.svg?width=174&auto=compress,webp&upscale=true "aca-group (black)")
.svg?width=139&auto=compress,webp&upscale=true "aca-group (black)")

Reading time 9 min
Koen Olaerts


This application however is not linked to a repository or any back-end application, which means they can’t add or edit anything on their menu on the fly. This is quite troublesome: due to the current pandemic they had to switch to a delivery system and want to be able to update their website regularly.
Having heard this little scenario, you just remembered you have a Liferay 7.2 portal running somewhere and are wondering if, using the new headless APIs, you could step in and help them.
Having reached out to the restaurant, you learned that their requirements were pretty basic:
We already wrote a blog post introducing this topic, but in a nutshell you could say these headless APIs offer a lot of Liferay’s built-in features and content up for grabs and ready to use in a custom front-end application, smart device, IoT devices, …
All of Liferay’s endpoints that are available come with a swagger documentation, which you can find here. As you can see there are a lot of different domains that Liferay has made available to us. For the purpose of this blog however I will take a quick look at the Headless Admin User and Headless Delivery.
The goal of this exercise is to meet our customer’s requirements with as little effort as possible. Naturally, that means we’ll take full advantage of the available endpoints and Liferay’s built-in features.
This overview will only contain some basic information, such as:
If you take a closer look at the Headless Admin User, you’ll notice an endpoint which fetches all user-accounts from a certain site:
If we treat the employees as users of a site, we can expose their information to the Angular application. In order to meet the full requirement, we will have to enrich our Users with 2 custom fields:
Now that we have come up with a way to meet one of the restaurant’s requirements, we have to make sure our Angular application can actually address it without being blocked. We’ll have to do a little bit of configuration in our portal:
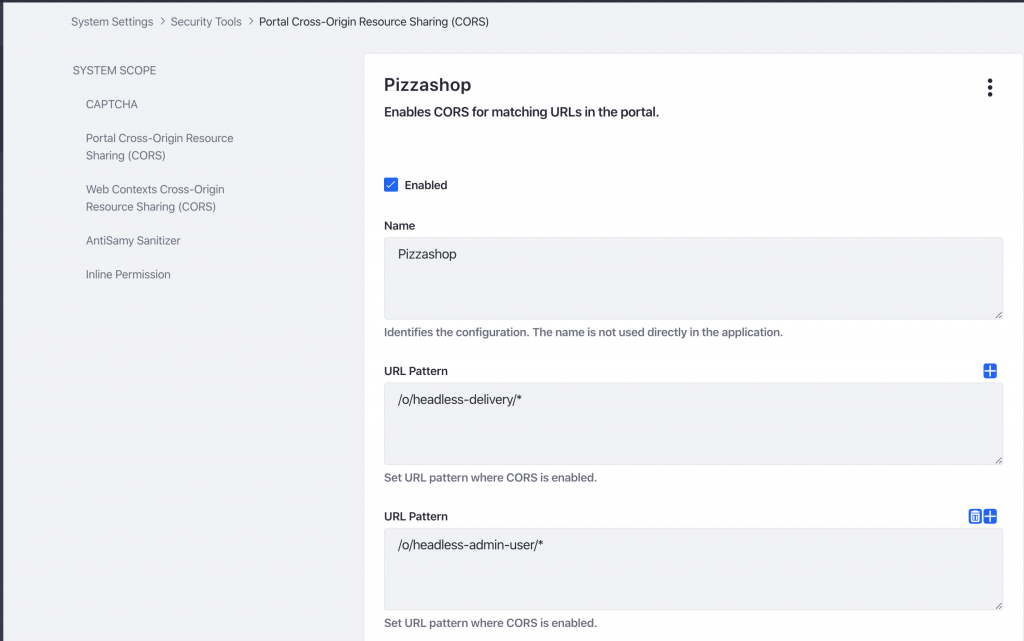
As you can see in this example, I have exposed all endpoints regarding headless-delivery and headless-admin-user. For obvious reasons, you might want to limit this to the endpoints you wish to expose.
Additional information regarding making authenticated requests can be found on Liferay’s official site.
If we fetch all users from our desired site, we get the following response for each user:
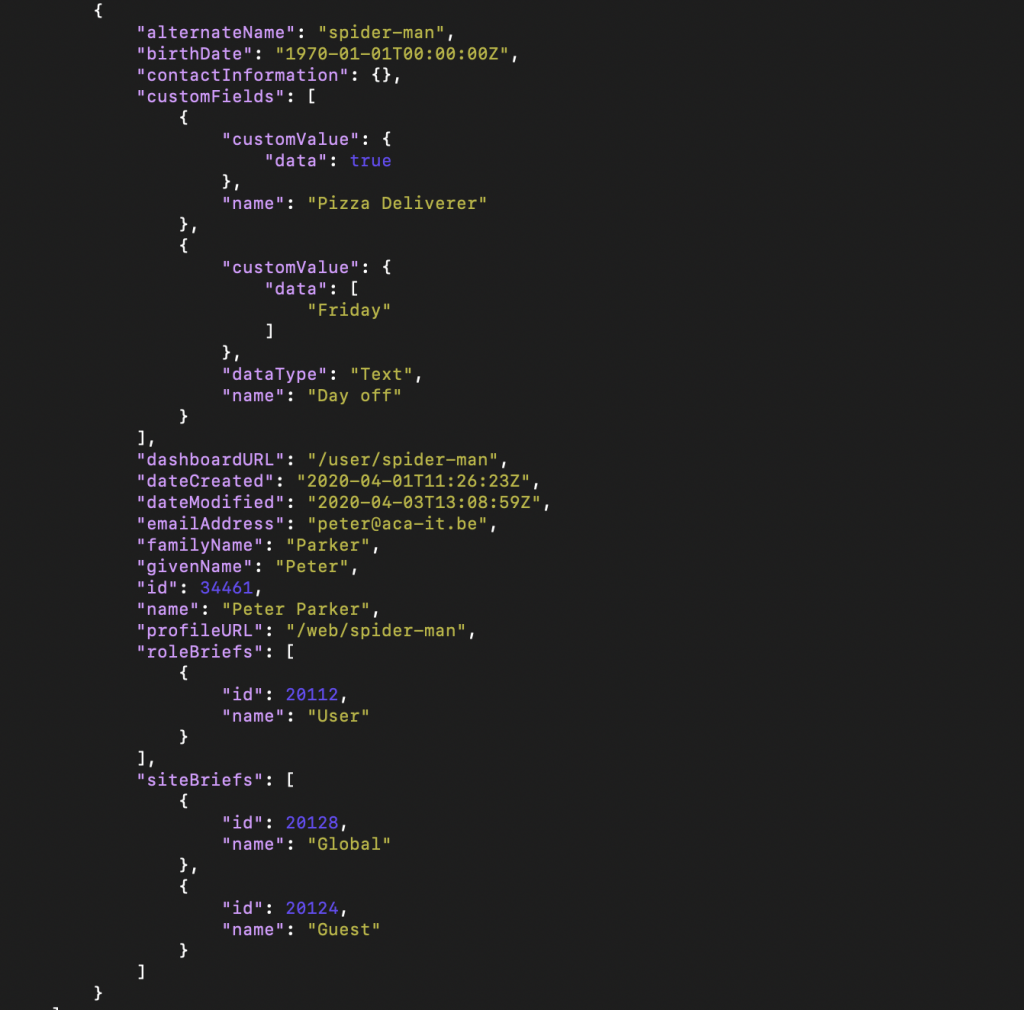
As you can see this response contains all the information we need, but also a lot of redundant information. We can limit our response to only the fields we require by adding them to our request:
That results in the following response for each user:

Using this response the Angular application can generate the required overview:

One drawback of this approach is that you’re restricted to Liferay’s domain model. You’ll have to parse the JSON-response manually or match your model to Liferay’s, which in case of these custom fields, could be a hassle.
In order to create the employee overview, we took advantage of the Liferay Users, which in this case we could map perfectly on our customer’s demand. Although Liferay offers a wide variety of endpoints that could be used to meet your customer’s demands, this won’t always be the case.
Take the pizzas on our menu for instance, they would have to contain the following information:
There is no way to map this information on an existing Liferay object. So, we will have to create an object like this ourselves. Preferably, we want to expose these objects through the headless API with as little effort as possible. Seeing as Liferay has not yet blessed us with the ability to create custom objects accompanied with their APIs, we’ll have to think outside of the box here.
If you are familiar with Liferay’s web content articles, you’ll know a web content article uses a ‘Structure’. A structure is something we can create ourselves and thus define its fields. For example we could create the following pizza structure:
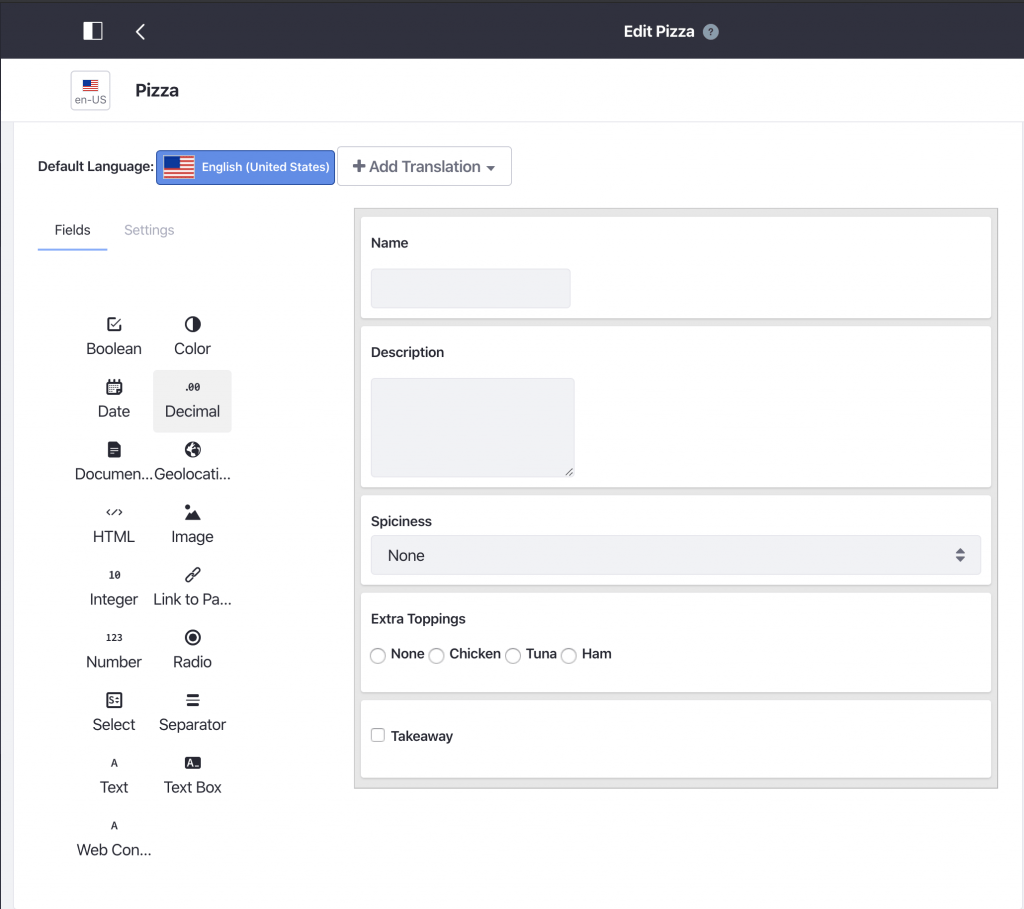
With these structures we are able to create our different pizzas in the form of web content articles. Seeing as a web content article is a built-in feature of Liferay, there is bound to be a endpoint exposing them, namely:
However, and you probably already guessed it, this also gives us a lot of redundant information. So we will have to add the relevant fields to the request:
That results in the following response:

Using this response the Angular application generates the required menu:

As you might have noticed, in the example above we are still experiencing the drawback of having to deal with the manual parsing. Ideally we would be able to define the response as well. And it so happens, we can… albeit with a workaround. Web content articles not only use structures, but also templates. And as with structures, we can define these templates as well.
Our local pizza place decided to introduce pastas to the menu. Furthermore this time we don’t want to be dealing with the manual parsing anymore. We would like to take advantage of Angular’s interfaces to do this automagically. Imagine the following interface in your Angular application:
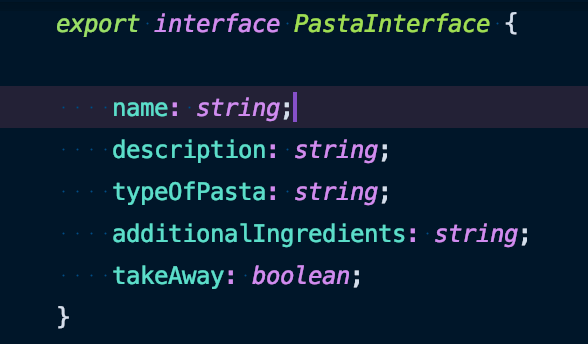
We could define a template ‘Pasta’ In Liferay that matches this interface, for example:
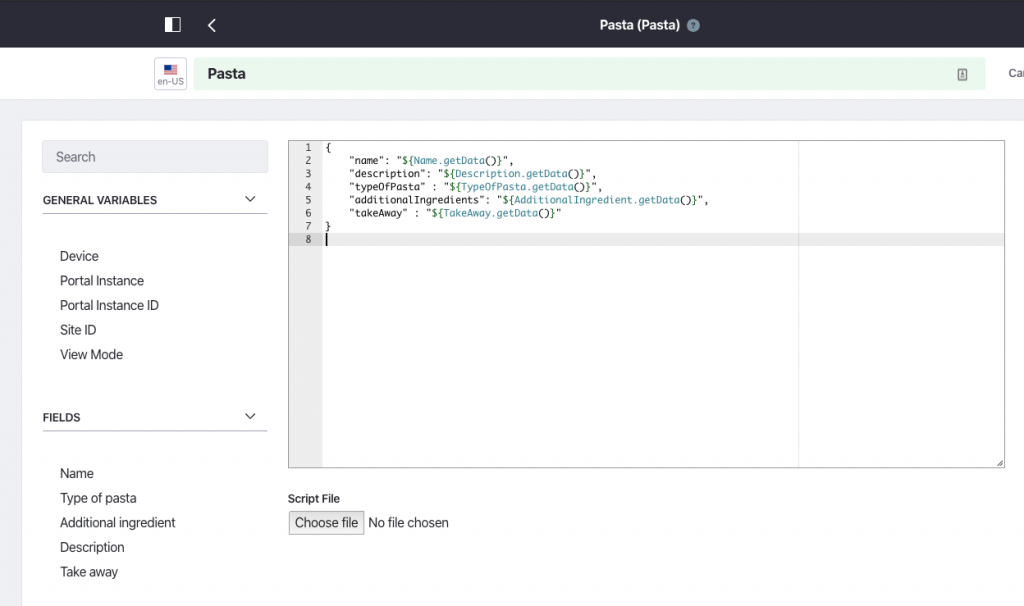
Now all we need is an endpoint that uses our template and luckily for us, it exists:
That results in the following response…
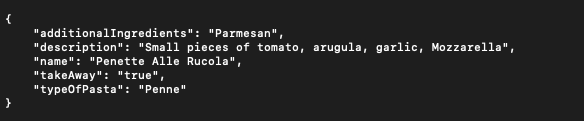
… which can be used to fill in the menu in the Angular Application:

Another great built-in feature is the ability to add a filter, sort or search to request. Meaning Liferay’s headless API will take care of this for you. Here are some examples:
Sorting by title
Searching for articles with ‘Bolognese’
Filtering by title
Leaving the fields empty will only return the pagination information, including the total count of objects found by the request.
You can find more information about filter, sort and search here. Disclaimer: Filter, sort and search can not be used when you’re using your own custom template. However there is a workaround for this as well, albeit with the drawback of having to do 1 + n requests: You can sort/filter/search your items using the default response of Liferay, which includes an URL that will lead you to your custom response:
It’s true that when you create a new structure or template, its Id is generated on the fly. However for every little problem there is a solution. For this problem in particular, there are 2 possible approaches:
Seeing as we want to do as little effort as possible, we’ll go for option number 2: content sets.
Without going too much into detail, content sets are basically what they sound like: a collection of content which can be defined by an administrator. Luckily for us we can make a collection, for example, out of all web content articles based on one or more structures. This means we can make a content set out of all our pizzas and pastas, which also lets you add filtering and ordering through the control panel.
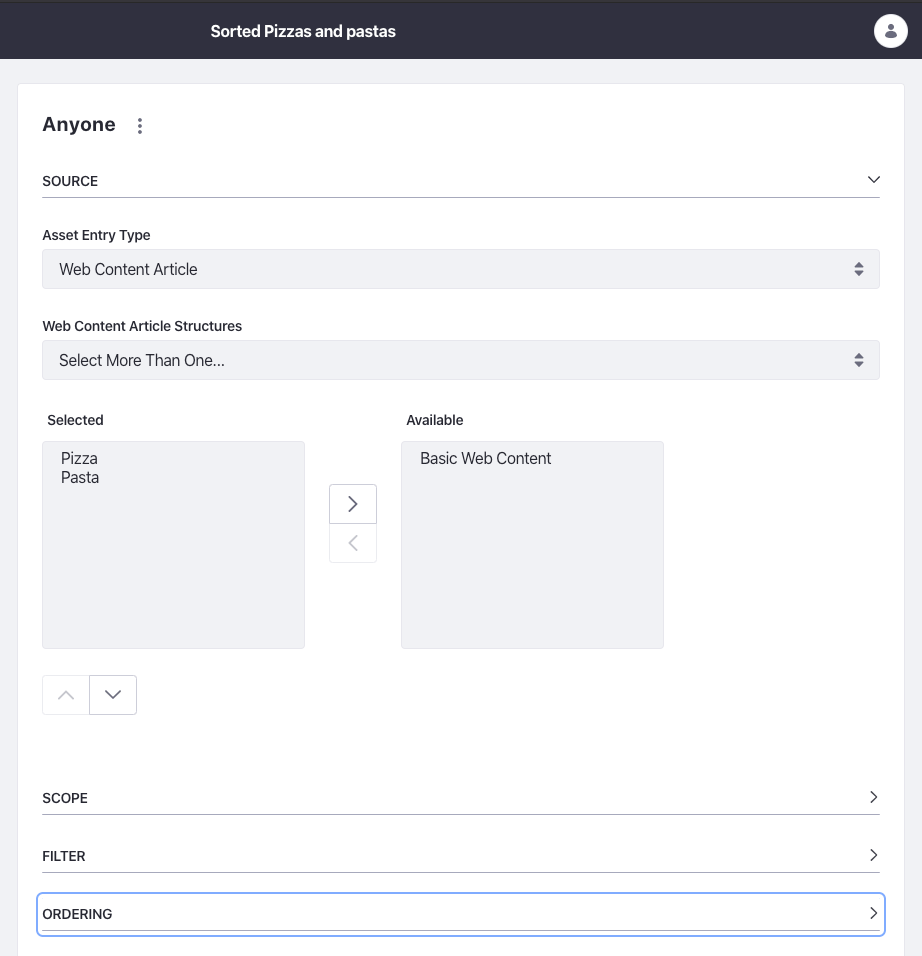
You might already feel where I’m going with this. Yes, there’s also an endpoint that allows us to get the web content articles via the content set:
The key is generated based on the name of the content set, where the spaces are replaced by a hyphen. Sorted Pizzas and Pastas would generate the key ‘sorted-pizzas-and-pastas’. More information and how to create a content set can be found here.
Without a doubt Liferay 7.2 headless APIs have the potential to enrich custom solutions with the Liferay features we’ve come to know and love. However, with the introduction of these headless APIs I had hoped we would have a built-in feature to easily create our own custom objects and the ability to expose them through dedicated APIs. That being said, being able to somewhat reproduce this feature through web content articles and their headless APIs speaks to the flexibility and extensibility of Liferay itself.
I for one look forward to what they have in store for us next!


In today's digital world, it's crucial to offer a smooth and personalized experience to your customers, no matter which channel they use to communicate with you. For this, Digital Experience Platforms (DXPs) are the solution. DXPs act as a central hu
Read more

In software development, assumptions can have a serious impact and we should always be on the look-out. In this blog post, we talk about how to deal with assumptions when developing software. Imagine…you’ve been driving to a certain place A place you
Read more

ACA does a lot of projects. In the last quarter of 2017, we did a rather small project for a customer in the financial industry. The deadline for the project was at the end of November and our customer was getting anxious near the end of September. W
Read moreGet in touch with our experts today. They are happy to help!

Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
Get in touch with our experts today. They are happy to help!
