.svg?width=174&auto=compress,webp&upscale=true "aca-group (black)")
.svg?width=139&auto=compress,webp&upscale=true "aca-group (black)")

23 APR 2025
Reading time 5 min
Bregt Coenen

Didn’t make it to KubeCon this year? Read along to find out our highlights of the KubeCon / CloudNativeCon conference this year by ACA Group’s Cloud Native team!
KubeCon (Kubernetes Conference) / CloudNativeCon, organized yearly at EMAE by the Cloud Native Computing Foundation (CNCF), is a flagship conference that gathers adopters and technologists from leading open source and cloud native communities in a location. This year, approximately 5,000 physical and 10,000 virtual attendees showed up for the conference.
CNCF is the open source, vendor-neutral hub of cloud native computing, hosting projects like Kubernetes and Prometheus to make cloud native universal and sustainable.
Bringing 300+ sessions from partners, industry leaders, users and vendors on topics covering CI/CD, GitOps, Kubernetes, machine learning, observability, networking, performance, service mesh and security. It's clear there's always something interesting to hear about at KubeCon, no matter your area of interest or level of expertise!

It's clear that the Cloud Native ecosystem has grown to a mature, trend-setting and revolutionizing game-changer in the industry. All is initiated on the Kubernetes trend and a massive amount of organizations that support, use and have grown their business by building cloud native products or using them in mission-critical solutions.
What struck us during this year’s KubeCon were the following major themes:

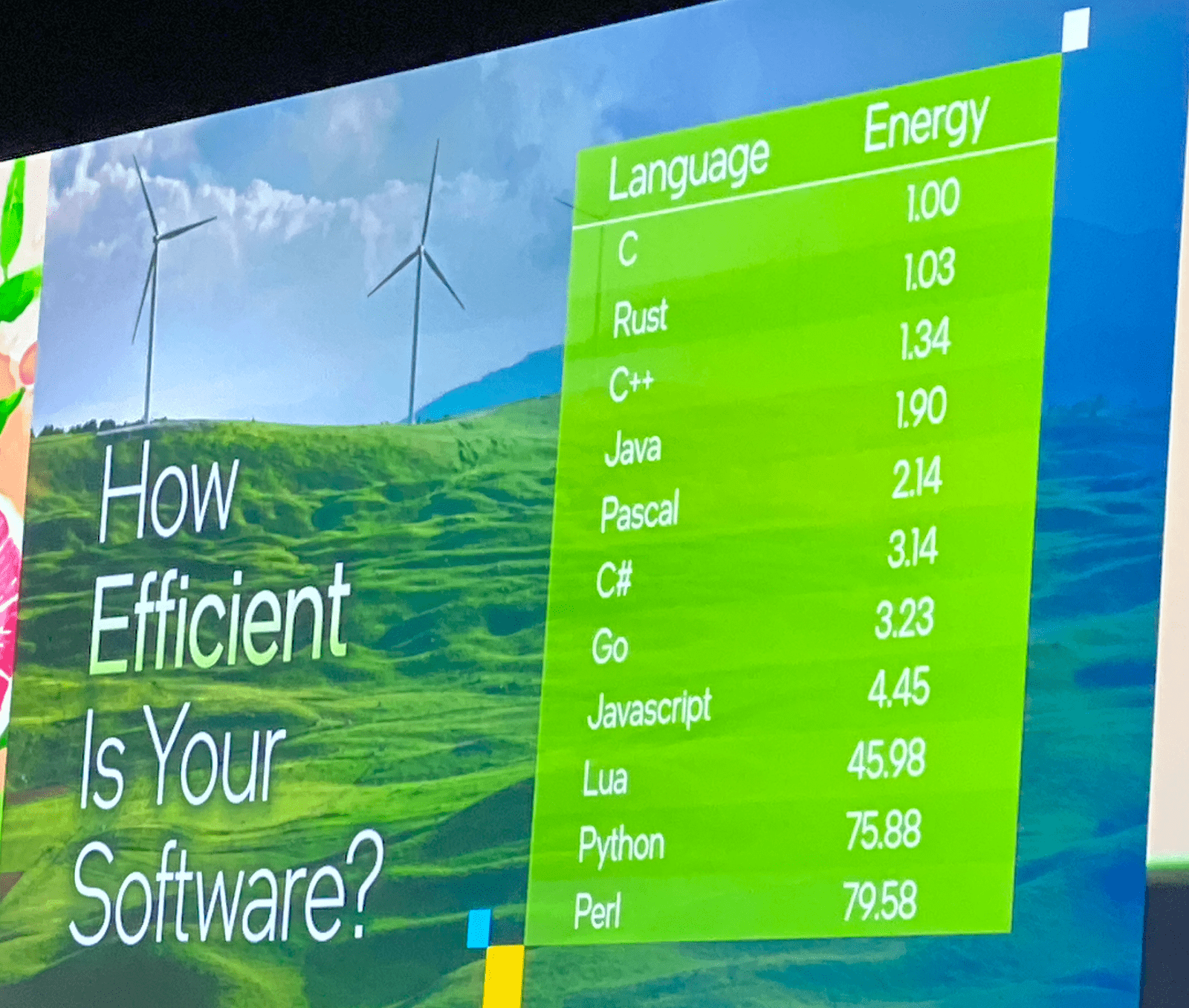
Data centers worldwide consume 8% of all generated electricity worldwide. So we'll need to reflect on
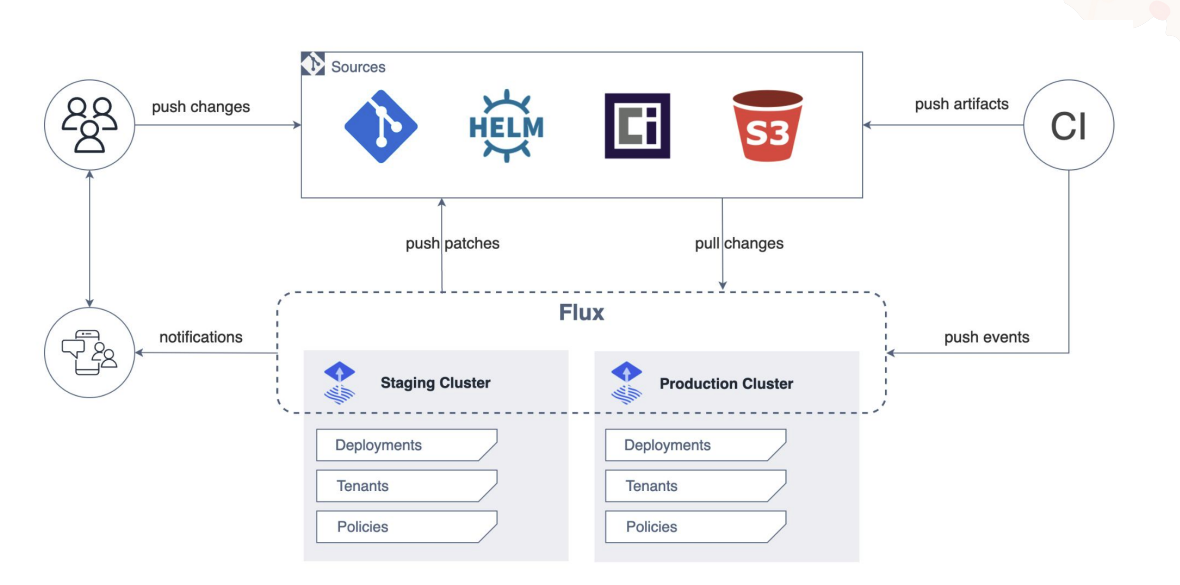
GitOps automates infrastructure updates using a Git workflow with continuous integration (CI) and continuous delivery (CI/CD). When new code is merged, the CI/CD pipeline enacts the change in the environment.
Flux is a great example of this. Flux provides GitOps for both apps and infrastructure. It supports GitRepository, HelmRepository, HelmRepository and Bucket CRD as the single source of truth.
With A/B or Canary deployments, it makes it easy to deploy new features without impacting all the users. When the deployment fails, it can easily roll back.
Checkout the KubeCon schedule page for more information!
Even though Kubernetes 1.24 was released a few weeks before the start of the event, not many talks were focused on the Kubernetes core. Most talks were focused on extending Kubernetes (using APIs, controllers, operators, …) or best practices around security, CI/CD, monitoring … for whatever will run within the Kubernetes cluster. If you're interested in the new features that Kubernetes 1.24 has to offer, you can check the official website.
Getting insights on how your application is running in your cluster is crucial, but not always practical. This is where eBPF comes into play, which is used by tools such as Pixie to collect data without any code changes.
Check out the KubeCon schedule page for more information!
Now that more and more people are using Kubernetes, a lot of workloads have been migrated. All these containers have a footprint. Memory, CPU, storage, … needs to be allocated, and they all have a cost. Cost management was a recurring topic during the talks. Using autoscaling (adding but also removing capacity) to match the required resources and identifying unused resources are part of this new movement. New services like 'kubecost' are becoming increasingly popular.
One of the most common problems in a cluster is not having enough space or resources. With the help of a Vertical Pod Autoscaler (VPA) this can be a thing of the past. A VPA will analyze and store Memory and CPU metrics/data to automatically adjust to the right CPU and memory request limits. The benefits of this approach will let you save money, avoid waste, size optimally the underlying hardware, tune resources on worker nodes and optimize placements of pods in a Kubernetes cluster.
Check out the KubeCon schedule page for more information!

We all know it's extremely important to know which application is sharing data with other applications in your cluster. Service mesh provides traffic control inside your cluster(s). You can block or permit any request that is sent or received from any application to other applications. It also provides Metrics, Specs, Split, ... information to understand the data flow.
In the talk, Service Mesh at Scale: How Xbox Cloud Gaming Secures 22k Pods with Linkerd, Chris explains why they choose Linkerd and what the benefits are of a service mesh.
Check out the KubeCon schedule page for more information!
Trampoline pods, sounds fun, right? During a talk by two security researchers from Palo Alto Networks, we learned that they aren’t all that fun. In short, these are pods that can be used to gain cluster admin privileges. To learn more about the concept and how to deal with them, we strongly recommend taking a look at the slides on the KubeCon schedule page!
Lachlan Evenson from Microsoft gave a clear explanation of Pod Security in his The Hitchhiker's Guide to Pod Security talk.
Pod Security is a built-in admission controller that evaluates Pod specifications against a predefined set of Pod Security Standards and determines whether to admit or deny the pod from running.
— Lachlan Evenson , Principal Program Manager at Microsoft
Pod Security is replacing PodSecurityPolicy starting from Kubernetes 1.23. So if you are using PodSecurityPolicy, now might be a good time to further research Pod Security and the migration path. In version 1.25, support for PodSecurityPolicy will be removed.
If you aren’t using PodSecurityPolicy or Pod Security, it is definitely time to further investigate it!
Another one of the recurring themes of this KubeCon 2022 were operators. Operators enable the extension of the Kubernetes API with operational knowledge. This is achieved by combining Kubernetes controllers and watched objects that describe the desired state. They introduce Custom Resource Definitions, custom controllers, Kubernetes or cloud resources and logging and metrics, making life easier for Dev as well as Ops.
However, during a talk by Kevin Ward from ControlPlane, we learned that there are some risks. Additionally, and more importantly, he also talked about how we can identify those risks with tools such as BadRobot and an operator thread matrix. Checkout the KubeCon schedule page for more information!
Telemetry Aware Scheduling helps you schedule your workloads based on metrics from your worker nodes. You can for example set a rule to not schedule new workloads on worker nodes with more than 90% used memory. The cluster will take this into account when scheduling a pod. Another nice feature of this tool is that it can also reschedule pods to make sure your rules are kept in line.
Checkout the KubeCon schedule page for more information!
A great way for stateless workloads to scale cost effectively is to use AWS EC2 Spot, which is spare VM capacity available at a discount. To use Spot instances effectively in a K8S cluster, you should use aws-node-termination-handler. This way, you can move your workloads off of a worker node when Spot decides to reclaim it. Another good tool is Karpenter, a tool to provision Spot instances just in time for your cluster. With these two tools, you can cost effectively host your stateless workloads!
Check out the KubeCon schedule page for more information!
Using the Horizontal Pod Autoscaler (HPA) is a great way to scale pods based on metrics such as CPU utilization, memory usage, and more.
Instead of scaling based on metrics, Kubernetes Event Driven Autoscaling (KEDA) can scale based on events (Apache Kafka, RabbitMQ, AWS SQS, …) and it can even scale to 0 unlike HPA.
Check out the KubeCon schedule page for more information!
We had a blast this year at the conference. We left with an inspired feeling that we'll no doubt translate into internal projects, apply for new customer projects and discuss with existing customers where applicable. Not only that, but we'll brief our colleagues and organize an afterglow session for those interested back home in Belgium.
If you appreciated our blog article, feel free to drop us a small message. We are always happy when the content that we publish is also of any value or interest to you. If you think we can help you or your company in adopting Cloud Native, drop me a note at peter.jans@aca-it.be.

As a final note we'd like to thank Mona for the logistics, Stijn and Ronny for this opportunity and the rest of the team who stayed behind to keep an eye on the systems of our valued customers.



CloudBrew has always been a highlight on our calendar, but the 2025 edition felt different. Perhaps it was the timing. Just the month prior, November 2025, the Azure Belgium Central region finally opened its doors. ACA has always operated from the he
Read more

Better uptime, lower costs, and avoiding vendor lock-in. These are three of the reasons why our customers opt for a multicloud strategy. Our Cloud Project Manager Roel Van Steenberghe explains what such a strategy entails and what the advantages of G
Read more

In the complex world of modern software development, companies are faced with the challenge of seamlessly integrating diverse applications developed and managed by different teams. An invaluable asset in overcoming this challenge is the Service Mesh.
Read moreGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
