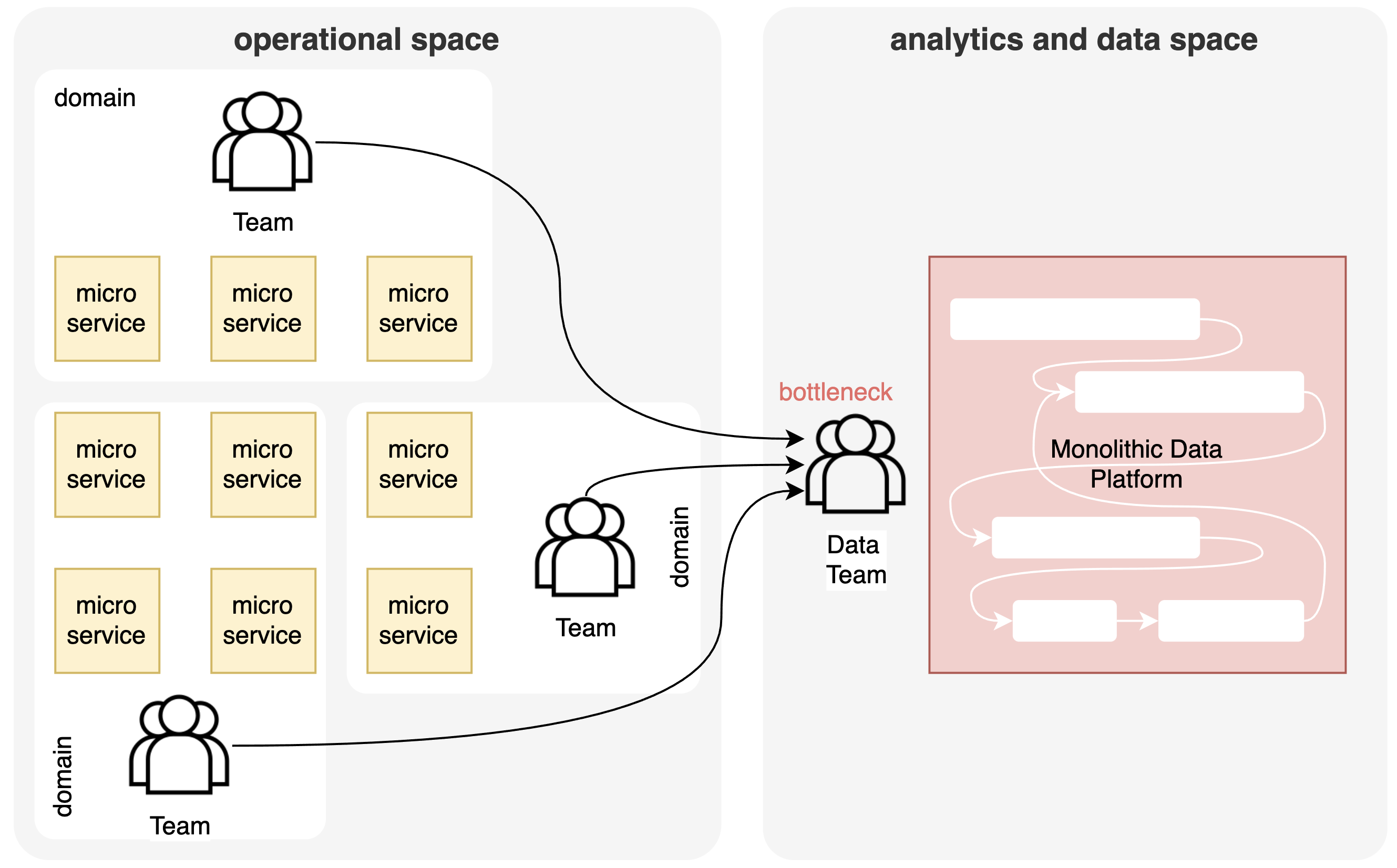
Wat we vandaag zien is een gelijkaardige trend in de analytische en dataruimte. Als we de analytische en dataruimte naast de operationele ruimte zetten, zien we opnieuw een monolithische structuur in de vorm van data lakes en data warehouses die eigendom zijn van een apart team van data engineers. Dus zelfs als er een duidelijke decompositie is in de operationele ruimte, is er nog steeds een monoliet in de analytische ruimte, wat resulteert in vergelijkbare problemen. Datapijplijnen hebben de neiging om na verloop van tijd uit te groeien tot een onbeheersbare puinhoop van aaneengeschakelde pijplijnen met lange uitvoeringstijden, hoge opslagvereisten, alles-of-niets-upgrades met wereldwijde downtime, enz. De verantwoordelijkheid om gegevens te structureren en bruikbaar te maken wordt toegewezen aan een centraal team van data engineers die een bottleneck worden wanneer de hoeveelheid datasets toeneemt en de frequentie van wijzigingen toeneemt. Dit wordt weer problematisch voor de bedrijfsflexibiliteit die een bedrijf nodig heeft.
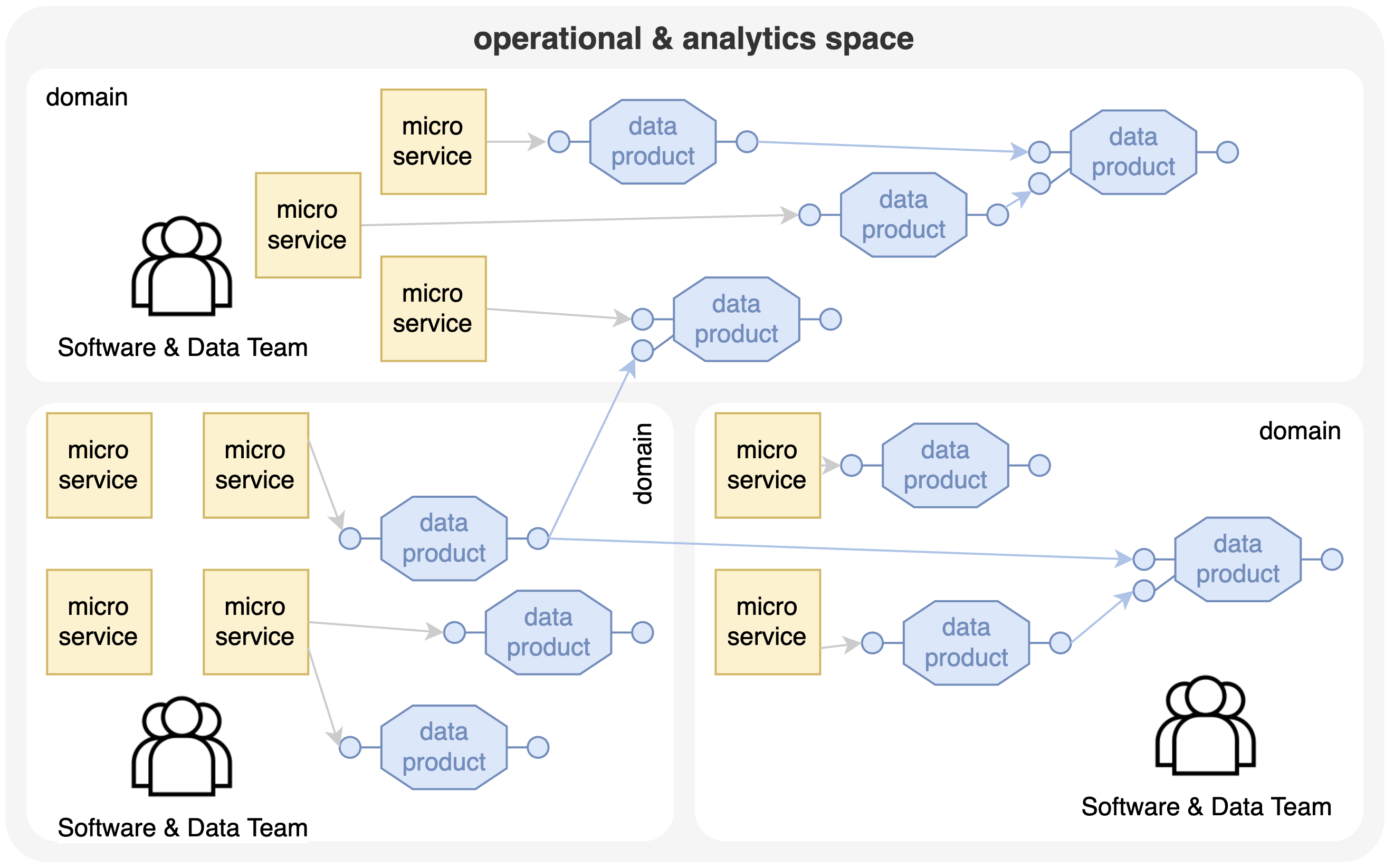
Voor de analytics & data ruimte moeten we dus ook een geschikte decompositie vinden die aansluit bij de bedrijfsdomeinen waarvoor business agility gewenst is. Deze decompositie wordt een'dataproduct' genoemd, dat data verbruikt van operationele services en andere dataproducten en data produceert met een duidelijke API of datacontract. Deze dataproducten zijn eigendom van de respectieve bedrijfsdomeinen, samen met microservices voor dat domein. Een cross-functioneel team van software engineers en data engineers is verantwoordelijk voor het bouwen, onderhouden en evolueren van een domein. Op die manier ontstaat er een netwerk van onderling verbonden dataproducten die een 'datamaas' worden genoemd. Merk op dat er nog steeds verbindingen zijn tussen services en tussen dataproducten die kunnen resulteren in geavanceerde netwerken, maar het grootste verschil is dat deze verbindingen duidelijke API's of contracten volgen die gedefinieerd zijn door componenten die het IT-landschap en het eigendom ervan duidelijk structureren.
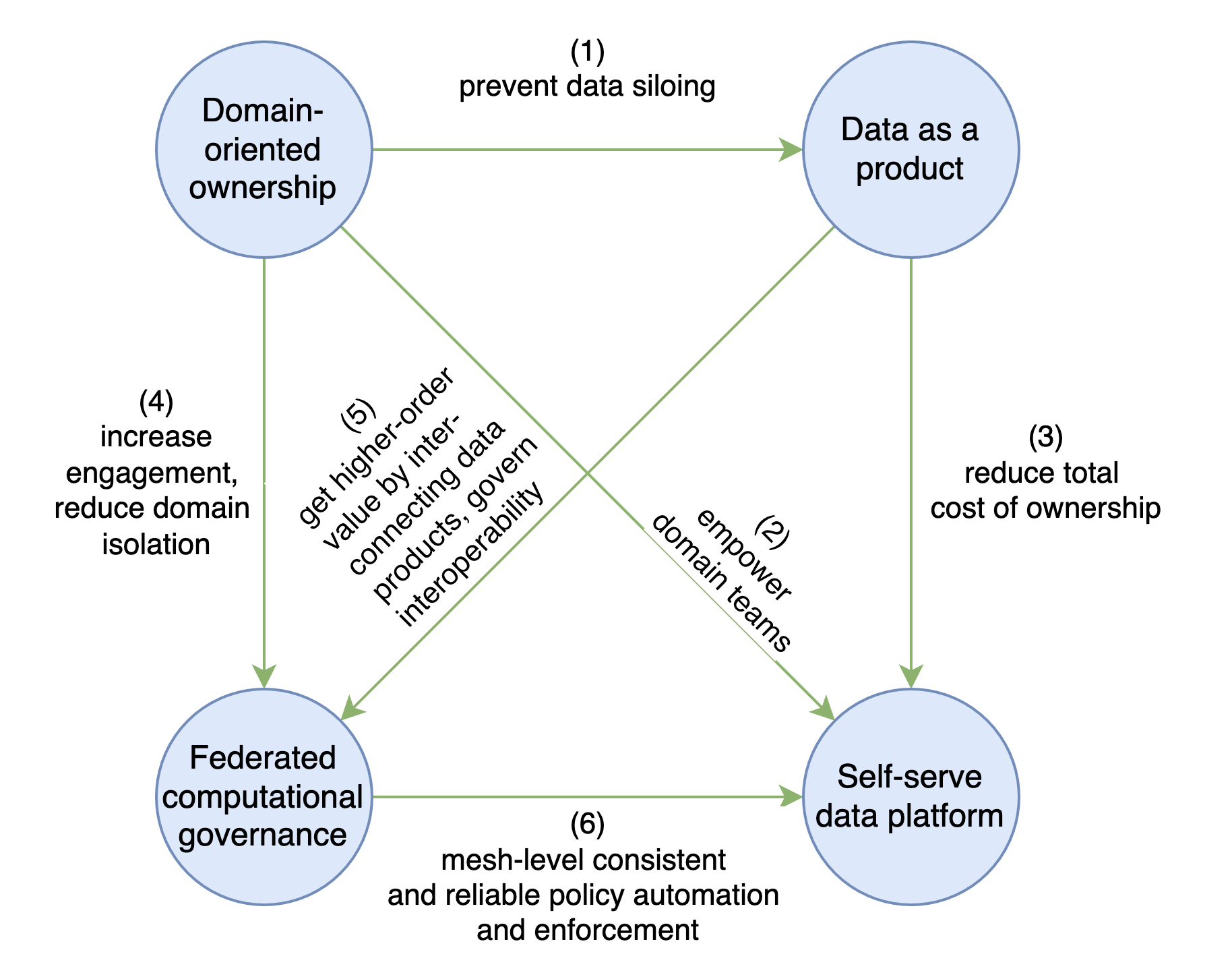
Het concept van data mesh werd geïntroduceerd door Zhamak Dehgani. Je kunt haar recent gepubliceerde boek raadplegen voor alle details. Er zijn vier principes die een data mesh-traject moet bereiken. Deze principes vullen elkaar aan en elk gaat in op nieuwe uitdagingen die kunnen voortkomen uit andere:
Volgens het boek'Building Evolutionary Architectures' is een architectuurquantum een onafhankelijk inzetbaar onderdeel met een hoge functionele samenhang, dat alle structurele elementen bevat die nodig zijn om goed te functioneren. Als zodanig is het 'gegevensproduct' in ons gegevensnetwerk een nieuw architecturaal kwantum. Het kan als volgt gevisualiseerd worden:
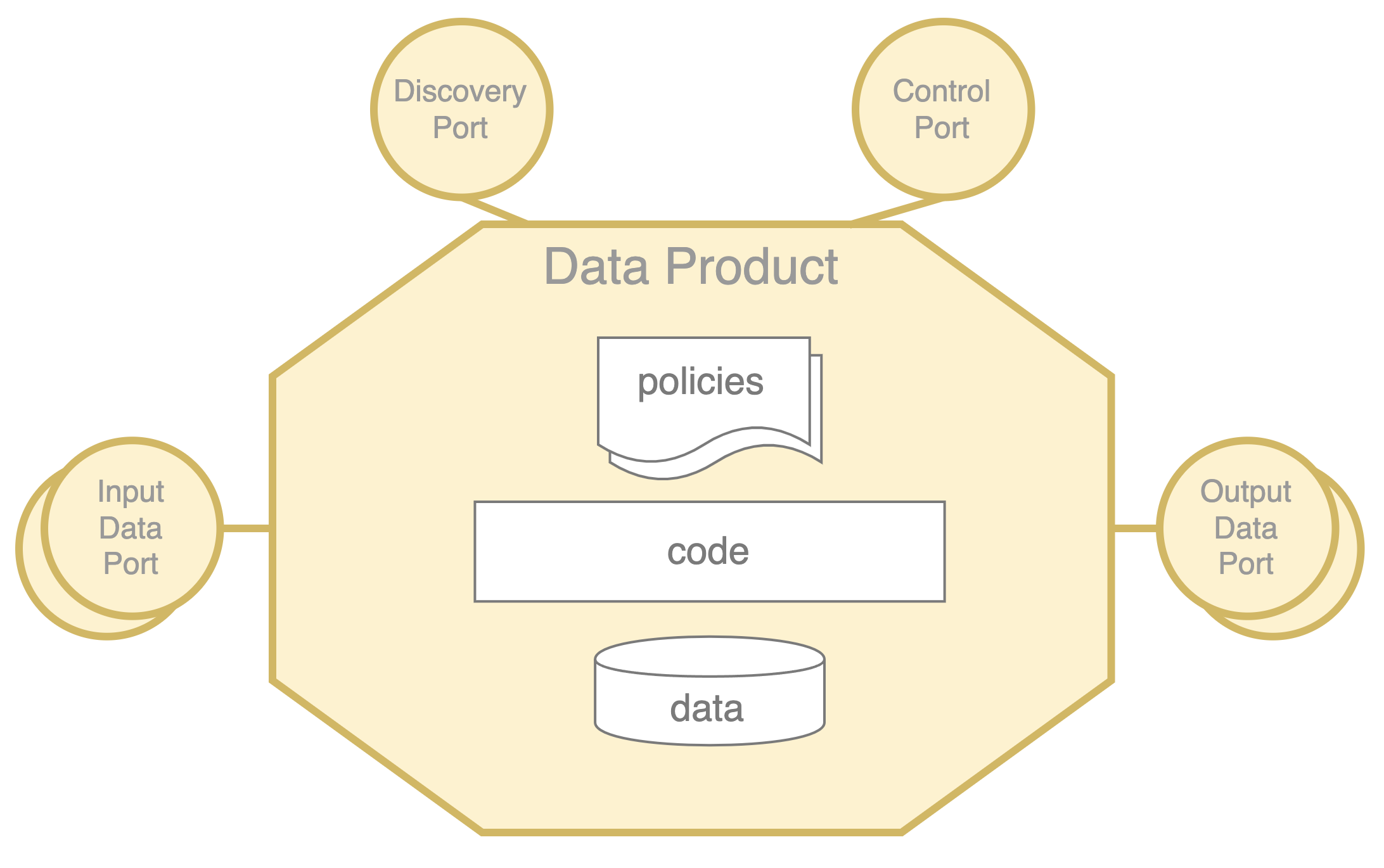
Een gegevensproduct kapselt deze structurele elementen in die nodig zijn om de gegevens als een product aan te bieden:
Aan de hand van dit gegevensproduct en de verschillende aspecten ervan kan een geschikte decompositie van een dataplatform worden beredeneerd en ontworpen.
Laten we een voorbeeld use case nemen om te illustreren hoe een netwerk van gegevensproducten al kan helpen als een nuttig ontwerpparadigma. De use case betreft het gebruik van Internet of Things (IoT)-gegevens samen met andere bedrijfsgegevens om waardevolle inzichten te bieden in welzijn en gezondheid van werknemers op de werkplek en kinderen op scholen. Voor een volledige beschrijving van de use case verwijzen we naar onze eerdere blogpost getiteld'Using IoT and digital canaries to improve health'.
In het kort gaat het om 3 operationele systemen:
Al deze systemen behoren tot het IoT-domein en zijn eigendom van één team: het IoT-team.
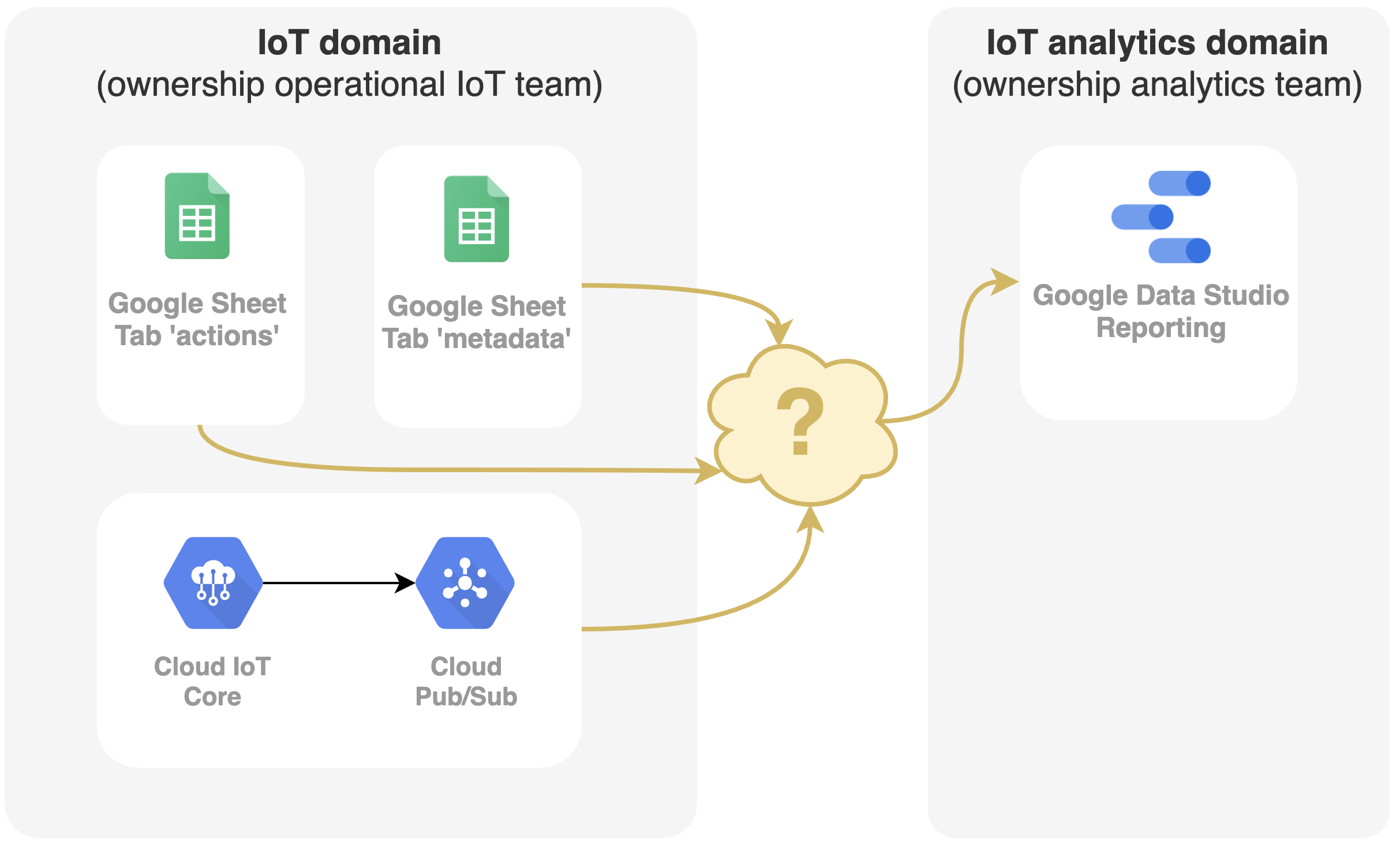
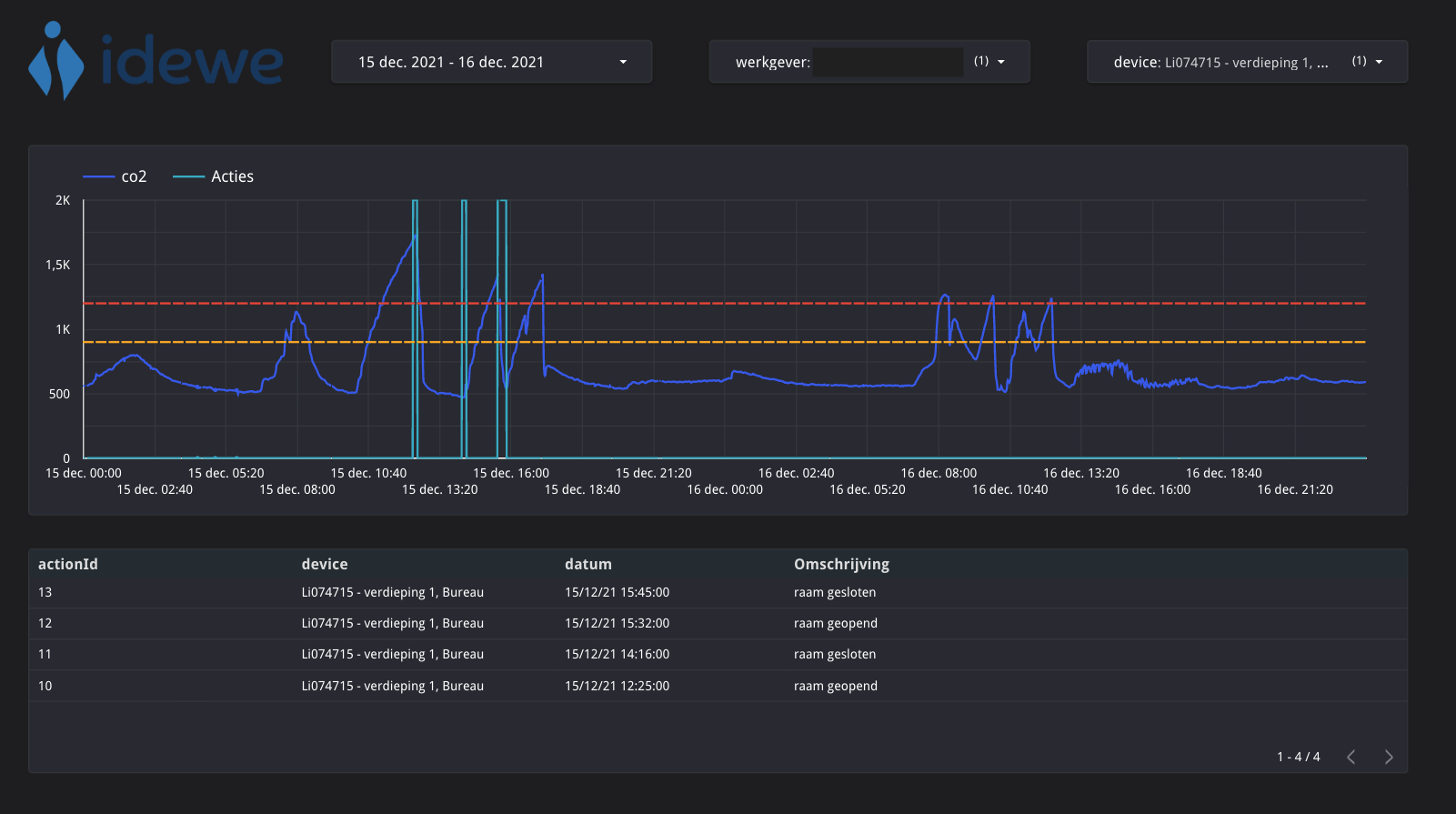
Voor analyse en rapportage wordt Google Data Studio gebruikt, dat eigendom is van het data-analyseteam. Hieronder ziet u een voorbeeld van een dashboard. In wat volgt laten we zien hoe een netwerk van dataproducten is ontstaan uit het ontwerpen van het dataplatform. De resulterende data mesh krijgt de gegevens uit de operationele systemen in het gewenste dashboard.
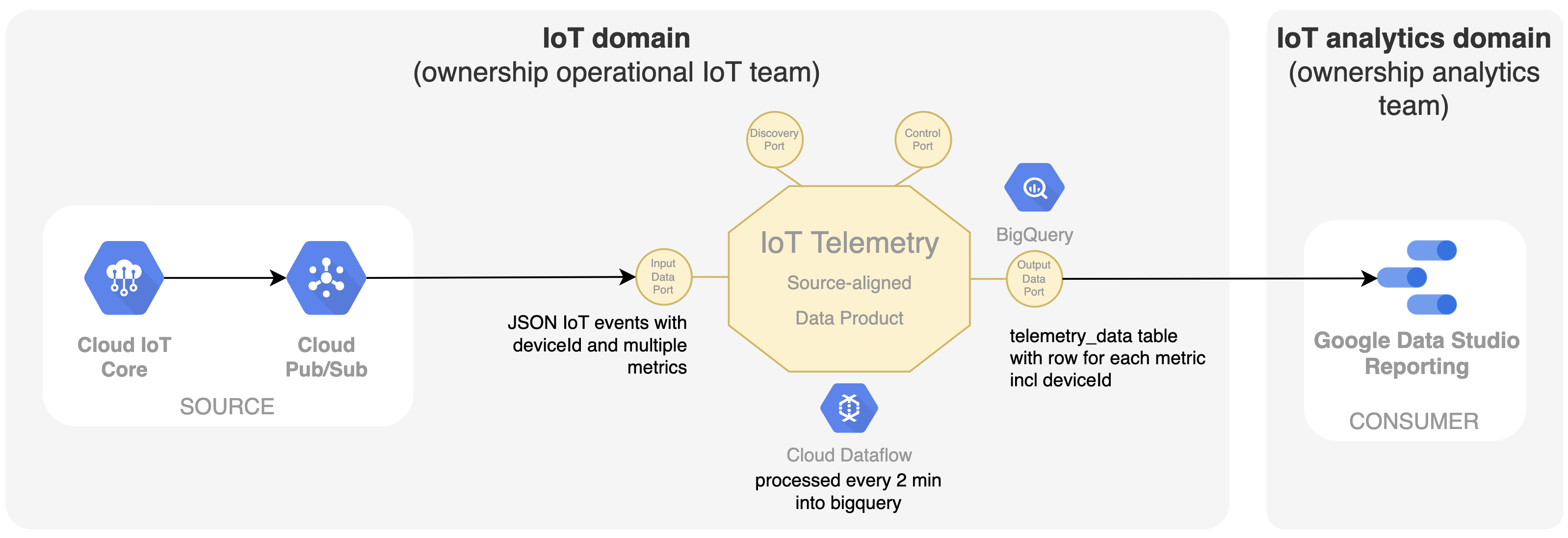
Bij IoT zijn de kerngegevens natuurlijk de telemetriegegevens die afkomstig zijn van de IoT-apparaten zelf. Het team dat eigenaar is van dit IoT-systeem is nu ook verantwoordelijk voor het delen van deze tijdreeksgegevens als gegevensproduct op het data mesh-platform. Ons eerste gegevensproduct genaamd 'IoT Telemetry' wordt geïntroduceerd, dat de IoT-gebeurtenissen met meerdere metriekgegevens uit Google Pub/Sub neemt en ze met behulp van Google Dataflow omzet in een SQL-zoekbare tabel in Google BigQuery met één rij voor elke metriek. De deviceId is hier een belangrijke identifier. Bij het gebruik van een meer centrale technologiedienst zoals BigQuery voor een decentraal eigenaarschap van een datanetwerk, is het belangrijk om de grenzen binnen BigQuery duidelijk af te bakenen. In dit geval wordt elk dataproduct een andere dataset binnen BigQuery, waardoor de teams specifieke toegangsrechten krijgen om alleen hun dataproduct te wijzigen en te vullen. In data mesh wordt dit soort dataproducten een source-aligned dataproduct genoemd, omdat ze nauw verbonden zijn met het operationele bronsysteem en hun gegevens blootstellen aan de mesh. Om deze gegevens in een grafiek weer te geven, kan het team dat verantwoordelijk is voor het dashboard in Google Data Studio rechtstreeks uit de uitvoerpoort van dit gegevensproduct lezen.
Naast de kerntelemetriegegevens worden aanvullende gegevens verzameld in eenvoudige Google-sheets. Een eerste blad verzamelt de ondernomen acties als een soort logboek. In het dashboard worden deze acties uitgezet op de grafieken die de evolutie van de telemetriegegevens weergeven. Dit toont het mogelijke effect van de actie. Het IoT-team dat in het IoT-domein werkt, is opnieuw eigenaar van deze operationele Google-sheet en is dus verantwoordelijk voor het blootleggen van de gegevens als een op de bron afgestemd gegevensproduct met de naam 'IoT Actions Taken'. Hier worden de gegevens van de Google-sheet op Google Drive omgezet in een SQL-tabel in BigQuery met behulp van een eenvoudige geplande query in een aparte tabel binnen de dataset van dit gegevensproduct.
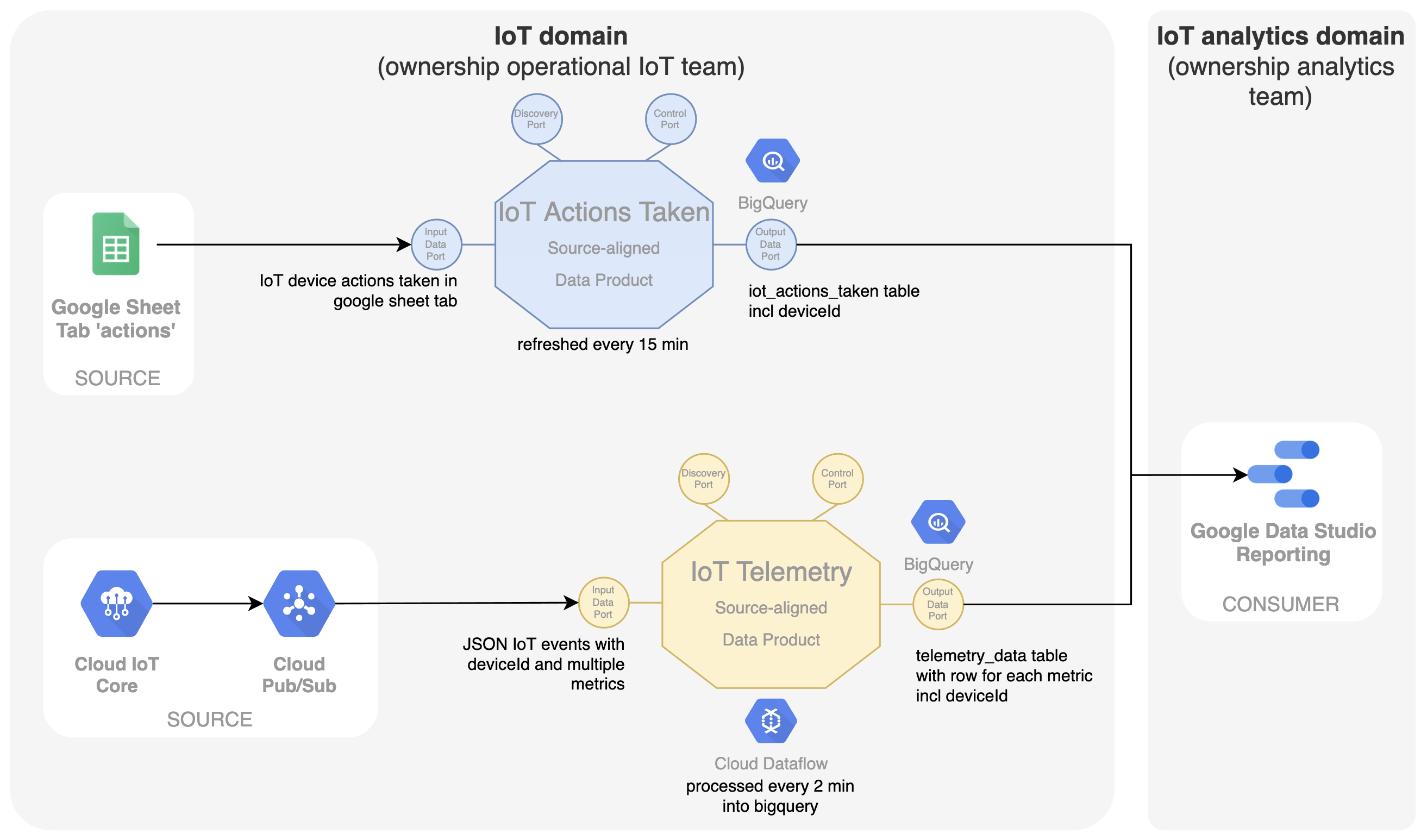
Het bovenstaande schema laat zien dat het analyseteam de uitvoerpoorten van beide gegevensproducten direct consumeert. Dit is vaak geen optimale oplossing. Voor het dashboard wordt de voorkeur gegeven aan een dataset die alle gegevens combineert die zijn geoptimaliseerd voor consumptie in dat specifieke dashboard. Hiervoor wordt een op de consument afgestemd dataproduct 'Iot Analytics' geïntroduceerd (zie hieronder). Gegevens van zowel de gegevensproducten 'IoT-telemetrie' als 'IoT-acties' zijn invoerpoorten voor dit nieuwe gegevensproduct. Op basis van de 'deviceId' worden de gegevens gecombineerd tot een bevraagbare en geoptimaliseerde SQL-weergave in BigQuery. Het eigenaarschap van dit dataproduct is ook beter afgestemd op de use case voor consumptie, namelijk het dashboard in Google Data Studio. Het analyseteam is eigenaar van het dataproduct. Dit zorgt voor meer snelheid en autonomie bij het wijzigen van het dashboard en de onderliggende geoptimaliseerde datastructuur binnen één team, wat resulteert in meer business agility.
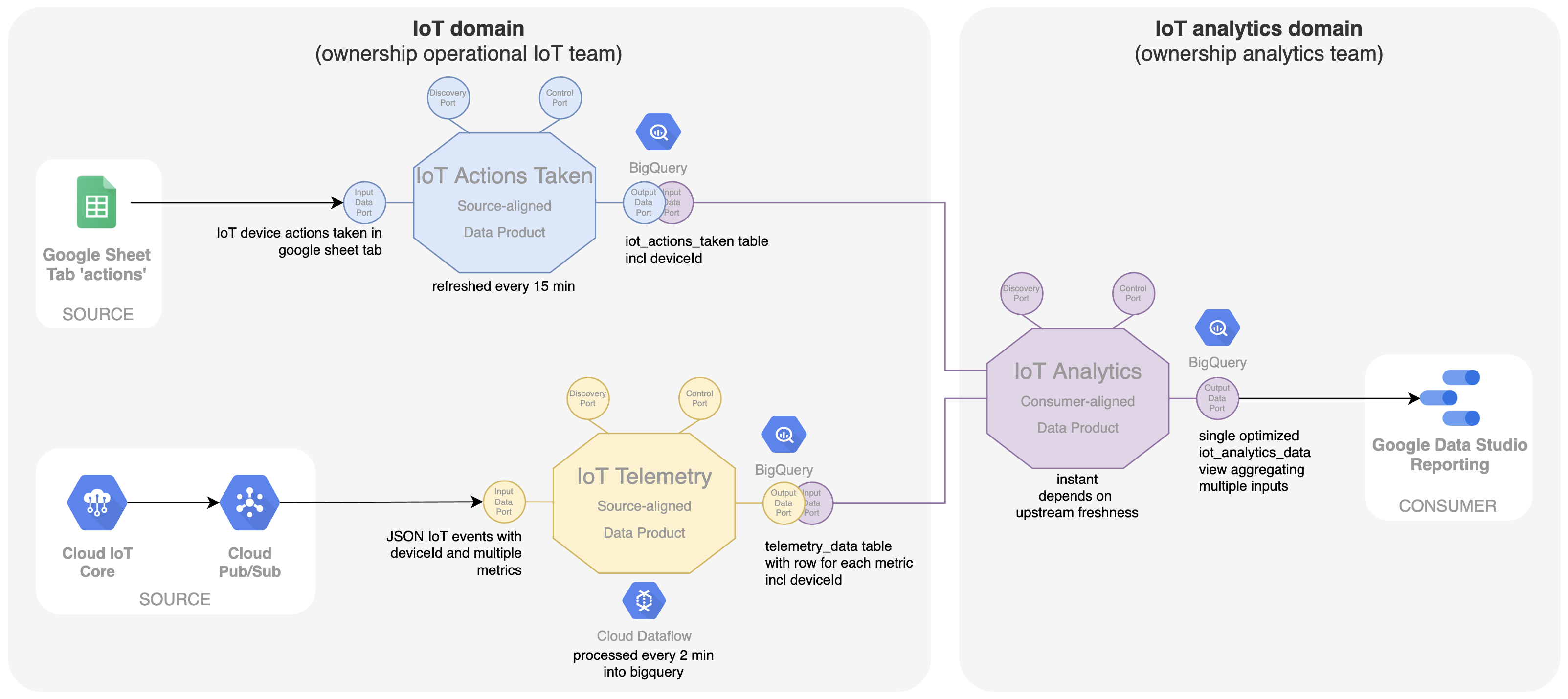
Op dezelfde manier worden door eindgebruikers aanvullende metadata over de locatie van het apparaat bijgehouden in een Google-sheet (bijv. het aantal personen dat aanwezig is in een kamer, extern co2-niveau, enz.) Deze gegevens worden ook door het IoT-team ontsloten als een afzonderlijk op de bron afgestemd gegevensproduct genaamd 'IoT Metadata' en door het analyseteam samengevoegd tot het gegevensproduct 'IoT Analytics'.
Er is ook een specifieke vereiste die inhoudt dat een enkel apparaat met een deviceId niet exclusief is voor één klant. Na verloop van tijd kan een apparaat worden verplaatst naar een andere klant. Dit betekent dat de oplossing multi-tenancy moet ondersteunen waarbij gegevens (telemetrie, acties, metadata) gescheiden worden gehouden, zodat klanten of huurders alleen de gegevens kunnen zien die relevant waren op het moment dat het apparaat zich bij hen bevond. Hiervoor is een tenantId geïntroduceerd als extra gegevenseigenschap in alle operationele systemen en alle gegevensproducten met bronvermelding. Merk op dat voor het gegevensproduct 'IoT-telemetrie' deze tenantId niet is opgenomen in de gegevens die afkomstig zijn van de apparaten. We kunnen deze tenantId alleen krijgen van het gegevensproduct 'IoT Metadata' op het moment dat een telemetriegegevenspunt binnenkomt. Het gegevensproduct 'IoT Metadata' krijgt een extra uitvoerpoort die de mapping van deviceId naar tenantId vergemakkelijkt. Deze poort is vervolgens een extra invoerpoort voor het gegevensproduct 'IoT-telemetrie' om ervoor te zorgen dat de tenantId wordt opgenomen bij elke metric die wordt geleverd in de uitvoerpoort. Het analyseteam kan dan zijn 'IoT analytics'-gegevensproduct en dashboards aanpassen om rekening te houden met deze multi-tenancy.
Het eindresultaat inclusief het metadata-gegevensproduct en multi-tenancy-ondersteuning wordt hieronder getoond.
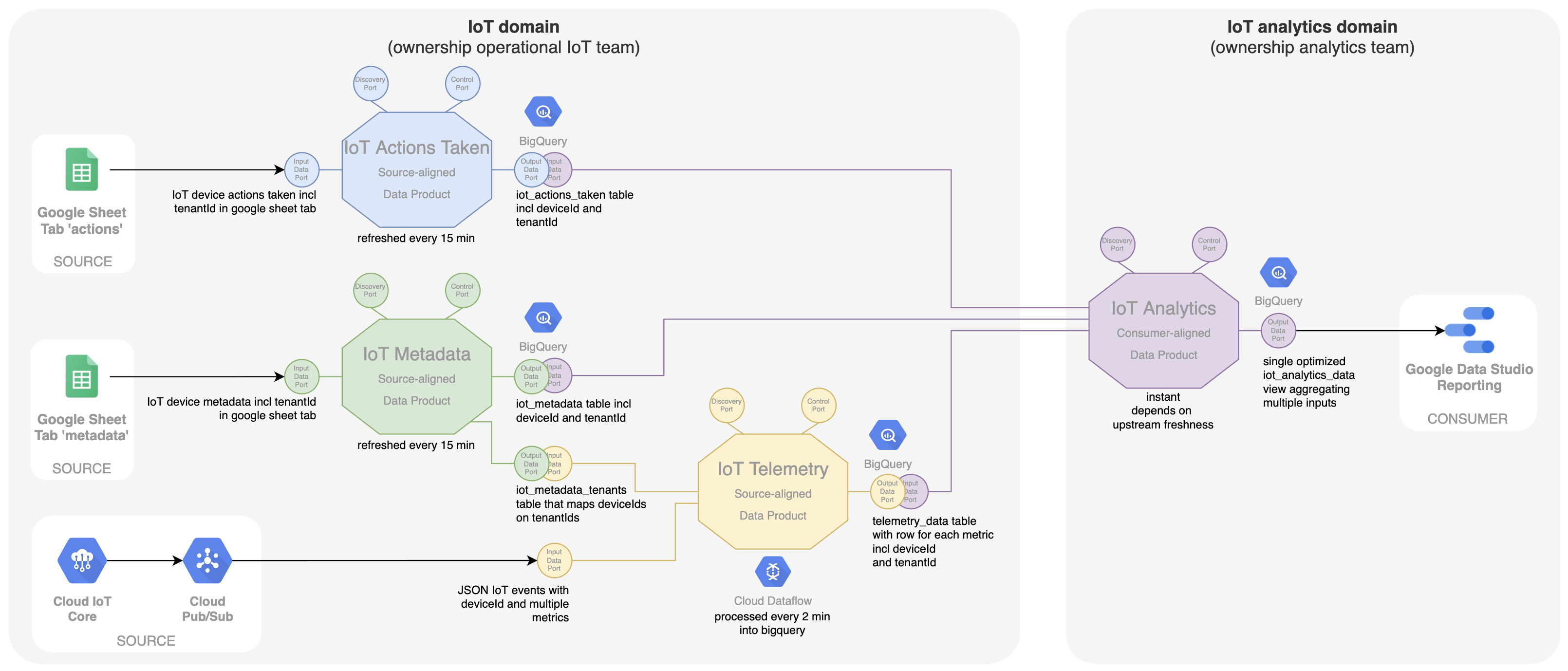
Voor elk operationeel systeem of elke dataset worden aparte gegevensproducten gemaakt. Waarom niet één gegevensproduct voor elk domein met meerdere invoerpoorten? Nou, er zijn een aantal redenen, afwegingen of ontwerp best practices die adviseren om dit niet te doen:
Terzijde: in het gegevensproduct 'IoT-metadata' zijn er eigenlijk twee soorten metadata. Er zijn metadata over waar het IoT-apparaat zich bevindt (kamer, verdieping, gebouw, ...). Maar er is ook metadata die meer betrekking heeft op de klant of huurder zelf. Waarschijnlijk is er een soort CRM-systeem dat de echte meester is van de klantgegevens en waarvan de customerId gelijk zou moeten zijn aan de tenantId in onze data mesh. Een beter domeineigenaarschap en een optimalere manier van werken zou zijn om het team dat verantwoordelijk is voor het CRM-systeem te vragen om ook een op de bron afgestemd gegevensproduct 'Klanten' te leveren met een customerId en metadata over de klant. Dit hoeft dan niet meer te worden ingevoerd in de Google-sheet van IoT-metadata. Bovendien zou het analyseteam niet alleen meer klantgegevens krijgen, maar ook nauwkeurigere gegevens omdat ze rechtstreeks van de bron komen.
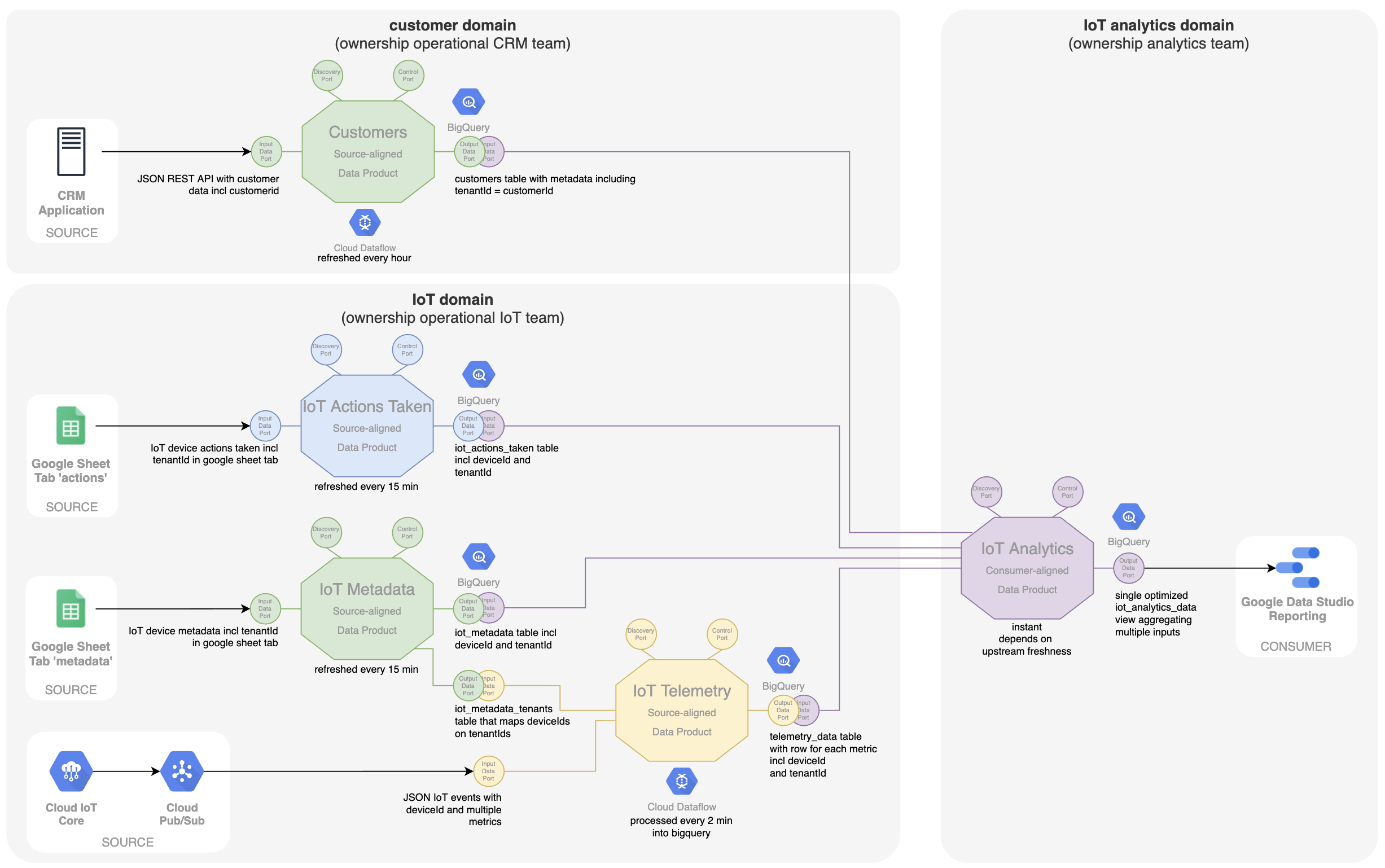
Dit proces illustreert dat denken in termen van dataproducten als bouwstenen een nuttig ontwerpparadigma is voor het ontwerpen en evolueren van een dataplatform. Het paradigma maakt duidelijk waar het eigenaarschap van bepaalde gegevens moet worden gelegd. Dit eigenaarschap impliceert dat dit eigenaarsteam verantwoordelijk is voor het onderhoud en de evolutie van het dataproduct, afhankelijk van de vereisten van de gebruikers en de evolutie van de data in het operationele bronsysteem.
In deze blogpost hebben we slechts lichtjes twee data mesh-principes aangeraakt: domeingericht eigendom en data als product. Domeingericht eigendom werd onderzocht door expliciet domeingrenzen te definiëren en elk gegevensproduct toe te wijzen aan een domeinen team. Data als product werd verkend door te denken in termen van 'dataproducten', niet alleen als bouwstenen, maar ook over hoe de bruikbaarheid van data kan worden gemaximaliseerd met het oog op consumptie.
We hebben de principes van een self-serve dataplatform en federated computation governance niet aangeroerd in de voorbeeld use case. Bij het implementeren van je data mesh-traject is er een heel spectrum te overwegen van helemaal geen selfservice en automatiseringsmogelijkheden tot een volledig geautomatiseerd selfservicedataplatform. Laten we dit wat verder illustreren.
In het bovenstaande voorbeeld lieten we het eigenaarschap op technisch niveau over aan een domeinteam. We hebben één dataproduct uitgelijnd met één broncoderepository waarvan één team eigenaar kan zijn. Dus alle transformatiecode, infrastructure-as-code, etc. is onderdeel van één code repository. Voor infrastructure-as-code gebruikten we scripts met de gcloud opdrachtregelinterface. Deze scripts zijn ook opgenomen in dezelfde coderepository en maken het mogelijk om het dataproduct te ontwikkelen, bouwen, instellen, implementeren en wijzigen.
Op infrastructuurniveau gebruikten we het self-service infrastructuurplatform van Google Cloud. De selfservice is puur gericht op infrastructuur. Dit biedt te veel flexibiliteit aan ontwikkelteams zonder uniforme begeleiding en/of controle. Dit is echter belangrijk om ervoor te zorgen dat de resulterende data mesh een samenhangende en consistente set van dataproducten is.
In die zin zou het eindresultaat hier een 'poor man's self-serve data mesh platform' genoemd kunnen worden op dat spectrum van selfservice en automatisering. Dit hoeft niet te betekenen dat we onze doelen niet bereiken. Dit kan genoeg zijn om de voordelen van een data mesh ontwerpparadigma te hebben en toch te eindigen met een goede architectuur, duidelijk eigenaarschap en zakelijke flexibiliteit om veranderingen door te voeren.
Een volgende stap in het spectrum naar een volwaardig self-service dataplatform is het verhogen van het abstractieniveau waarop een ontwikkelaar van dataproducten interageert met het self-service platform. Dan beschouw je een 'dataproduct' als de kleinste inzetbare architecturale eenheid waarrond automatisering en tooling wordt ontwikkeld om selfservice mogelijk te maken. We kunnen de pure infrastructuurcomplexiteit abstraheren door declaratieve specificatie en volledige automatisering van zaken als provisioning van opslag en API-eindpunten mogelijk te maken. Het doel is om het heel eenvoudig te maken om gegevens te delen als een product, zodat er geen reden is om je gegevens niet te delen als een team.
Een andere stap is om ook het data mesh-netwerk als geheel te beschouwen en mogelijkheden op mesh-niveau te introduceren zoals
Het doel is om het heel gemakkelijk te maken om data te vinden, selecteren, consumeren en hergebruiken in een geweldige gebruikerservaring van het dataplatform.
Hoe ver je met deze data mesh-reis gaat op het gebied van self-service dataplatformtooling en -automatisering hangt af van de complexiteit van de use cases, de schaal van de organisatie, de technische vaardigheden van dataproductontwikkelaars, de beschikbare financiering, de toekomstvisie en nog veel meer. Kortom: Het hangt ervan af, en is een onderwerp voor toekomstige blogposts. 😉
Ben jij ook bezig met je data mesh reis en wil je ideeën delen? Of denk je erover om het te doen en heb je advies nodig? Worstel je met de architectuur van je dataplatform? Aarzel niet om contact op te nemen met ons geweldige team!


Nestelde jouw bedrijf zich al in de zetels van de eerste klasse of heb je je plekje op de AI-trein nog niet gevonden? Onze AI-expert Alexander Frimout legt uit welke processen bij uitstek geschikt zijn voor je eerste AI-businesscase. En vertelt waaro
Lees verder

Voor elke externe tool die je met je AI-systeem wilt verbinden, moet je een custom integratie bouwen. Dat brengt twee grote nadelen met zich mee. Eén: het kost veel tijd. Twee: deze manier van werken is niet schaalbaar. Gelukkig kan het Model Context
Lees verder

Enlit is Europa’s grootste event rond energietransitie. Vanuit ACA Group tekenden Tom Claus and Sven Sambaer present. Ze ontmoetten klanten en partners, legden hun oor te luister en hielden hun ogen open voor de laatste trends. Een verslag over het e
Lees verderGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
